
Llama3は、Metaが開発した無料で使える高性能LLMです。
Llama3 70Bの性能は「Gemini1.5Pro」や「Claude3 Sonnet」を上回ると言われています。
この記事では、Llama3の性能から使い方まで紹介します。

Llama3とは

Llama3は、Metaが開発したオープンソースの高性能LLMです。
実際のユースケースを想定した人間による評価においては、GPT-3.5を上回る結果を出しています。
Llama3とLlama2の主な違いは以下のとおりです。
- Llama2の7倍となる15兆以上のトークンを学習している
- 基本的な言語理解に加え、翻訳や会話のような複雑なタスクが得意
- 問題のないプロンプトに対して回答を拒否する率が下がり、応答の精度が改善
最新のLlama3.1については別記事で解説しています。


Llama3のモデル(8B、70B)
Llama3のモデルには、80億パラメータの「Llama3 8B」と700億パラメータの「Llama3 70B」があります。
それぞれに「事前学習モデル」と人間の指示に基づいた回答をするための「指示学習モデル」が用意されています。
パラメータが大きくなると性能が向上しますが、GPUメモリの使用量が増えますので、ご留意ください。
| モデルID | パラメータ | タイプ |
| meta-llama/Meta-Llama-3-8B | 80億 | 事前学習モデル |
| meta-llama/Meta-Llama-3-8B-Instruct | 80億 | 指示学習モデル |
| meta-llama/Meta-Llama-3-70B | 700億 | 事前学習モデル |
| meta-llama/Meta-Llama-3-70B-Instruct | 700億 | 指示学習モデル |
Llama3の性能
Llama3の性能について、「主要ベンチマーク」と「人間による有用性評価」の指標を見ていきます。

主要ベンチマーク
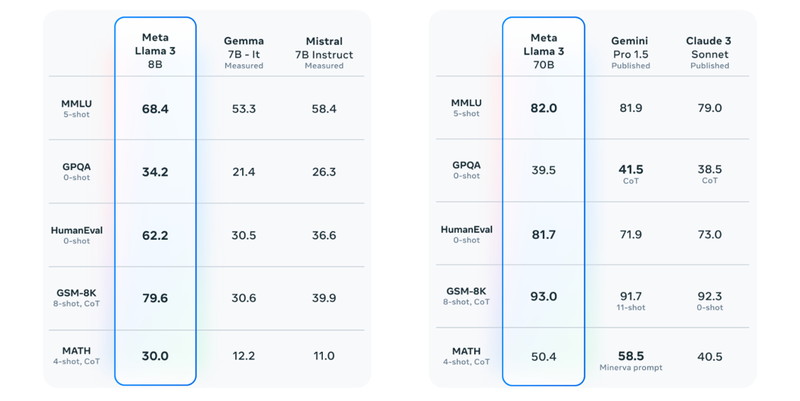
Llama 3 8Bモデルは、主要のベンチマークで、Mistral 7BやGemma 7Bなどの他のオープンモデルを上回っています。
Llama3 70Bモデルは、Gemini 1.5 ProとClaude 3よりも一部のベンチマークでハイスコアでした。
ベンチマークの種目は、質疑応答、プログラミング、推論、算数数学になります。
有用性の評価
Llama3は標準的なベンチマークのほか、実際のユースケースを想定した人間による有用性の評価を行っています。
この評価では、主要なユースケースに対応する1800個のプロンプトが含まれており、それぞれのプロンプトに対する応答結果を人間が評価しました。
- アドバイスを求める
- ブレーンストーミング
- 文章分類
- クローズドな質問回答
- コード生成
- あるキャラクターとしての振る舞い
- 文章の書き換え
- 文章要約
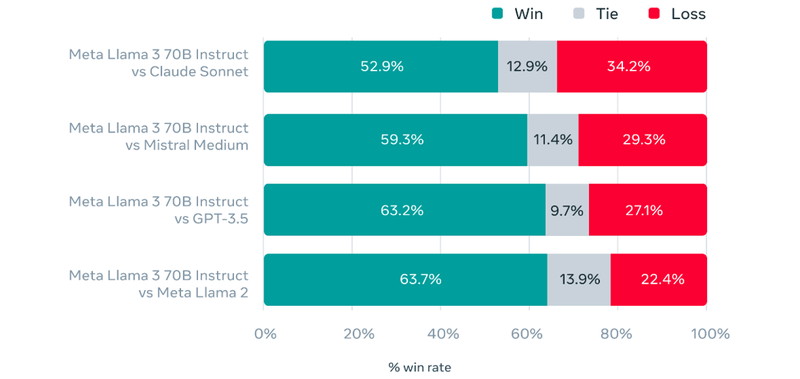
他のモデルの応答と比較して「どちらの答えの方が優れていたか」を人間が評価した結果は下図のとおりです。
Claude SonnetやMistral Medium、GPT-3.5よりも高い評価を得たほか、前のモデルであるLlama 2に比べても高いスコアを出しています。
Llama3の日本語能力は?

