
Llama-3-Swallowは、MetaのLlama3をもとに、東工大・産総研が継続事前学習をした日本語に強いLLMです。
オープンなLLMの中で、日本語の言語理解・生成タスクにおいてトップクラスの性能があります。
この記事では、Llama-3-Swallowの性能、商用利用、使い方について紹介します。

Llama-3-Swallowとは

Llama-3-Swallowは、MetaのLlama3をもとに、東工大・産総研が継続事前学習をした日本語に強いLLMです。
オープンなLLMの中で、日本語の言語理解・生成タスクにおいてトップクラスの性能があります。
このモデルはMeta Llama3のライセンスに基づき、無料で利用でき商用利用が可能です。
ざっくり言うと
- Llama3をもとに、東工大・産総研が継続事前学習をした日本語に強いLLM
- オープンなLLMの中で、日本語の言語理解・生成タスクにおいてトップクラスの性能
- Meta Llama3のライセンスに基づき、無料で利用でき商用利用が可能
Llama3に関する記事は別の記事で解説してます。


Llama-3-Swallowのモデル

Llama-3-Swallowのモデルには複数の種類があり、「パラメータサイズ」と「事前学習/指示学習」で分けられます。
モデルはHuggingFaceで公開されており、無料でダウンロードできます。
| モデルID | パラメータサイズ | 事前学習/指示学習 | 公開 |
|---|---|---|---|
| tokyotech-llm/Llama-3-Swallow-8B-v0.1 | 80億パラメータ | 事前学習モデル | HuggingFace |
| tokyotech-llm/Llama-3-Swallow-8B-Instruct-v0.1 | 80億パラメータ | 指示学習モデル | HuggingFace |
| tokyotech-llm/Llama-3-Swallow-70B-v0.1 | 700億パラメータ | 事前学習モデル | HuggingFace |
| tokyotech-llm/Llama-3-Swallow-70B-Instruct-v0.1 | 700億パラメータ | 指示学習モデル | HuggingFace |
事前学習モデル
基礎的なデータが学習されたモデルです。基礎的な知識はありますが、人間の指示に応じた回答ができません。
指示学習モデル
事前学習モデルを特定のタスクや指示にもとづいて調整したモデルです。ChatGPTのように人間の指示に応じた回答が可能です。
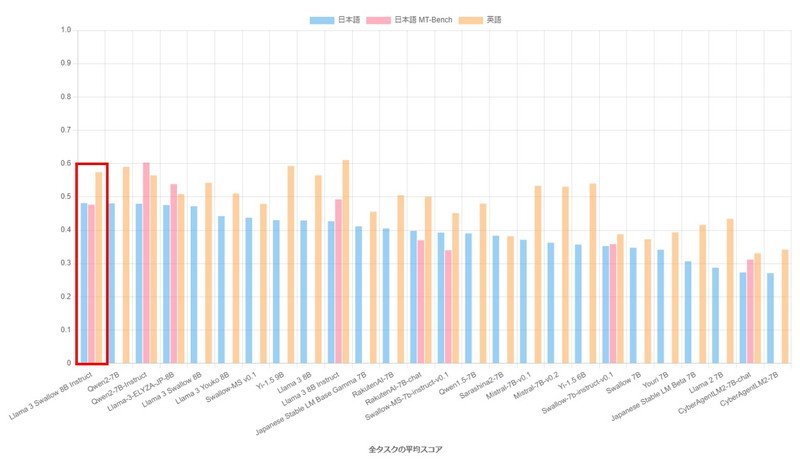
Llama-3-Swallowの性能

10億以下のパラメータ数のLLMでベンチマーク実験を行い、Llama-3-Swallow 8Bは日本語理解・生成タスクでトップクラスのスコアを記録しています。
Llama-3-Swallowの商用利用・ライセンス

Llama-3-Swallowは、「META LLAMA 3 COMMUNITY LICENSE」に基づいて、無料で使用でき商用利用も可能です。
商用利用:ソフトウェアやコードを商用利用することが許可されています。
改変:ソフトウェアやコードを自由に修正したり改変したりすることができます。
配布:修正したり変更したりしたソフトウェアを自由に配布することができます。
著作権表示:再配布時に、著作権の表示や契約書コピーの提供などが必要になります。
特許利用:特許利用に関する明示的な規定はありません。
詳細は「META LLAMA 3 COMMUNITY LICENSE」のページをご確認ください。
Llama-3-Swallowの使い方

