
Llama-3-ELYZA-JPは、東大・松尾研発のスタートアップELYZAが公開した日本語LLMです。
Llama-3-ELYZA-JP-70Bは、「GPT-4」や「Claude 3 Sonnet」を上回る性能があります。
この記事では、Llama-3-ELYZA-JPの性能から使い方まで紹介します。

Llama-3-ELYZA-JPとは

Llama-3-ELYZA-JPは、Meta社のLlama3をベースに追加学習をして開発された日本語LLMです。
700億パラメータの「Llama-3-ELYZA-JP-70B」は、「GPT-4」や「Claude 3 Sonnet」を上回る性能を持っています。
ざっくり言うと
- Llama3をベースに追加学習した日本語LLM
- 700億パラメータのモデルは、GPT-4を上回る性能を持つ
- 80億パラメータのモデルは、無料で商用利用も可能

Llama-3-ELYZA-JPのモデル

Llama-3-ELYZA-JPのモデルには複数の種類があり、「パラメータサイズ」と「量子化」で分けられます。
| モデルID | パラメータサイズ | 量子化 | 公開 |
|---|---|---|---|
| elyza/Llama-3-ELYZA-JP-8B | 80億パラメータ | なし | HuggingFace |
| elyza/Llama-3-ELYZA-JP-8B-AWQ | 80億パラメータ | あり(AWQ) | HuggingFace |
| elyza/Llama-3-ELYZA-JP-8B-GGUF | 80億パラメータ | あり(GGUF) | HuggingFace |
| Llama-3-ELYZA-JP-70B | 700億パラメータ | なし | デモサイト |
80億パラメータのLlama-3-ELYZA-JP-8Bは、HuggingFaceで公開されており、無料でダウンロードできます。
700億パラメータのLlama-3-ELYZA-JP-70Bは、ELYZAのデモサイトでお試し利用ができますが、残念ながらダウンロードすることはできません。
量子化をした軽量のモデルには、AWQとGGUFのタイプがありますが、以下のような違いがあります。
AWQ
vLLM、HuggingFace、TensorRT-LLM、FastChatなどでサポートされているフォーマットです。
GGUF
Ollama、llama.cppなどでサポートされているフォーマットです。
Llama-3-ELYZA-JPの性能
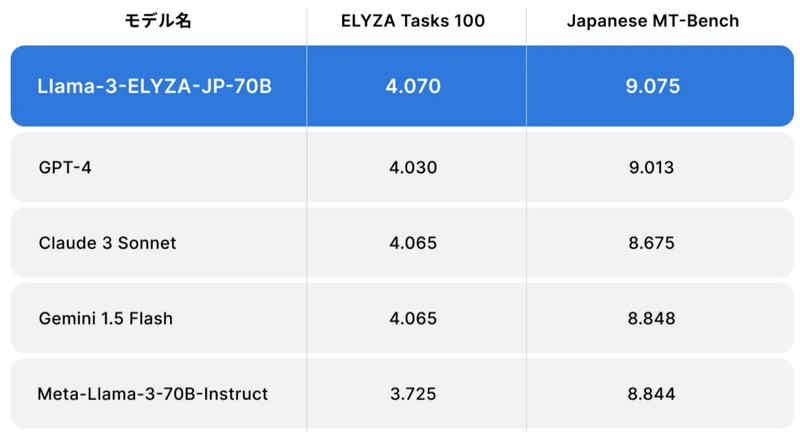
日本語能力に関するベンチマーク評価(ELYZA Tasks 100、Japanese MT-Bench)を使って、モデルの性能を比較しています。
700億パラメータの「Llama-3-ELYZA-JP-70B」は、GPT-4やClaude 3 Sonnetを上回る性能を出しています。
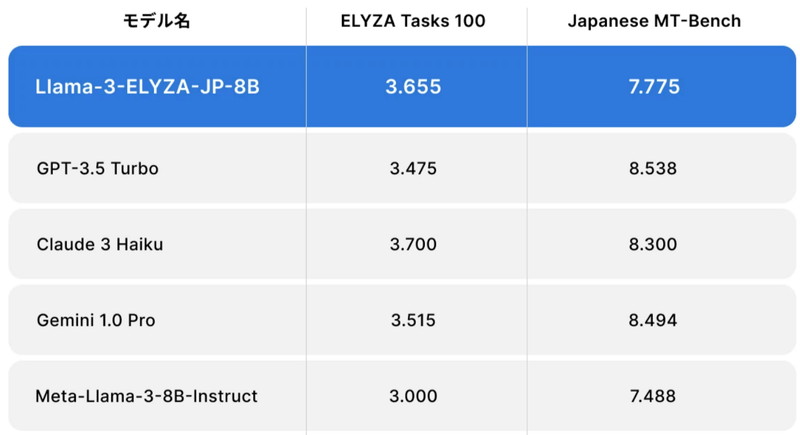
80億パラメータの「Llama-3-ELYZA-JP-8B」は、GPT-3.5 Turbo、Gemini 1.0 Proに匹敵する性能を出しています。
ELYZA Tasks 100
複雑な指示やタスクを含む多様な日本語データセットを用い、明確な基準で評価をするベンチマークです。
https://huggingface.co/datasets/elyza/ELYZA-tasks-100
Japanese MT-Bench
日本語による複数ターンの質問をして、モデルの応答を多角的に評価するベンチマークです。
https://github.com/Stability-AI/FastChat/tree/jp-stable/fastchat/llm_judge#llm-judge
Llama-3-ELYZA-JPの商用利用・ライセンス

