
Llama 3.1は、Meta社が開発した最新のLLMで、4050億のパラメータを持つ非常に大規模なモデルです。
Llama 3.1は、GPT-4oやClaude 3.5 Sonnetに匹敵する性能を持つと言われています。
この記事では、Llama 3.1の性能から商用利用、使い方まで紹介します。

Llama 3.1とは

Llama 3.1は、Meta社が開発した最新のLLMで、4050億のパラメータを持つ非常に大規模なモデルです。
Llama 3.1は、GPT-4oやClaude 3.5 Sonnetに匹敵する性能を持つと言われています。
このモデルは、Metaのライセンスに基づいて無料で利用でき、商用利用も許可されています。
- Llama 3.1は、Meta社が開発した最新のLLMで、4050億のパラメータを持つ
- GPT-4oやClaude 3.5 Sonnetと同等以上の性能
- Metaのライセンスに基づいて無料で利用でき、商用利用も許可
Llama 3.1のファインチューニングは別の記事で解説しています。


Llama 3.1のモデル(8B、70B、405B)

Llama 3.1のモデルには、80億と700億、4050億の3つのパラメータサイズがあります。
それぞれに「事前学習モデル」と人間の指示に基づいた回答をするための「指示学習モデル」が用意されています。
| モデルID | パラメータ | タイプ | 量子化 |
|---|---|---|---|
| meta-llama/Meta-Llama-3.1-8B | 80億 | 事前学習モデル | なし |
| meta-llama/Meta-Llama-3.1-8B-Instruct | 80億 | 指示学習モデル | なし |
| meta-llama/Meta-Llama-3.1-70B | 700億 | 事前学習モデル | なし |
| meta-llama/Meta-Llama-3.1-70B-Instruct | 700億 | 指示学習モデル | なし |
| meta-llama/Meta-Llama-3.1-405B | 4050億 | 事前学習モデル | なし |
| meta-llama/Meta-Llama-3.1-405B-Instruct | 4050億 | 指示学習モデル | なし |
| meta-llama/Meta-Llama-3.1-405B-FP8 | 4050億 | 事前学習モデル | FP8量子化 |
| meta-llama/Meta-Llama-3.1-405B-Instruct-FP8 | 4050億 | 指示学習モデル | FP8量子化 |
Llama 3.1 405BのみFP8のデータ型に量子化されたモデルが提供されています。
Llama 3.1に必要なGPUメモリ(VRAM)

Llama 3.1の推論におけるGPUメモリ(VRAM)要件は、モデルのサイズや使用する数値表現(FP16、FP8、INT4)によって大きく異なります。
推論の場合
| モデルサイズ | FP16 | FP8 | INT4 |
|---|---|---|---|
| 8B | 16GB | 8GB | 4GB |
| 70B | 140GB | 70GB | 35GB |
| 405B | 810GB | 405GB | 203GB |
Llama 3.1のモデル学習の場合は、ファインチューニングの種類でGPUメモリ(VRAM)の要件が異なります。数値表現はHuggingFaceに記載がありませんでしたが、BF16を使用していると思われます。
学習の場合
| モデルサイズ | フルファインチューニング | LoRA | Q-LoRA |
|---|---|---|---|
| 8B | 60GB | 16GB | 6GB |
| 70B | 500GB | 160GB | 48GB |
| 405B | 3.25TB | 950GB | 250GB |
Llama 3.1の性能
Llama3.1の性能について、「主要ベンチマーク」と「人間による評価」の指標を見ていきます。