ここからLlama-3-Swallowの使い方ついて解説していきます。
実行環境
この記事で用意した実行環境は以下のとおりです。
- GPU:NVIDIA A100 80GB
- GPUメモリ(VRAM):80GB
- OS :Ubuntu 22.04
- Docker
Dockerで環境構築
Dockerを使用してLlama-3-Swallowの環境構築をします
Dockerの使い方は以下の記事をご覧ください。

コンテナにインストールするパッケージは以下のとおりです。
CUDA、PyTorch、Transformersはバージョン依存関係によるエラーが起きやすいので、動作検証済のバージョン指定してインストールしています。
- CUDA:12.1
- Python:3.10
- PyTorch:2.2.2
- transformers:4.41.2
- accelerate
Ubuntuのコマンドラインで、Dockerfileを作成します。
mkdir swallow3_inference
cd swallow3_inference
nano DockerfileDockerfileに以下の記述を貼り付けます。
# ベースイメージ(CUDA)の指定
FROM nvidia/cuda:12.1.0-cudnn8-devel-ubuntu22.04
# 必要なパッケージをインストール
RUN apt-get update && apt-get install -y python3-pip python3-venv git nano
# 作業ディレクトリを設定
WORKDIR /app
# アプリケーションコードをコピー
COPY . /app
# Python仮想環境の作成
RUN python3 -m venv /app/.venv
# 仮想環境をアクティベートするコマンドを.bashrcに追加
RUN echo "source /app/.venv/bin/activate" >> /root/.bashrc
# JupyterLabのインストール
RUN /app/.venv/bin/pip install Jupyter jupyterlab
# PyTorchのインストール
RUN /app/.venv/bin/pip install torch==2.2.2 torchvision==0.17.2 torchaudio==2.2.2 --index-url https://download.pytorch.org/whl/cu121
# Transformer関連のインストール
RUN /app/.venv/bin/pip install transformers==4.41.2 accelerate bitsandbytes
# コンテナの起動時にbashを実行
CMD ["/bin/bash"]docker-compose.ymlでDockerコンテナの設定をします。
docker-compose.ymlのYAMLファイルを作成して開きます。
nano docker-compose.yml以下のコードをコピーして、YAMLファイルに貼り付けます。
services:
swallow3_inference:
build:
context: .
dockerfile: Dockerfile
image: swallow3_inference
runtime: nvidia
container_name: swallow3_inference
ports:
- "8888:8888"
volumes:
- .:/app/swallow3_inference
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: 1
capabilities: [gpu]
command: >
bash -c '/app/.venv/bin/jupyter lab --ip="*" --port=8888 --NotebookApp.token="" --NotebookApp.password="" --no-browser --allow-root'Dockerfileからビルドしてコンテナを起動します。
docker compose up
Dockerの起動後にブラウザの検索窓に”localhost:8888″を入力すると、Jupyter Labをブラウザで表示できます。
localhost:8888Llama-3-Swallowの実装
Dockerコンテナで起動したJupyter Lab上でLlama-3-Swallowの実装をします。
Jupyter Labのコードセルに次のコマンドを実行して、ライブラリをインポートします。
import torch
import transformers
from transformers import AutoModelForCausalLM, AutoTokenizer,BitsAndBytesConfigLlama-3-Swallowのモデルとトークナイザーを読み込みます。
model_id = "tokyotech-llm/Llama-3-Swallow-8B-Instruct-v0.1"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
device_map="auto",
)“tokyotech-llm/Llama-3-Swallow-8B-Instruct-v0.1”
モデルのタイプを指定しています。
AutoModelForCausalLM.from_pretrained()
モデルを読み込みます。
torch_dtype=torch.bfloat16,:BF16の数値表現を指定しています。
量子化をする場合はquantization_config=BitsAndBytesConfig(load_in_4bit=True),を引数に追加してください。
AutoTokenizer.from_pretrained()
トークナイザーを読み込みます。
| モデルID | パラメータサイズ | GPUメモリ使用量 |
|---|---|---|
| tokyotech-llm/Llama-3-Swallow-8B-Instruct-v0.1 | 80億パラメータ | 17GB(BF16,量子化なし) |
| tokyotech-llm/Llama-3-Swallow-70B-Instruct-v0.1 | 700億パラメータ | 43GB(BF16,量子化あり) |
Llama-3-Swallowのでテキスト生成