Llama-3-ELYZA-JP-8Bは、「META LLAMA 3 COMMUNITY LICENSE」に基づいて、無料で使用でき商用利用も可能です。
商用利用:ソフトウェアやコードを商用利用することが許可されています。
改変:ソフトウェアやコードを自由に修正したり改変したりすることができます。
配布:修正したり変更したりしたソフトウェアを自由に配布することができます。
著作権表示:再配布時に、著作権の表示や契約書コピーの提供などが必要になります。
特許利用:特許利用に関する明示的な規定はありません。
詳細は「META LLAMA 3 COMMUNITY LICENSE」のページをご確認ください。
Llama-3-ELYZA-JPの使い方

ここからLlama-3-ELYZA-JPを使ったテキスト生成について解説していきます。
実行環境
この記事で用意した実行環境は以下のとおりです。
- GPU:NVIDIA A100 80GB
- GPUメモリ(VRAM):80GB
- OS :Ubuntu 22.04
- Docker
Dockerで環境構築
Dockerを使用してLlama-3-ELYZA-JPの環境構築をします
Dockerの使い方は以下の記事をご覧ください。

コンテナにインストールするパッケージは以下のとおりです。
CUDA、PyTorch、Transformersはバージョン依存関係によるエラーが起きやすいので、動作検証済のバージョン指定してインストールしています。
- CUDA:12.1
- Python:3.10
- PyTorch:2.2.2
- transformers:4.41.2
- accelerate
- triton
Ubuntuのコマンドラインで、Dockerfileを作成します。
mkdir elyza3_inference
cd elyza3_inference
nano DockerfileDockerfileに以下の記述を貼り付けます。
# ベースイメージ(CUDA)の指定
FROM nvidia/cuda:12.1.0-cudnn8-devel-ubuntu22.04
# 必要なパッケージをインストール
RUN apt-get update && apt-get install -y python3-pip python3-venv git nano
# 作業ディレクトリを設定
WORKDIR /app
# アプリケーションコードをコピー
COPY . /app
# Python仮想環境の作成
RUN python3 -m venv /app/.venv
# 仮想環境をアクティベートするコマンドを.bashrcに追加
RUN echo "source /app/.venv/bin/activate" >> /root/.bashrc
# JupyterLabのインストール
RUN /app/.venv/bin/pip install Jupyter jupyterlab
# PyTorchのインストール
RUN /app/.venv/bin/pip install torch==2.2.2 torchvision==0.17.2 torchaudio==2.2.2 --index-url https://download.pytorch.org/whl/cu121
# Transformer関連のインストール
RUN /app/.venv/bin/pip install transformers==4.41.2 accelerate bitsandbytes
# コンテナの起動時にbashを実行
CMD ["/bin/bash"]docker-compose.ymlでDockerコンテナの設定をします。
docker-compose.ymlのYAMLファイルを作成して開きます。
nano docker-compose.yml以下のコードをコピーして、YAMLファイルに貼り付けます。
services:
elyza3_inference:
build:
context: .
dockerfile: Dockerfile
image: elyza3_inference
runtime: nvidia
container_name: elyza3_inference
ports:
- "8888:8888"
volumes:
- .:/app/elyza3_inference
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: 1
capabilities: [gpu]
command: >
bash -c '/app/.venv/bin/jupyter lab --ip="*" --port=8888 --NotebookApp.token="" --NotebookApp.password="" --no-browser --allow-root'Dockerfileからビルドしてコンテナを起動します。
docker compose up
Dockerの起動後にブラウザの検索窓に”localhost:8888″を入力すると、Jupyter Labをブラウザで表示できます。
localhost:8888Llama-3-ELYZA-JP-8Bの実装
Dockerコンテナで起動したJupyter Lab上でLlama-3-ELYZA-JP-8Bの実装をします。
Jupyter Labのコードセルに次のコマンドを実行して、ライブラリをインポートします。
import torch
import transformers
from transformers import AutoModelForCausalLM, AutoTokenizerLlama-3-ELYZA-JPのモデルとトークナイザーを読み込みます。
model_id = "elyza/Llama-3-ELYZA-JP-8B"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype="auto",
device_map="auto",
)“elyza/Llama-3-ELYZA-JP-8B” : モデルのタイプを指定しています。
AutoModelForCausalLM.from_pretrained():モデルを読み込みます。
AutoTokenizer.from_pretrained():トークナイザーを読み込みます。
| モデルID | パラメータサイズ | 量子化 | GPUメモリ使用量 |
|---|---|---|---|
| elyza/Llama-3-ELYZA-JP-8B | 80億パラメータ | なし | 17GB |
AWQの量子化モデル「elyza/Llama-3-ELYZA-JP-8B-AWQ」を使う場合は、vllmなどの環境構築が必要です。

