
DeepSeek-R1は、中国のAI企業DeepSeekが開発した最新の大規模言語モデル(LLM)です。
DeepSeek-R1は、無料で使えるオープンソースでありながら、OpenAIのo1モデルに匹敵するパフォーマンスを持つと評価されています。
この記事では、DeepSeek-R1の各モデルの性能、必要なGPUメモリ、商用利用について解説します。
ざっくり言うと
- DeepSeek-R1のモデルごとの違いや、必要なGPUメモリが分かる
- DeepSeek-R1のモデルごとの性能、ベンチマークを紹介
- DeepSeek-R1の安全性と商用利用について解説

DeepSeek-R1とは?

DeepSeek-R1は、中国のAI企業DeepSeekが開発した最新の大規模言語モデル(LLM)です。
DeepSeek-R1は、無料で使えるオープンソースでありながら、OpenAIのo1モデルに匹敵するパフォーマンスを持つと評価されています。
o1同等のモデルが無料で提供され、商用利用も自由に行えるため、開発者にとって大きなメリットになります。

DeepSeek-R1の何がスゴイ?

高い推論能力
DeepSeek-R1の革新性は、従来のように大量の教師ありデータ(SFT)を用いた学習を行わず、純粋な強化学習(RL)だけで学習することで、モデルは自己検証や内省を通じて、長い思考連鎖(Chain of Thought, CoT)の生成といった高度な推論能力を獲得しました。さらに大規模な教師ありデータセットが不要なメリットがあります。
強化学習(RL)のアルゴリズムとしてGRPO(Group Relative Policy Optimization)を採用し、従来のように絶対的なスコアで評価するのではなく、複数の選択肢を比較しながら「より優れたもの」を相対的に判断する手法を報酬の基準として学習することで、計算コストを大幅に削減しています。
推論能力と読みやすい文章の両立
DeepSeek-R1の学習プロセスは、強化学習(RL)と教師ありファインチューニング(SFT)を交互に適用する多段階のパイプラインで構成されています。
まず、ベースモデルにRLを適用して初期の推論能力を強化し(DeepSeek-R1-Zero)、その後SFTでコールドスタートの不安定さを解消しながら可読性を向上させます。
さらに、論理的思考の強化を目的としたRL、汎用性向上のためのSFT、最終的な有用性と安全性の最適化を目的としたRLを適用し、精度・適応力・安全性を兼ね備えたモデルへと仕上げます。
第0段階(RL:ベースモデルに対する強化学習)
まず、ベースモデルに対して強化学習(RL)を適用し、初期の推論能力を強化します。このモデルがDeepSeek-R1-Zeroにあたります。このステージでは、学習が不安定で時間がかかるコールドスタート問題や、言語の混在や可読性の低さなどの課題が含まれます。
第1段階(SFT:CoTプロセスの学習)
少量の高品質なデータセットを用いて教師あり微調整(SFT)を行い、強化学習(RL)に伴う初期の不安定さを解消します。このデータには思考プロセス(Chain of Thought, CoT)を含め、可読性の向上を目的としたフォーマットを採用しています。また、言語混在や出力の品質低下といった課題を防ぐため、適切な構成とフィルタリングを実施します。強化学習(RL)の初期段階での不安定さを解消し、モデルの論理的思考能力を高めることができます。
第2段階(RL:推論能力の強化)
数学・コーディング・科学など、論理的思考が求められるタスクに特化した強化学習(RL)を適用します。
この段階では、DeepSeek-R1-Zeroで確認された言語混在の問題を軽減するため、「言語一貫性報酬」を追加し、出力の統一性と可読性を確保します。
第3段階(SFT:汎用性的な言語能力の向上)
教師あり微調整(SFT)を再度実施し、ライティング・Q&A・翻訳など、幅広いタスクに対応できる汎用性を強化します。
第4段階(RL:倫理的バイアスの調整)
最後に、モデルの論理的思考能力をさらに洗練するとともに、有用性と無害性を向上させるため、総合的な強化学習(RL)を適用します。このステージでは、数学・コーディング・論理的思考の精度向上に加え、人間の嗜好に適応する応答の最適化を行い、安全性を確保します。
蒸留モデルによってGPUの計算コストを削減
DeepSeek-R1では、蒸留を用いて、大規模モデルの推論パターンをQwen2.5やLlama3などの小型モデルへ効果的に転移しています。
その結果、GPUの計算コストを抑えながらも、高い推論能力を持つ軽量なモデルが実現されました。
これにより、処理能力に制約のあるローカル環境でも、DeepSeek-R1を十分に活用できるようになっています。
DeepSeek-R1のモデルの種類と必要なGPUメモリ(VRAM)