Llama3の学習データの95%が英語になり、日本語の学習率は高くありません。
現状は英語での利用が推奨されていますが、今後のバージョンアップにて、英語以外の言語も対応していくと言われています。
Llama3に日本語を追加学習したLLMについては別記事にて詳しく解説しています。


Llama3.1に日本語を追加学習したLLMについては別記事にて詳しく解説しています。

Llama3の商用利用・ライセンス

Llama3は「META LLAMA 3 COMMUNITY LICENSE」のもとで提供されています。
商用利用:ソフトウェアやコードを商用利用することが許可されています。
改変:ソフトウェアやコードを自由に修正したり改変したりすることができます。
配布:修正したり変更したりしたソフトウェアを自由に配布することができます。
著作権表示:再配布時に、著作権の表示や契約書コピーの提供などが必要になります。
特許利用:特許利用に関する明示的な規定はありません。
詳細は「META LLAMA 3 COMMUNITY LICENSE」のページをご確認ください。
Llama3のモデル申請

Llama3のモデルの利用申請をします。
HuggingFaceにログインして、Llama3のモデルページにアクセスします。

Llama3のモデルページで、「Expand to review and access」ボタンを押して展開します。
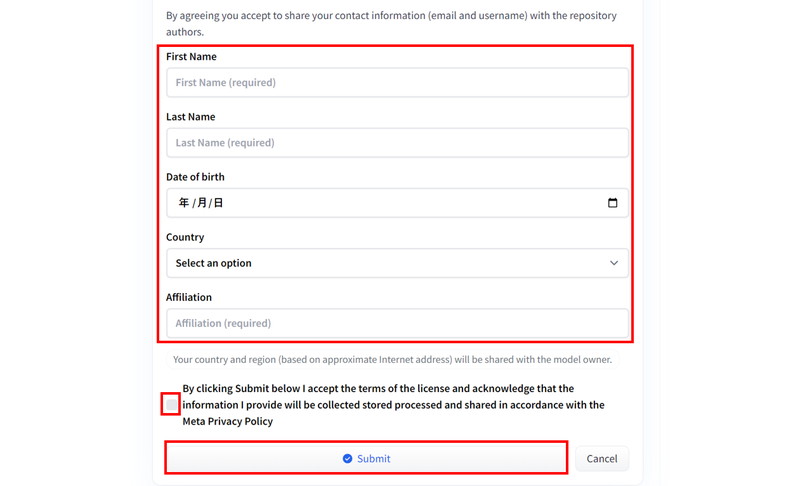
ページの下のほうに進むと入力フォームがありますので、
「ユーザー情報」を入力し、「ライセンス条項の同意文」にチェックを入れて、「Submit」ボタンをクリックします。
「Your request to access this repo has been successfully submitted…」の表示がされている間は、モデル利用申請の承認待ちのステータスになります。
「Access granted」というタイトルで承認通知メールが届いたら、モデルの利用申請が完了です。
Llama3の使い方

ここからLlama3を使ったテキスト生成(推論)について解説していきます。
Ollamaを使ってChatGPTのような画面でテキスト生成(推論)をする方法は、別の記事で解説しています。

Llama3のファインチューニングの使い方については、別の記事で解説しています。



実行環境
この記事で用意した実行環境は以下のとおりです。
- GPU:NVIDIA A100 80GB
- GPUメモリ(VRAM):80GB
- OS :Ubuntu 22.04
- Docker
Dockerで環境構築
Dockerを使用してLlama3の環境構築をします
Dockerの使い方は以下の記事をご覧ください。