主要ベンチマーク
Llama 3.1 405Bは、GPT-4oとClaude 3.5 Sonnetと同等のスコアを記録し、一部のベンチマークでハイスコアでした。
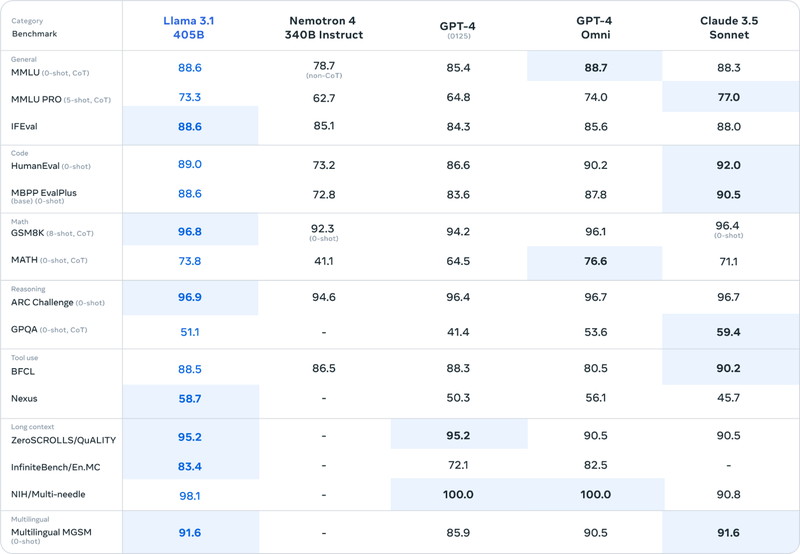
ベンチマークには次のような種目があります。
General:一般的な言語理解
Code:コード生成
Math:数学的推論
Reasoning:推論
Tool use:ツール利用
Long context:長文処理
Multilingual:多言語対応
Llama 3.1 8Bは、主要のベンチマークで、Gemma2とMistral 7Bより高いスコアになりました。
Llama 3.1 70Bは、Mistral 8x22BとGPT3.5Turboを上回っています。
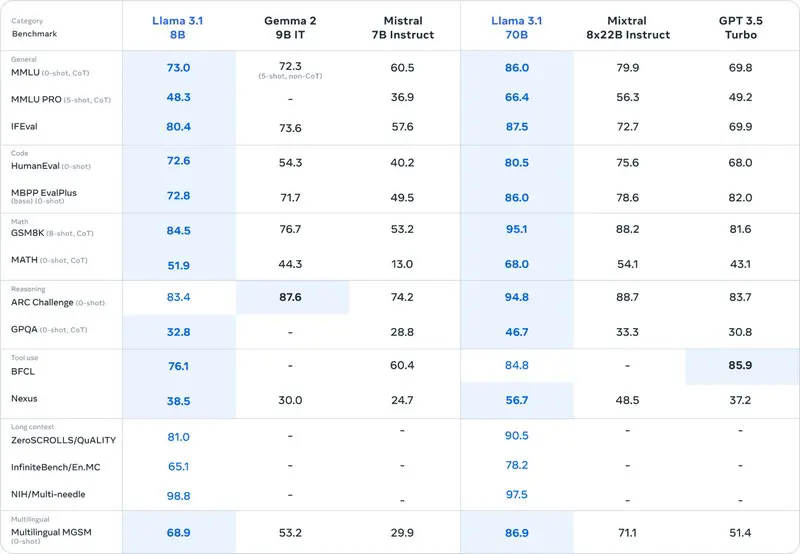
人間による評価
Llama 3.1は標準的なベンチマークのほか、実際のユースケースを想定した人間による有用性の評価を行っています。
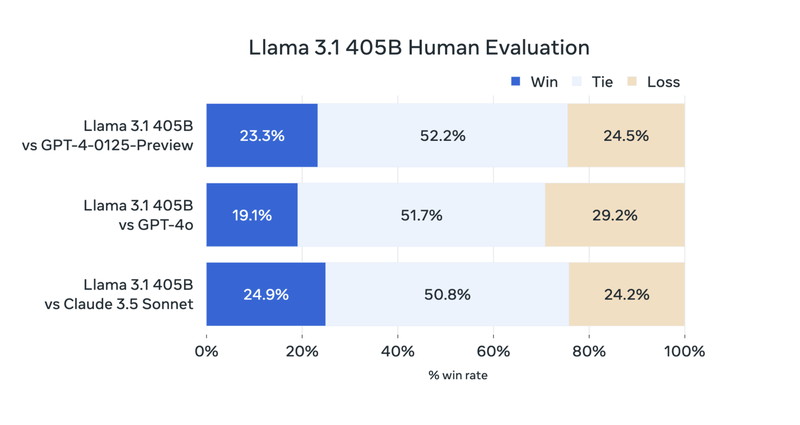
他のモデルの応答と比較して「どちらの答えの方が優れていたか」を人間が評価した結果は下図のとおりです。
図からGPT-4oやClaude 3.5 Sonnetと同等の評価を得ていることが分かります。
Llama 3.1の日本語能力は?