DeepSeek-R1は、パラメータ数に応じて複数のバリエーションがあります。
モデルのパラメータ数が増加すると、性能が向上しますが、その分必要なGPUメモリ(VRAM)も増加します。
量子化を適用することで、精度を若干落としながらもGPUメモリを節約することが可能です。
| モデルID | パラメータ数 | GPUメモリ(VRAM) ※量子化なし | GPUメモリ(VRAM) ※4bit量子化あり | GPUメモリ(VRAM) ※Ollamaモデル | 参考GPUスペック |
|---|---|---|---|---|---|
| deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B | 1.5B(15億) | 4GB | 1GB | 0.75GB | NVIDIA A4000 16GB x1枚 |
| deepseek-ai/DeepSeek-R1-Distill-Qwen-7B | 7B(70億) | 18GB | 4.5 GB | 3.5GB | NVIDIA A100 40GB x1枚 |
| deepseek-ai/DeepSeek-R1-Distill-Llama-8B | 8B(80億) | 21GB | 5 GB | 4GB | NVIDIA A100 40GB x1枚 |
| deepseek-ai/DeepSeek-R1-Distill-Qwen-14B | 14B(140億) | 36GB | 9 GB | 7GB | NVIDIA A100 80GB x1枚 |
| deepseek-ai/DeepSeek-R1-Distill-Qwen-32B | 32B(320億) | 82GB | 21GB | 16GB | NVIDIA H200 141GB x1枚 |
| deepseek-ai/DeepSeek-R1-Distill-Llama-70B | 70B(700億) | 181GB | 46 GB | 35GB | NVIDIA H200 141GB x2枚 |
| deepseek-ai/DeepSeek-R1 | 617B(6710億) | 1543GB | 436 GB | 1342GB | NVIDIA H200 141GB x12枚 |
| deepseek-ai/DeepSeek-R1-Zero | 617B(6710億) | 1543GB | 436 GB | 1342GB | NVIDIA H200 141GB x12枚 |
モデルはHuggingFaceから無料でダウンロードできます!

DeepSeek-R1をローカル環境で使用する方法は?

DeepSeek-R1の日本語モデルとは?

DeepSeekのアプリの使い方は?

