
Ollama-OpenWebUIは、ChatGPTのインターフェイスでローカルLLMが使えるアプリケーションです。
現在Ollamaで提供されているLLMは、DeepSeekやLlamaなどの海外モデルのみになります。
この記事では、Ollamaに日本語モデルをダウンロードして利用する方法を解説します。
ざっくり言うと
- Ollamaに日本語LLMをダウンロードして使用する方法が分かる
- Ollama-OpenWebUIでChatGPTようなインターフェイスを構築

Ollama-OpenWebUIで日本語LLMは使える?
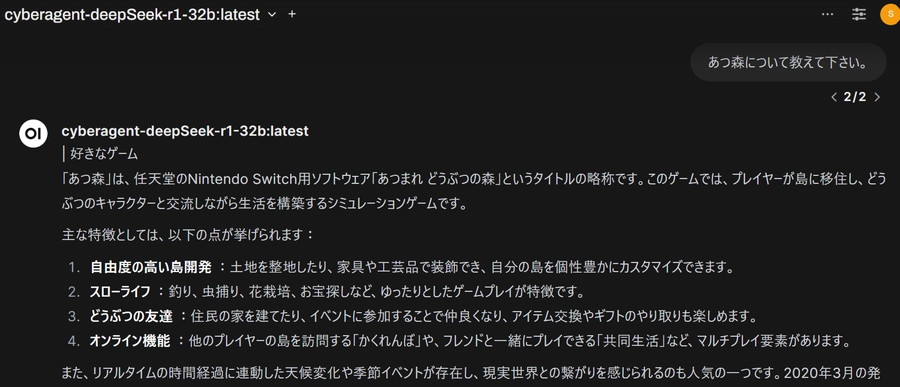
Ollama-OpenWebUIは、ChatGPTのインターフェイスでローカルLLMが使えるアプリケーションです。
Ollamaで提供されているLLMは、DeepSeekやLlamaなどの海外モデルのみとなっています。
日本語LLMに関しては、外部からモデルをダウンロードし、Ollamaにセットすることで利用できます。
Ollama-OpenWebUIの環境構築

この記事で用意した実行環境は以下のとおりです。
Ubuntu上でOllamaとOpenWebUI を組み合わせた Docker コンテナを構築します。
Ollama はローカルで LLMを実行できるツール、OpenWebUI は ChatGPT のような対話型インターフェイスを提供するアプリケーションです。
- GPU:NVIDIA A100 80GB
- GPUメモリ(VRAM):80GB
- OS :Ubuntu 22.04
- Docker
Ollama-OpenWebUIの環境構築を解説!

Ollama-Pythonで日本語LLMを使用する方法は?


Ollama環境に日本語LLMをセットアップ

Ollama-OpenWebUIのセットアップが完了したら、Ollamaのコンテナにログインします。
UbuntuのターミナルからDockerコンテナにログインします。
docker exec -it ollama /bin/bashDockerコンテナ内で必要なパッケージをインストールします。
apt-get update && apt-get install -y curl nanoDeepSeek-R1の日本語モデルをHuggingFaceからダウンロードします。
curl -L -o cyberagent-DeepSeek-R1-Distill-Qwen-32B-Japanese-Q4_K_M.gguf "https://huggingface.co/mmnga/cyberagent-DeepSeek-R1-Distill-Qwen-32B-Japanese-gguf/resolve/main/cyberagent-DeepSeek-R1-Distill-Qwen-32B-Japanese-Q4_K_M.gguf?download=true"HuggingFaceでお好みのモデルを無料でダウンロードできます!

LLMのモデルがOllama使えるようにプロンプトテンプレートを指定して、モデルを作成します。
モデルファイルを作成して、編集します。
nano Modelfile開いたモデルファイルに以下のコードをコピペします。
FROM ./cyberagent-DeepSeek-R1-Distill-Qwen-32B-Japanese-Q4_K_M.gguf
TEMPLATE """{{- if .System }}{{ .System }}{{ end }}
{{- range $i, $_ := .Messages }}
{{- $last := eq (len (slice $.Messages $i)) 1}}
{{- if eq .Role "user" }}<|User|>{{ .Content }}
{{- else if eq .Role "assistant" }}<|Assistant|>{{ .Content }}{{- if not $last }}<|end▁of▁sentence|>{{- end }}
{{- end }}
{{- if and $last (ne .Role "assistant") }}<|Assistant|>{{- end }}
{{- end }}"""
PARAMETER stop <|begin▁of▁sentence|>
PARAMETER stop <|end▁of▁sentence|>
PARAMETER stop <|User|>
PARAMETER stop <|Assistant|>FROM ./cyberagent-DeepSeek-R1-Distill-Qwen-32B-Japanese-Q4_K_M.gguf
ダウンロードしたモデルのパスが入ります。
TEMPLATE “””{{- if .System }}{{ .System }}{{ end }}…PARAMETER stop <|Assistant|>
モデルで使用するプロンプトテンプレートが入ります。モデルによって記述する内容が異なりますので、ご注意ください。
Ollamaにカスタムモデルを登録し、実行できる状態にします。
ollama create cyberagent-deepSeek-r1-32b -f Modelfileollama create:新しいローカルモデルを登録するために使います。
cyberagent-deepSeek-r1-32b:作成するモデルの任意の名称を指定します。
-f Modelfile:モデルの設定ファイル(Modelfile)を指定するためのオプション。
UbuntuのターミナルからOllama-OpenWebUIを再起動します。
docker compose upコンテナが起動したら、ローカルPCの「ブラウザの検索窓」に以下のURLを入力し、Enterを押すとOpenWebUIの画面が表示されます。
http://localhost:8080/Ollama-OpenWebUIで日本語LLMを動かす