Llama 3.1のサポートする8言語に日本語が含まれていないことから、日本語の学習率は高くないことが推測されます。
この記事では、Llama 3.1を使って日本語生成のテストをしてみます。
Llama 3.1に日本語を追加学習したモデルは別記事で解説しています。

Llama 3.1の商用利用・ライセンス

Llama 3.1は「META LLAMA 3.1 COMMUNITY LICENSE」にもとづいて、無料で利用でき、商用利用も可能です。
商用利用:ソフトウェアやコードを商用利用することが許可されています。
改変:ソフトウェアやコードを自由に修正したり改変したりすることができます。
配布:修正したり変更したりしたソフトウェアを自由に配布することができます。
著作権表示:再配布時に、著作権の表示や契約書コピーの提供などが必要になります。
特許利用:特許利用に関する明示的な規定はありません。
詳細は「META LLAMA 3.1 COMMUNITY LICENSE」のページをご確認ください。
Llama 3.1のモデル申請

Llama 3.1のモデルの利用申請をします。
HuggingFaceにログインして、Llama 3.1のモデルページにアクセスします。

Llama 3.1のモデルページで、「Expand to review and access」ボタンを押して展開します。
ページの下のほうに進むと入力フォームがありますので、
「ユーザー情報」を入力し、「ライセンス条項の同意文」にチェックを入れて、「Submit」ボタンをクリックします。
「Access granted」というタイトルで承認通知メールが届いたら、モデルの利用承認が完了です。
利用承認が得られたら、HuggingFaceのLlama 3.1のモデルページに「Granted model」と表示がされます。
Llama 3.1の使い方

ここからLlama 3.1を使ったテキスト生成(推論)について解説していきます。
Ollamaを使ってChatGPTのような画面でテキスト生成をする方法は、別の記事で解説しています。

実行環境
この記事で用意した実行環境は以下のとおりです。
- GPU:NVIDIA A100 80GB
- GPUメモリ(VRAM):80GB
- OS :Ubuntu 22.04
- Docker
Dockerで環境構築
Dockerを使用してLlama 3.1の環境構築をします
Dockerの使い方は以下の記事をご覧ください。

コンテナにインストールするパッケージは以下のとおりです。
CUDA、PyTorch、Transformersはバージョン依存関係によるエラーが起きやすいので、動作検証済のバージョン指定してインストールしています。
- CUDA:12.1
- Python:3.10
- PyTorch:2.2.2
- transformers:4.44.0
- accelerate
- bitsandbytes
Ubuntuのコマンドラインで、Dockerfileを作成します。
mkdir llama31_inference
cd llama31_inference
nano DockerfileDockerfileに以下の記述を貼り付けます。
# ベースイメージ(CUDA)の指定
FROM nvidia/cuda:12.1.0-cudnn8-devel-ubuntu22.04
# 必要なパッケージをインストール
RUN apt-get update && apt-get install -y python3-pip python3-venv git nano
# 作業ディレクトリを設定
WORKDIR /app
# アプリケーションコードをコピー
COPY . /app
# Python仮想環境の作成
RUN python3 -m venv /app/.venv
# 仮想環境をアクティベートするコマンドを.bashrcに追加
RUN echo "source /app/.venv/bin/activate" >> /root/.bashrc
# JupyterLabのインストール
RUN /app/.venv/bin/pip install Jupyter jupyterlab
# PyTorchのインストール
RUN /app/.venv/bin/pip install torch==2.2.2 torchvision==0.17.2 torchaudio==2.2.2 --index-url https://download.pytorch.org/whl/cu121
# Transformer関連のインストール
RUN /app/.venv/bin/pip install transformers==4.44.0 accelerate bitsandbytes
# コンテナの起動時にbashを実行
CMD ["/bin/bash"]docker-compose.ymlでDockerコンテナの設定をします。
docker-compose.ymlのYAMLファイルを作成して開きます。
nano docker-compose.yml以下のコードをコピーして、YAMLファイルに貼り付けます。
services:
llama31_iference:
build:
context: .
dockerfile: Dockerfile
image: llama31_inference
runtime: nvidia
container_name: llama31_inference
ports:
- "8888:8888"
volumes:
- .:/app/llama31_inference
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: 1
capabilities: [gpu]
command: >
bash -c '/app/.venv/bin/jupyter lab --ip="*" --port=8888 --NotebookApp.token="" --NotebookApp.password="" --no-browser --allow-root'Dockerfileからビルドしてコンテナを起動します。
docker compose up
Dockerの起動後にブラウザの検索窓に”localhost:8888″を入力すると、Jupyter Labをブラウザで表示できます。
localhost:8888Llama 3.1の実装
Dockerコンテナで起動したJupyter Lab上でLlama 3.1の実装をします。
Jupyter Labのコードセルに次のコマンドを実行して、ライブラリをインポートします。
import transformers
import torch
from torch import cuda,bfloat16Llama 3.1のモデルをダウンロードして読み込みます。
token = "******************************"
model_id = "meta-llama/Meta-Llama-3.1-8B-Instruct"
pipeline = transformers.pipeline(
"text-generation",
model=model_id,
token=token,
model_kwargs={"torch_dtype": torch.bfloat16},
device_map="auto",
)token = “******************************”
Hugging Faceのアクセストークンを定義。******に実際のトークン値が入ります。
model_id = “meta-llama/Meta-Llama-3.1-8B-Instruct”
Llama 3.1のモデルタイプを指定します。
transformers.pipeline()
テキスト生成タスクのためのTransformerのパイプラインを設定しています。
model_kwargs={"torch_dtype": torch.bfloat16}データ型をBF16に指定しています。量子化を行う場合は引数に"quantization_config": {"load_in_4bit": True}を加えてください。
Hugging Faceのアクセストークンの発行方法は、別の記事で解説しています。