GGUFの量子化モデル「elyza/Llama-3-ELYZA-JP-8B-GGUF」を使う場合は、Ollamaやllama.cppなどの環境構築が必要です。


Llama-3-ELYZA-JP-8Bでテキスト生成

Llama-3-ELYZA-JP-8Bを使って、日本語での質問応答を試してみます。
日本語での質問応答
「佐賀県の観光地を教えて下さい。」というプロンプトを日本語で実行してみます。
DEFAULT_SYSTEM_PROMPT = "あなたは日本語で回答するアシスタントです。"
text = "佐賀県の観光地を教えて下さい。"
messages = [
{"role": "system", "content": DEFAULT_SYSTEM_PROMPT},
{"role": "user", "content": text},
]
prompt = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
token_ids = tokenizer.encode(
prompt, add_special_tokens=False,
return_tensors="pt"
)
with torch.no_grad():
output_ids = model.generate(
token_ids.to(model.device),
max_new_tokens=512,
do_sample=True,
temperature=0.6,
top_p=0.9,
)
output = tokenizer.decode(
output_ids.tolist()[0][token_ids.size(1):],
skip_special_tokens=True
)
print(output)佐賀県の観光地を教えて下さい。
佐賀県は、九州の北西部に位置し、自然、歴史、文化など多くの観光スポットがあります。以下は、佐賀県の代表的な観光地です。
1.唐津城: 唐津市のシンボルである城は、天守閣が現存する日本最古の城です。桜の名所でもあります。
2.呼子: 唐津市の呼子地区は、海に突き出た岬で、夕日が美しいと評判です。海の幸も新鮮で、イカやサバの活き造りが有名です。
3.有田焼の里: 有田町は、佐賀県の陶磁器の産地です。工房や美術館を訪れて、有田焼の歴史や技術を学ぶことができます。
4.武雄温泉: 武雄市の温泉は、古くから知られ、多くの文人墨客が訪れました。温泉街には、和菓子や甘味処もあります。
5.虹の松原: 多久市の虹の松原は、約260本の松が並ぶ景勝地です。特に、日没時は、松並木が虹色に染まります。
6.伊万里: 伊万里市は、佐賀県の西部に位置し、伊万里焼の産地です。工房や美術館を訪れて、伊万里焼の美術館を学ぶことができます。
7.神埼城: 神埼市の神埼城は、戦国時代の城で、現在は復元されています。周囲は、桜やつつじの名所です。
8.太良町の棚田: 太良町は、佐賀県の北西部に位置し、棚田が美しいと評判です。特に、稲穂が実る時期は、風景が一層美しくなります。
これらの観光地は、佐賀県の自然、歴史、文化を代表するスポットです。訪れてみて、佐賀県の魅力を体感してください。
生成AI・LLMのコストでお困りなら
GPUのスペック不足で生成AIの開発が思うように進まないことはありませんか?
そんなときには、高性能なGPUをリーズナブルな価格で使えるGPUクラウドサービスがおすすめです!

GPUSOROBANは、生成AI・LLM向けの高速GPUを業界最安級の料金で使用することができます。
インターネット環境さえあれば、クラウド環境のGPUサーバーをすぐに利用可能です。
大規模な設備投資の必要がなく、煩雑なサーバー管理からも解放されます。