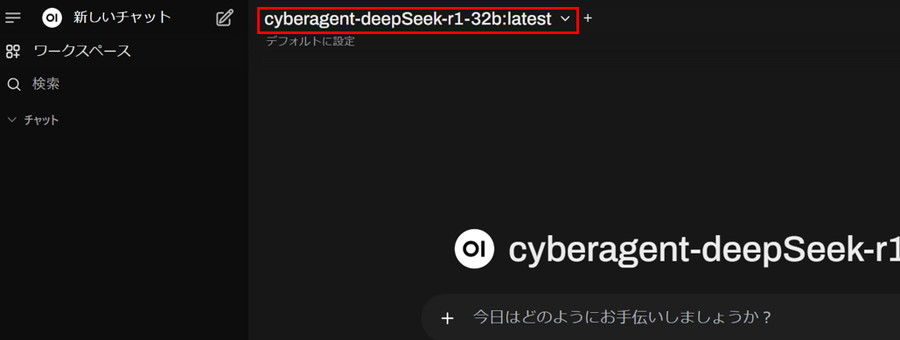
Ollama-OpenWebUIの画面を操作して、テキストを生成します。
ダウンロードしたモデルを選択します。
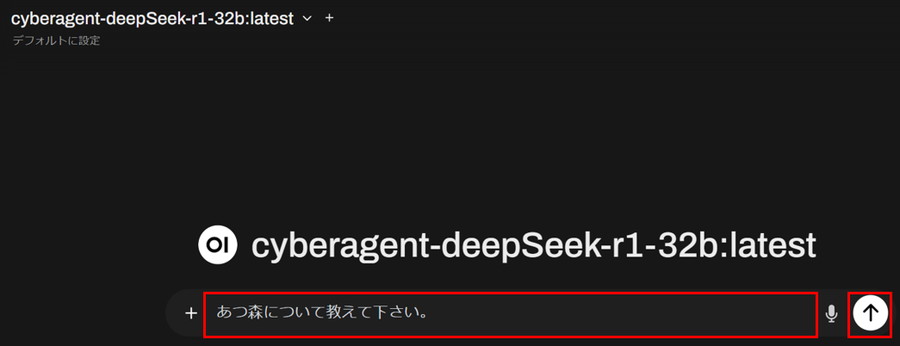
プロンプトを入力して、矢印ボタンを押します。
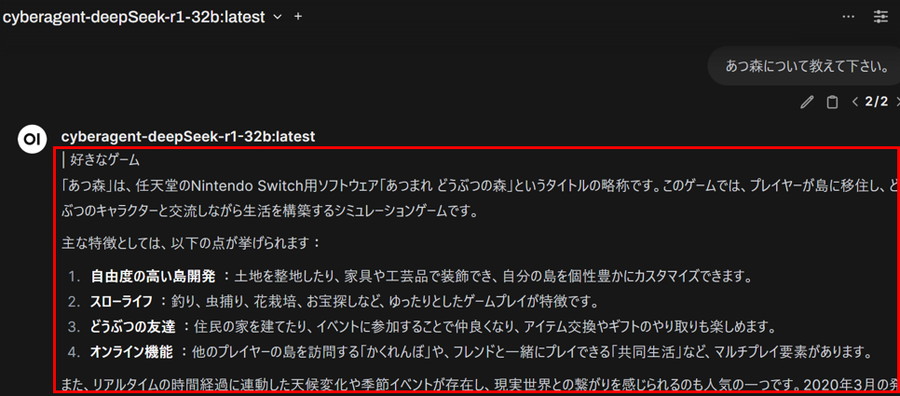
入力したプロンプトに対して、モデルが回答を生成します。
Ollama-Pythonで日本語LLMを使用する方法は?
生成AI・LLMのコストでお困りなら
GPUのスペック不足で生成AIの開発が思うように進まないことはありませんか?
そんなときには、高性能なGPUをリーズナブルな価格で使えるGPUクラウドサービスがおすすめです!

GPUSOROBANは、生成AI・LLM向けの高速GPUを業界最安級の料金で使用することができます。
インターネット環境さえあれば、クラウド環境のGPUサーバーをすぐに利用可能です。
大規模な設備投資の必要がなく、煩雑なサーバー管理からも解放されます。