モデルを読み込む際にGPUメモリを消費しますので、余裕を持ったGPUメモリをご用意ください。
| モデルサイズ | FP16 | FP8 | INT4 |
|---|---|---|---|
| meta-llama/Meta-Llama-3.1-8B-Instruct | 16GB | 8GB | 4GB |
| meta-llama/Meta-Llama-3.1-70B-Instruct | 140GB | 70GB | 35GB |
| meta-llama/Meta-Llama-3.1-405B-Instruct | 810GB | 405GB | 203GB |
Llama 3.1でテキスト生成

Llama 3.1を使って、日本語での質問応答、コード生成を試してみます。
日本語での質問応答(1)
「ラマとアルパカの違いについて教えて下さい。」というプロンプトを実行してみます。
messages = [
{"role": "system", "content": "あなたは日本語で回答するアシスタントです"},
{"role": "user", "content":"ラマとアルパカの違いについて教えて下さい。"},
]
prompt = pipeline.tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
terminators = [
pipeline.tokenizer.eos_token_id,
pipeline.tokenizer.convert_tokens_to_ids("<|eot_id|>")
]
outputs = pipeline(
prompt,
max_new_tokens=512,
eos_token_id=terminators,
do_sample=True,
temperature=0.6,
top_p=0.9,
)
print(outputs[0]["generated_text"][len(prompt):])messages
モデルへのプロンプトを定義しています。
pipeline.tokenizer.apply_chat_template
Llama 3.1のチャットテンプレートを適用してプロンプトを作成しています。モデルによって異なります。
terminators
生成されたテキストの終了を示すトークンを定義しています。これがないと延々とテキストが生成されます。
pipeline
Transformerのパイプラインを実行してテキストを生成します。出力するトークン数や生成確率などを指定できます。
ラマとアルパカの違いについて教えて下さい。
ラマとアルパカは、両方とも羊の仲間である動物です。両者は南米のアンデス山脈に生息する動物ですが、形態や性質では少し異なっています。
ラマ
ラマは、家畜として利用されている動物で、体高は1.7mから1.8m、体重は200kgから300kg程度です。毛色は黒、白、茶色、褐色など、多様な色の個体が存在します。ラマは、家畜として農業や乗馬に利用されています。ラマは、食料や乗馬に適した体格を持ち、かつ、温暖な気候でも生息できるため、ラマは家畜として重要な役割を果たしています。
アルパカ
アルパカは、ラマよりも小型の動物で、体高は1.2mから1.5m、体重は80kgから120kg程度です。毛色は白、黒、茶色など、ラマと同様に多様な色の個体が存在します。アルパカは、高山地帯に生息する動物で、寒冷な気候に適応した体質を備えています。アルパカは、家畜としてはあまり利用されておらず、観光や保護の対象として知られています。
主な違い
ラマとアルパカの主な違いは、体格と生息地です。ラマは家畜として利用されている大型の動物で、温暖な気候に適応しています。一方、アルパカは小型の動物で、寒冷な高山地帯に生息しています。
日本語での質問応答
「CRM(顧客管理)システムのFAQを作成お願いします。」というプロンプトを実行してみます。
messages = [
{"role": "system", "content": "あなたは日本語で回答するアシスタントです"},
{"role": "user", "content":"CRM(顧客管理)システムのFAQを作成お願いします。"},
]
prompt = pipeline.tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
terminators = [
pipeline.tokenizer.eos_token_id,
pipeline.tokenizer.convert_tokens_to_ids("<|eot_id|>")
]
outputs = pipeline(
prompt,
max_new_tokens=512,
eos_token_id=terminators,
do_sample=True,
temperature=0.6,
top_p=0.9,
)
print(outputs[0]["generated_text"][len(prompt):])CRM(顧客管理)システムのFAQを作成お願いします。
CRM(顧客管理)システムのFAQを作成します。
**Q1: CRMとは何ですか?**
A1: CRM(顧客管理)は、顧客情報を管理するために使用されるソフトウェアです。顧客情報、販売、サポート、市場分析などを管理するために使用されます。
**Q2: CRMの目的は何ですか?**
A2: CRMの主な目的は、顧客との関係を強化し、顧客のニーズを理解し、顧客の購入履歴や購入予定情報を管理することです。