Llama-3-Swallow 8Bを使って、日本語での質問応答を試してみます。
日本語での質問応答(1)
「熊本県の観光地を教えて下さい。」というプロンプトを日本語で実行してみます。
DEFAULT_SYSTEM_PROMPT = "あなたは日本語で回答するアシスタントです。"
text = "熊本県の観光地を教えて下さい。"
messages = [
{"role": "system", "content": DEFAULT_SYSTEM_PROMPT},
{"role": "user", "content": text},
]
prompt = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
token_ids = tokenizer.encode(
prompt, add_special_tokens=False,
return_tensors="pt"
)
with torch.no_grad():
output_ids = model.generate(
token_ids.to(model.device),
max_new_tokens=512,
do_sample=True,
temperature=0.6,
top_p=0.9,
)
output = tokenizer.decode(
output_ids.tolist()[0][token_ids.size(1):],
skip_special_tokens=True
)
print(output)messages
モデルへのプロンプトを定義しています。
pipeline.tokenizer.apply_chat_template()
Llama3.1のチャットテンプレートを適用してプロンプトを作成しています。モデルによって異なります。
tokenizer.encode()
プロンプトをトークンIDに変換しています。
model.generate()
モデルからトークンIDを生成します。
tokenizer.decode()
トークンIDを人間が読めるテキストに変換します。
熊本県の観光地を教えて下さい。
熊本県は、日本の九州地方に位置する県で、豊かな自然と歴史、文化が豊かな観光地がたくさんあります。
1. 阿蘇山:世界的に有名な活火山で、火山の麓には美しい草原が広がっています。火口湖や温泉などもあり、観光客に人気があります。
2. 黒川温泉:日本の温泉の1つで、美しい自然に囲まれた温泉地帯です。温泉に入る以外にも、散歩や観光スポットもあります。
3. 熊本城:熊本県のシンボルで、江戸時代に建てられた城です。城内には、美しい庭園や歴史的な建物があり、観光客に人気があります。
4. 水前寺公園:熊本市の中心にある公園で、美しい日本庭園や、水の流れる池があります。観光客は、散歩や休憩に訪れます。
5. 天草:熊本県の南部にある島で、美しい海岸線や、歴史的な教会などが観光スポットです。観光客は、釣りやダイビングなども楽しめます。
6. 人吉:熊本県の南部にある町で、歴史的な建物や、温泉、観光スポットが豊富です。観光客は、散歩や、温泉に入るなど、楽しめます。
7. 高千穂峡:熊本県の南部にある峡谷で、美しい水の流れや、滝が観光スポットです。観光客は、ボートに乗って、峡谷を巡ることができます。
8. 阿蘇神社:阿蘇山の麓にある神社で、歴史的な建物や、美しい庭園があります。観光客は、散歩や、参拝に訪れます。
これらは、熊本県の主要な観光地です。各地には、さらに多くの観光スポットがありますので、訪れる際は、事前に調べておくことをお勧めします。
日本語での質問応答(2)
「動画編集ツールのFAQを作成してください。」というプロンプトを実行してみます。
DEFAULT_SYSTEM_PROMPT = "あなたは日本語で回答するアシスタントです。"
text = "動画編集ツールのFAQを作成してください。"
messages = [
{"role": "system", "content": DEFAULT_SYSTEM_PROMPT},
{"role": "user", "content": text},
]
prompt = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
token_ids = tokenizer.encode(
prompt, add_special_tokens=False,
return_tensors="pt"
)
with torch.no_grad():
output_ids = model.generate(
token_ids.to(model.device),
max_new_tokens=512,
do_sample=True,
temperature=0.6,
top_p=0.9,
)
output = tokenizer.decode(
output_ids.tolist()[0][token_ids.size(1):],
skip_special_tokens=True
)
print(output)動画編集ツールのFAQを作成してください。
Q: 動画編集ツールとは何ですか?
A: 動画編集ツールは、動画ファイルを編集、加工、変換するためのソフトウェアまたはウェブサービスです。動画のトリミング、カット、結合、エフェクトの追加、音声の調整、字幕の追加など、さまざまな機能が提供されています。