DeepSeek-R1の性能・ベンチマーク

DeepSeek-R1(671B)とOpenAI o1のベンチマーク比較
DeepSeek-R1は、数学的推論や論理的推論、コーディングに特化しており、OpenAIのo1シリーズに相当する位置づけになります。
DeepSeek-R1(671B)は、OpenAIo1と同等のパフォーマンスを発揮しつつ、特に推論能力や数学分野においてはo1を上回っています。
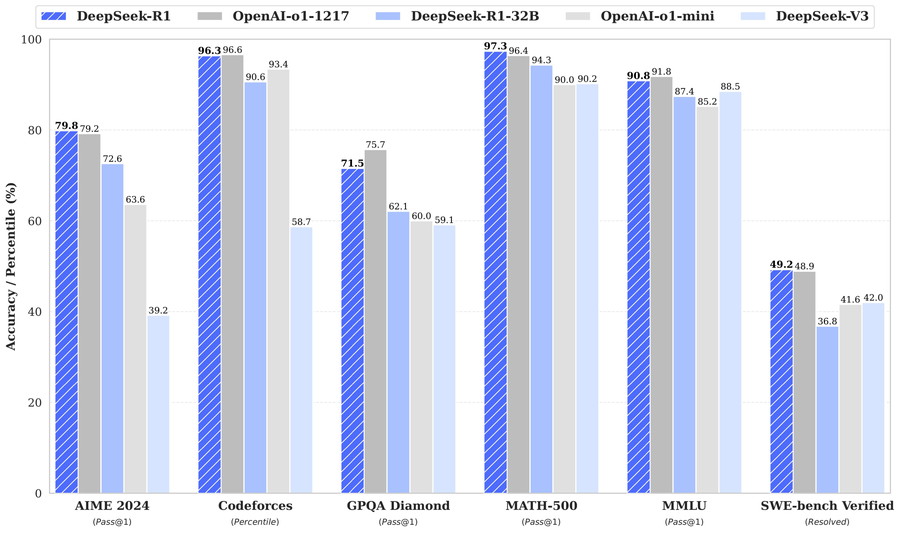
| Category | Benchmark (Metric) | Claude-3.5-Sonnet-1022 | GPT-4o 0513 | DeepSeek V3 | OpenAI o1-mini | OpenAI o1-1217 | DeepSeek R1(671B) |
|---|---|---|---|---|---|---|---|
| 知識・推論能力(英語) | MMLU (Pass@1) | 88.3 | 87.2 | 88.5 | 85.2 | 91.8 | 90.8 |
| MMLU-Redux (EM) | 88.9 | 88.0 | 89.1 | 86.7 | – | 92.9 | |
| MMLU-Pro (EM) | 78.0 | 72.6 | 75.9 | 80.3 | – | 84.0 | |
| DROP (3-shot F1) | 88.3 | 83.7 | 91.6 | 83.9 | 90.2 | 92.2 | |
| IF-Eval (Prompt Strict) | 86.5 | 84.3 | 86.1 | 84.8 | – | 83.3 | |
| GPQA-Diamond (Pass@1) | 65.0 | 49.9 | 59.1 | 60.0 | 75.7 | 71.5 | |
| SimpleQA (Correct) | 28.4 | 38.2 | 24.9 | 7.0 | 47.0 | 30.1 | |
| FRAMES (Acc.) | 72.5 | 80.5 | 73.3 | 76.9 | – | 82.5 | |
| AlpacaEval2.0 (LC-winrate) | 52.0 | 51.1 | 70.0 | 57.8 | – | 87.6 | |
| ArenaHard (GPT-4-1106) | 85.2 | 80.4 | 85.5 | 92.0 | – | 92.3 | |
| プログラミング能力 | LiveCodeBench (Pass@1-COT) | 33.8 | 34.2 | – | 53.8 | 63.4 | 65.9 |
| Codeforces (Percentile) | 20.3 | 23.6 | 58.7 | 93.4 | 96.6 | 96.3 | |
| Codeforces (Rating) | 717 | 759 | 1134 | 1820 | 2061 | 2029 | |
| SWE Verified (Resolved) | 50.8 | 38.8 | 42.0 | 41.6 | 48.9 | 49.2 | |
| Aider-Polyglot (Acc.) | 45.3 | 16.0 | 49.6 | 32.9 | 61.7 | 53.3 | |
| 数学能力 | AIME 2024 (Pass@1) | 16.0 | 9.3 | 39.2 | 63.6 | 79.2 | 79.8 |
| MATH-500 (Pass@1) | 78.3 | 74.6 | 90.2 | 90.0 | 96.4 | 97.3 | |
| CNMO 2024 (Pass@1) | 13.1 | 10.8 | 43.2 | 67.6 | – | 78.8 |
AIME 2024(数学的推論)
DeepSeek-R1は79.8%を記録し、OpenAI o1-1217の79.2%をわずかに上回っています。
MATH-500(高校数学問題)
DeepSeek-R1は97.3%と非常に高いスコアを達成し、OpenAI o1-1217の96.4%を上回りました。
Codeforces(プログラミング能力)
DeepSeek-R1は96.3%であり、OpenAI o1-1217が96.6%よりも若干下回りました。
SWE-bench Verified(ソフトウェアエンジニアリングタスク)
DeepSeek-R1が49.2%で、OpenAI o1-1217の48.9%を若干上回る結果でした。
GPQA Diamond(一般知識)
OpenAI o1-1217が75.7%と優勢に対し、DeepSeek-R1は71.5%と少し遅れを取っています。
MMLU(多分野知識の理解)