コンテナにインストールするパッケージは以下のとおりです。
CUDA、PyTorch、Transformersはバージョン依存関係によるエラーが起きやすいので、動作検証済のバージョン指定してインストールしています。
- CUDA:12.1
- Python:3.10
- PyTorch:2.2.2
- transformers:4.41.2
- bitsandbytes
Ubuntuのコマンドラインで、Dockerfileを作成します。
mkdir llama3_inference
cd llama3_inference
nano DockerfileDockerfileに以下の記述を貼り付けます。
# ベースイメージ(CUDA)の指定
FROM nvidia/cuda:12.1.0-cudnn8-devel-ubuntu22.04
# 必要なパッケージをインストール
RUN apt-get update && apt-get install -y python3-pip python3-venv git nano
# 作業ディレクトリを設定
WORKDIR /app
# アプリケーションコードをコピー
COPY . /app
# Python仮想環境の作成
RUN python3 -m venv /app/.venv
# 仮想環境をアクティベートするコマンドを.bashrcに追加
RUN echo "source /app/.venv/bin/activate" >> /root/.bashrc
# JupyterLabのインストール
RUN /app/.venv/bin/pip install Jupyter jupyterlab
# PyTorchのインストール
RUN /app/.venv/bin/pip install torch==2.2.2 torchvision==0.17.2 torchaudio==2.2.2 --index-url https://download.pytorch.org/whl/cu121
# Transformer関連のインストール
RUN /app/.venv/bin/pip install transformers==4.41.2 bitsandbytes
# コンテナの起動時にbashを実行
CMD ["/bin/bash"]docker-compose.ymlでDockerコンテナの設定をします。
docker-compose.ymlのYAMLファイルを作成して開きます。
nano docker-compose.yml以下のコードをコピーして、YAMLファイルに貼り付けます。
services:
llama3_inference:
build:
context: .
dockerfile: Dockerfile
image: llama3_inference
runtime: nvidia
container_name: llama3_inference
ports:
- "8888:8888"
volumes:
- .:/app/llama3_inference
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: 1
capabilities: [gpu]
command: >
bash -c '/app/.venv/bin/jupyter lab --ip="*" --port=8888 --NotebookApp.token="" --NotebookApp.password="" --no-browser --allow-root'Dockerfileからビルドしてコンテナを起動します。
docker compose up
Dockerの起動後にブラウザの検索窓に”localhost:8888″を入力すると、Jupyter Labをブラウザで表示できます。
localhost:8888Llama3の実装
Dockerコンテナで起動したJupyter Lab上でLlama3の実装をします。
Jupyter Labのコードセルに次のコマンドを実行して、ライブラリをインポートします。
import transformers
import torch
from torch import cuda,bfloat16Llama3のモデルをダウンロードして読み込みます。
token = "******************************"
model_id = "meta-llama/Meta-Llama-3-70B-Instruct"
pipeline = transformers.pipeline(
"text-generation",
model=model_id,
token=token,
model_kwargs={"torch_dtype": torch.bfloat16,
"quantization_config": {"load_in_4bit": True},
"low_cpu_mem_usage": True,
},
device_map="auto",
)token = “******************************”
Hugging Faceのアクセストークンを定義。******に実際のトークン値が入ります。
model_id = “meta-llama/Meta-Llama-3-70B-Instruct”
Llama3のモデルタイプを指定します。
transformers.pipeline
テキスト生成タスクのためのTransformerのパイプラインを設定しています。
“quantization_config”: {“load_in_4bit”: True}
量子化の有効化。量子化しない場合は、コメントアウトしてください。
low_cpu_mem_usage
Trueは、モデル読み込み時のCPUメモリの使用量を削減します。
Hugging Faceのアクセストークンの発行方法は、別の記事で解説しています。

モデルを読み込む際にGPUメモリを消費しますので、余裕を持ったGPUメモリをご用意ください。
| モデルID | パラメータ | タイプ | GPUメモリの使用量 | 量子化の有無 |
| meta-llama/Meta-Llama-3-8B | 80億 | 事前学習モデル | 16.4GB | なし |
| meta-llama/Meta-Llama-3-8B-Instruct | 80億 | 指示学習モデル | 16.4GB | なし |
| meta-llama/Meta-Llama-3-70B | 700億 | 事前学習モデル | 43.5GB | あり |
| meta-llama/Meta-Llama-3-70B-Instruct | 700億 | 指示学習モデル | 43.5GB | あり |
Llama3でテキスト生成