Q: 動画編集ツールを選ぶ基準は何ですか?
A: 動画編集ツールを選ぶ基準は、使用する目的、編集する動画の形式、予算、ユーザーインターフェイス、機能、サポートなどです。例えば、YouTubeにアップロードするための簡単な編集が目的であれば、無料のオンラインツールでも十分です。一方、プロフェッショナルな編集が必要な場合は、有料のソフトウェアを選ぶことをお勧めします。
Q: 動画編集ツールでできることは何ですか?
A: 動画編集ツールでできることは、動画のトリミング、カット、結合、エフェクトの追加、音声の調整、字幕の追加、色彩の調整、速度の調整、テキストの追加、音楽の追加など、さまざまです。また、動画を変換することもできます。例えば、MP4からAVI、MOVからMP4など、さまざまな形式に変換することができます。
Q: 動画編集ツールの使い方は?
A: 動画編集ツールの使い方は、ソフトウェアやウェブサービスによって異なりますが、基本的な操作は同じです。動画ファイルをアップロードまたはインポートし、編集したい部分を選択し、編集する機能を適用し、保存またはエクスポートします。多くのツールでは、チュートリアルやヘルプが用意されているので、初心者でも簡単に使い方を学ぶことができます。
Q: 動画編集ツールで著作権に違反することはありますか?
A: 動画編集ツールで著作権に違反することはありません。著作権に違反する場合は
コード生成
「Pytorchで畳み込み層を作成する方法を教えて下さい。」というプロンプトで質問を投げてみます。
DEFAULT_SYSTEM_PROMPT = "あなたは日本語で回答するアシスタントです。"
text = "Pytorchで畳み込み層を作成する方法を教えて下さい。"
messages = [
{"role": "system", "content": DEFAULT_SYSTEM_PROMPT},
{"role": "user", "content": text},
]
prompt = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
token_ids = tokenizer.encode(
prompt, add_special_tokens=False,
return_tensors="pt"
)
with torch.no_grad():
output_ids = model.generate(
token_ids.to(model.device),
max_new_tokens=512,
do_sample=True,
temperature=0.6,
top_p=0.9,
)
output = tokenizer.decode(
output_ids.tolist()[0][token_ids.size(1):],
skip_special_tokens=True
)
print(output)Pytorchで畳み込み層を作成する方法を教えて下さい。
モデルの応答
PyTorchで畳み込み層を作成する方法は、`nn.Conv2d`クラスを使用します。
以下は、畳み込み層の基本的な作成方法です。
```python
import torch
import torch.nn as nn
# 定義する畳み込み層
class ConvLayer(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True):
super(ConvLayer, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size, stride=stride, padding=padding, dilation=dilation, groups=groups, bias=bias)
# 前処理
def forward(self, x):
return self.conv(x)
# 入力チャンネル数, 出力チャンネル数, カーネルサイズ, ストライド, パディングを指定
layer = ConvLayer(3, 6, 5, padding=2)
print(layer)
```
上記の例では、`ConvLayer`クラスを作成し、`nn.Conv2d`クラスをインスタンス化して畳み込み層を定義しています。`forward`メソッドでは、入力データ `x` を畳み込み層 `self.conv` に通して出力データを返しています。
また、`nn.Conv2d`クラスには様々なパラメータが用意されているため、用途に応じて適切に設定することが重要です。例えば、`stride`や`padding`を変更することで、畳み込み層の出力サイズや畳み込みのパターンを調整することができます。
生成AI・LLMのコストでお困りなら
GPUのスペック不足で生成AIの開発が思うように進まないことはありませんか?
そんなときには、高性能なGPUをリーズナブルな価格で使えるGPUクラウドサービスがおすすめです!

GPUSOROBANは、生成AI・LLM向けの高速GPUを業界最安級の料金で使用することができます。
インターネット環境さえあれば、クラウド環境のGPUサーバーをすぐに利用可能です。
大規模な設備投資の必要がなく、煩雑なサーバー管理からも解放されます。