DeepSeek-R1の90.8%であり、OpenAI o1-1217は91.8%をわずかに下回る結果となりました。
DeepSeek-R1 蒸留モデルのベンチマーク
DeepSeek-R1は、QwenベースとLlamaベースの2種類の蒸留モデルを提供しており、Qwenベースはバランスの取れた性能を持ち、Llamaベースは数学的推論やプログラミング能力に強みがあります。それぞれのモデルの特徴を詳しく見ていきます。
| Model | AIME 2024 pass@1 | AIME 2024 cons@64 | MATH-500 pass@1 | GPQA Diamond pass@1 | LiveCodeBench pass@1 | CodeForces rating |
|---|---|---|---|---|---|---|
| GPT-4o-0513 | 9.3 | 13.4 | 74.6 | 49.9 | 32.9 | 759 |
| Claude-3.5-Sonnet-1022 | 16.0 | 26.7 | 78.3 | 65.0 | 38.9 | 717 |
| o1-mini | 63.6 | 80.0 | 90.0 | 60.0 | 53.8 | 1820 |
| QwQ-32B-Preview | 44.0 | 60.0 | 90.6 | 54.5 | 41.9 | 1316 |
| DeepSeek-R1-Distill-Qwen-1.5B | 28.9 | 52.7 | 83.9 | 33.8 | 16.9 | 954 |
| DeepSeek-R1-Distill-Qwen-7B | 55.5 | 83.3 | 92.8 | 49.1 | 37.6 | 1189 |
| DeepSeek-R1-Distill-Qwen-14B | 69.7 | 80.0 | 93.9 | 59.1 | 53.1 | 1481 |
| DeepSeek-R1-Distill-Qwen-32B | 72.6 | 83.3 | 94.3 | 62.1 | 57.2 | 1691 |
| DeepSeek-R1-Distill-Llama-8B | 50.4 | 80.0 | 89.1 | 49.0 | 39.6 | 1205 |
| DeepSeek-R1-Distill-Llama-70B | 70.0 | 86.7 | 94.5 | 65.2 | 57.5 | 1633 |
DeepSeek-R1-Distill-Qwen-1.5B
数学(MATH-500: 83.9%) → 基本的な数学推論が可能。
プログラミング(LiveCodeBench: 16.9%) → プログラミング能力は低く、コード生成には不向き。
DeepSeek-R1-Distill-Qwen-7B
数学(MATH-500: 92.8%) → トップクラスの数学推論能力を持つ。
一般知識(GPQA Diamond: 49.1%) → 一般的な知識にもある程度対応可能。
プログラミング(LiveCodeBench: 37.6%) → 簡単なコード生成が可能。
DeepSeek-R1-Distill-Llama-8B
数学(MATH-500: 89.1%) → 高い数学推論能力を持つ。
一般知識(GPQA Diamond: 49.0%) → 基本的な知識問題には対応。
プログラミング(LiveCodeBench: 39.6%) → 一部のコード生成に対応できるが、強みではない。
DeepSeek-R1-Distill-Qwen-14B
数学(MATH-500: 93.9%) → トップレベルの数学推論能力。
一般知識(GPQA Diamond: 59.1%) → 幅広い知識領域に対応。
プログラミング(LiveCodeBench: 53.1%) → コーディング能力が向上し、実用的な範囲。
DeepSeek-R1-Distill-Qwen-32B
数学(MATH-500: 94.3%) → 最高クラスの数学推論能力。
一般知識(GPQA Diamond: 62.1%) → 幅広い知識に対応可能。
プログラミング(LiveCodeBench: 57.2%) → コード生成能力がさらに向上。
高度数学推論(AIME 2024: 72.6%) → 複雑な数学問題も解ける。
DeepSeek-R1-Distill-Llama-70B
数学(MATH-500: 94.5%) → 最高レベルの数学推論能力。
高度数学推論(AIME 2024: 86.7%) → 非常に複雑な数学問題にも対応可能。
プログラミング(LiveCodeBench: 57.5%) → 実用的なコード生成が可能。
アルゴリズム(Codeforces: 1633) → アルゴリズムや競技プログラミング分野でも強みを発揮。
DeepSeek-R1の日本語対応は?