Llama3を使って、英語での質問応答、日本語での質問応答、コード生成を試してみます。
英語での質問応答
What role does CUDA play(CUDAのの役割は何?)というプロンプトを実行してみます。
messages = [
{"role": "system", "content": "You are an excellent chatbot"},
{"role": "user", "content":"What role does CUDA play?"},
]
prompt = pipeline.tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
terminators = [
pipeline.tokenizer.eos_token_id,
pipeline.tokenizer.convert_tokens_to_ids("<|eot_id|>")
]
outputs = pipeline(
prompt,
max_new_tokens=256,
eos_token_id=terminators,
do_sample=True,
temperature=0.6,
top_p=0.9,
)
print(outputs[0]["generated_text"][len(prompt):])messages
モデルへのプロンプトを定義しています。「What role does CUDA play?」がプロンプトです。
pipeline.tokenizer.apply_chat_template
Llama3のチャットテンプレートを適用してプロンプトを作成しています。モデルによって異なります。
terminators
生成されたテキストの終了を示すトークンを定義しています。これがないと延々とテキストが生成されます。
pipeline
Transformerのパイプラインを実行してテキストを生成します。出力するトークン数や生成確率などを指定できます。
What role does CUDA play?
CUDA is a parallel computing platform and programming model developed by NVIDIA that allows developers to use the power of graphics processing units (GPUs) to perform general-purpose computing. In other words, CUDA enables developers to harness the processing power of NVIDIA GPUs to accelerate a wide range of applications, from scientific simulations to machine learning and deep learning.
Here are some key roles that CUDA plays:
1.Parallel Computing: CUDA enables developers to write programs that can execute on the GPU, which has thousands of cores. This allows for massive parallelism, making it possible to perform complex computations much faster than on a CPU.
以下省略
————————————————————————–
(翻訳)
CUDAは、NVIDIAによって開発された並列コンピューティングプラットフォームおよびプログラミングモデルであり、開発者がグラフィックス処理ユニット(GPU)の力を利用して汎用計算を実行できるようにします。言い換えれば、CUDAは開発者がNVIDIA GPUの処理能力を活用して、科学シミュレーションから機械学習や深層学習に至るまで、幅広いアプリケーションを高速化できるようにします。
以下にCUDAの主な役割を示します:
並列コンピューティング: CUDAは、数千個のコアを持つGPU上で実行できるプログラムを開発者が書くことを可能にします。これにより、大規模な並列処理が可能になり、複雑な計算をCPUよりもはるかに速く実行できます。
以下省略
日本語での質問応答
「食前酒とは何ですか」というプロンプトを実行してみます。
messages = [
{"role": "system", "content": "あなたは日本語で回答するアシスタントです"},
{"role": "user", "content":"食前酒とは何ですか"},
]
prompt = pipeline.tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
terminators = [
pipeline.tokenizer.eos_token_id,
pipeline.tokenizer.convert_tokens_to_ids("<|eot_id|>")
]
outputs = pipeline(
prompt,
max_new_tokens=256,
eos_token_id=terminators,
do_sample=True,
temperature=0.6,
top_p=0.9,
)
print(outputs[0]["generated_text"][len(prompt):])食前酒とは何ですか
食前酒(しょくぜんじゅう)は、食事の前に飲む酒を指します。日本の食文化では、食前酒を飲むことが一般的で、食事の始まりを祝うために飲むことが多いです。
食前酒は、主に日本酒やワイン、ビールなどを使用し、食事の準備や、味や匂いを覚醒させるために飲まれることが多いです。また、食前酒は、食事の流れを整える役割も果たすと考えられます。
日本では、食前酒を飲む習慣は古くからあり、特に日本酒の場合、食前酒を飲むことが日本の食文化の一部となっています。
コード生成
「torch.nn.Moduleの使い方を教えて下さい」というプロンプトで質問を投げてみます。
messages = [
{"role": "system", "content": "あなたは日本語で回答するアシスタントです"},
{"role": "user", "content":"torch.nn.Moduleの使い方を教えて下さい。"},
]
prompt = pipeline.tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
terminators = [
pipeline.tokenizer.eos_token_id,
pipeline.tokenizer.convert_tokens_to_ids("<|eot_id|>")
]
outputs = pipeline(
prompt,
max_new_tokens=256,
eos_token_id=terminators,
do_sample=True,
temperature=0.6,
top_p=0.9,
)
print(outputs[0]["generated_text"][len(prompt):])torch.nn.Moduleの使い方を教えて下さい。
モデルの応答
Torch.nn.Moduleは、PyTorchのニューラルネットワークモデルの基本的なクラスです。以下は、Moduleの基本的な使い方を説明します。
1. Moduleの定義
----------------
Moduleは、`torch.nn.Module`クラスを継承して定義します。例えば、以下は、簡単なニューラルネットワークを定義するためのModuleの例です。
```python
import torch
import torch.nn as nn
class MyModel(nn.Module):
def __init__(self):
super(MyModel, self).__init__()
self.fc1 = nn.Linear(784, 128) # input layer (28x28 images) -> hidden layer (128 units)
self.fc2 = nn.Linear(128, 10) # hidden layer (128 units) -> output layer (10 units)
def forward(self, x):
x = torch.relu(self.fc1(x)) # activation function for hidden layer
x = self.fc2(x)
return x
```
この例では、`MyModel`クラスは、`nn.Module`クラスを継承しています。`__init__`メソッドでは、ニュOllamaを使ってChatGPTのような画面でテキスト生成(推論)をする方法は、別の記事で解説しています。
Llama3のファインチューニングの使い方については、別の記事で解説しています。
生成AI・LLMのコストでお困りなら
GPUのスペック不足で生成AIの開発が思うように進まないことはありませんか?
そんなときには、高性能なGPUをリーズナブルな価格で使えるGPUクラウドサービスがおすすめです!

GPUSOROBANは、生成AI・LLM向けの高速GPUを業界最安級の料金で使用することができます。
インターネット環境さえあれば、クラウド環境のGPUサーバーをすぐに利用可能です。
大規模な設備投資の必要がなく、煩雑なサーバー管理からも解放されます。