DeepSeek-R1の各モデルは日本語に対応していますが、パラメータ数が14B未満のモデルでは、回答に中国語や英語が混ざることがあります。
一方、32B以上のモデルでは、より流暢で自然な日本語の応答が可能となり、実用性が向上します。
さらに、DeepSeek-R1を日本語データで追加学習したモデルも公開されており、日本語の精度を重視する場合には、これらのモデルの活用を検討するとよいでしょう。
DeepSeek-R1の日本語モデルとは?
DeepSeek-R1の安全性と注意点

DeepSeekは、アプリやAPI、オープンモデルまで幅広い形態でサービスを提供しています。
サービスによって、安全性に関する捉え方が異なりますので、分けて説明します。
アプリやAPIを使用する場合の注意点
アプリやAPIを利用してDeepSeekにアクセスする場合、入力したデータは外部のサーバーへ送信されます。
DeepSeekの利用規約によると、この入力データはモデルの学習に活用される可能性が記述されており、OpenAIのような「学習対象からの除外(オプトアウト)」機能は提供されていません。
したがって、個人情報や機密情報を入力すると、それらが学習データとして取り扱われるリスクがある点に注意が必要です。
DeepSeekの利用規約
オープンモデルを使用する場合の注意点
DeepSeek-R1をローカル環境にダウンロードして利用する場合、外部のサーバーへデータを送信しなくて済むため、個人情報や機密情報が漏洩するリスクは基本的にありません。
具体的には、HuggingFaceやOllamaなどのプラットフォームからモデルをダウンロードし、ローカル環境で運用する形式となるため、DeepSeek社に情報を提供する必要がありません。
DeepSeek-R1にはMITやApache 2.0、Llama等のライセンスが適用されており、改変・再配布・商用利用などが自由に行えます。
モデルによってライセンスが異なりますので、ご利用の際は該当するライセンスをご確認ください。
DeepSeek-R1をローカル環境で使用する方法は?
DeepSeekの安全性を詳しく解説!

DeepSeek-R1の商用利用・ライセンス

DeepSeek-R1は、基本的に無料で商用利用が可能ですが、モデルの種類によってライセンスが異なります。
DeepSeek-R1(671B)はライセンスは「MIT」
DeepSeek-R1(671B)は、MITライセンスをもとに提供されており、無料で商用利用できます。
MITライセンスは、ソフトウェアの配布に使用される非常に寛容なオープンソースライセンスです
商用利用:ソフトウェアやコードを商用利用することが完全に許可されています。
改変:ソフトウェアを自由に修正したり改変したりすることができます。
配布:修正したり変更したりしたソフトウェアを自由に配布することができます。
著作権の表示:再配布時にオリジナルの著作権表示とライセンス条項を含める必要があります。
特許利用:特許利用に関する明示的な規定はありません。
DeepSeek-R1-Distill-Qwenのライセンスは「Apache 2.0」
DeepSeek-R1-Distill-Qwenシリーズは、Apache License 2.0に基づいて提供されており、無料で商用利用できます。
| モデルID | ベースモデル | ライセンス |
|---|---|---|
| deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B | Qwen2.5-Math-1.5B | Apache 2.0 License |
| deepseek-ai/DeepSeek-R1-Distill-Qwen-7B | Qwen2.5-Math-7B | Apache 2.0 License |
| deepseek-ai/DeepSeek-R1-Distill-Qwen-14B | Qwen2.5-14B | Apache 2.0 License |
| deepseek-ai/DeepSeek-R1-Distill-Qwen-32B | Qwen2.5-32B | Apache 2.0 License |
商用利用:ソフトウェアやコードを商用利用することが許可されています。
改変:ソフトウェアやコードを自由に修正したり改変したりすることができます。
配布:修正したり変更したりしたソフトウェアを自由に配布することができます。
著作権表示:元の著作権表示とライセンス条項を含める必要があります。
特許利用:利用者に特許使用権が付与されています。
DeepSeek-R1-Distill-Llamaのライセンスは「META LLAMA COMMUNITY LICENSE」
DeepSeek-R1-Distill-Llamaシリーズは、「META LLAMA COMMUNITY LICENSE」にもとづいて、無料で利用でき、商用利用も可能です。
| モデルID | ベースモデル | ライセンス |
|---|---|---|
| deepseek-ai/DeepSeek-R1-Distill-Llama-8B | Llama-3.1-8B | llama3.1 license |
| deepseek-ai/DeepSeek-R1-Distill-Llama-70B | Llama-3.3-70B-Instruct | llama3.3 license |
商用利用:ソフトウェアやコードを商用利用することが許可されています。
改変:ソフトウェアやコードを自由に修正したり改変したりすることができます。
配布:修正したり変更したりしたソフトウェアを自由に配布することができます。
著作権表示:再配布時に、著作権の表示や契約書コピーの提供などが必要になります。
特許利用:特許利用に関する明示的な規定はありません。
詳細はLlamaのライセンスページをご参照ください。
DeepSeek-R1の使い方は?
DeepSeek-R1を活用したRAGの構築方法は?

生成AI・LLMのコストでお困りなら
GPUのスペック不足で生成AIの開発が思うように進まないことはありませんか?
そんなときには、高性能なGPUをリーズナブルな価格で使えるGPUクラウドサービスがおすすめです!

GPUSOROBANは、高性能GPU「NVIDIA H200」を業界最安級の料金で使用することができます。
NVIDIA H200は、生成AI・LLMの計算にかかる時間を大幅に短縮することが可能です。
クラウドで使えるため、大規模な設備投資の必要がなく、煩雑なサーバー管理からも解放されます。