**Q3: CRMの機能は何ですか?**
A3: CRMの主な機能は以下のとおりです。
– 顧客情報の管理
– 売上管理
– サポート管理
– マーケティング管理
– 分析とレポート
**Q4: CRMを導入するメリットは何ですか?**
A4: CRMを導入するメリットは以下のとおりです。
– 顧客との関係を強化する
– 顧客のニーズを理解し、対応する
– 売上の増加
– 時間の効率化
– 組織の統合
**Q5: CRMを導入する方法は何ですか?**
A5: CRMを導入する方法は以下のとおりです。
– CRMの選択
– システムの設定
– データの移行
– スタッフのトレーニング
– システムの運用
**Q6: CRMを使用するメリットは何ですか?**
A6: CRMを使用するメリットは以下のとおりです。
– 顧客との関係を強化する
– 顧客のニーズを理解し、対応する
– 時間の効率化
– 組織の統合
– 顧客サービスの向上
**Q7: CRMを使用するコストは何ですか?**
A7: CRMを使用するコストは、システムの購入費や月々のサブスクリプション料金などに変わります。
**Q8: CRMのセキュリティはどうですか?**
A8: CRMのセキュリティは、企業のデータを保護するために
コード生成
「Pytorchの損失関数を3つ挙げて、それぞれの使い方を教えて下さい。」というプロンプトで質問を投げてみます。
messages = [
{"role": "system", "content": "あなたは日本語で回答するアシスタントです"},
{"role": "user", "content":"Pytorchの損失関数を3つ挙げて、それぞれの使い方を教えて下さい。"},
]
prompt = pipeline.tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
terminators = [
pipeline.tokenizer.eos_token_id,
pipeline.tokenizer.convert_tokens_to_ids("<|eot_id|>")
]
outputs = pipeline(
prompt,
max_new_tokens=512,
eos_token_id=terminators,
do_sample=True,
temperature=0.6,
top_p=0.9,
)
print(outputs[0]["generated_text"][len(prompt):])Pytorchの損失関数を3つ挙げて、それぞれの使い方を教えて下さい。
モデルの応答
PyTorchでは、さまざまな損失関数を使用することができます。以下は3つの例を紹介します。
### 1. 平均二乗誤差 (MSE: Mean Squared Error)
平均二乗誤差は、2つのベクトルの差の二乗の平均を取ることで計算されます。MSEは回帰問題でよく使用されます。
```python
import torch
import torch.nn as nn
# 損失関数の定義
criterion = nn.MSELoss()
# 損失計算
output = torch.randn(1, 5) # 出力
target = torch.randn(1, 5) # 目標
loss = criterion(output, target)
print(loss)
```
### 2. 交差エントロピー誤差 (Cross Entropy Loss)
交差エントロピー誤差は、クラスラベル分類問題でよく使用されます。PyTorchでは、`nn.CrossEntropyLoss()`関数を使って交差エントロピー誤差を計算できます。
```python
import torch
import torch.nn as nn
# 損失関数の定義
criterion = nn.CrossEntropyLoss()
# 損失計算
output = torch.randn(1, 5) # 出力
target = torch.tensor([1]) # 目標
loss = criterion(output, target)
print(loss)
```
### 3. 二乗誤差 (L1 Loss: Mean Absolute Error)
二乗誤差は、2つのベクトルの差の絶対値の平均を取ることで計算されます。L1損失は回帰問題でよく使用されます。
```python
import torch
import torch.nn as nn
# 損失関数の定義
criterion = nn.L1Loss()
# 損失計算
output = torch.randn(1, 5) # 出力
target = torch.randn(1, 5) # 目標
loss = criterion(output, target)
print(loss)
```
これらの損失関数を使用するには、まずPyTorchの`nn`モジュールをインポートし、指定した損失関数をインスタンス化する必要があります。次に、指定された入力と目標の値を指定して、損失関数の`forward`メソッドを生成AI・LLMのコストでお困りなら
GPUのスペック不足で生成AIの開発が思うように進まないことはありませんか?
そんなときには、高性能なGPUをリーズナブルな価格で使えるGPUクラウドサービスがおすすめです!

GPUSOROBANは、高性能GPU「NVIDIA H200」を業界最安級の料金で使用することができます。
NVIDIA H200は、生成AI・LLMの計算にかかる時間を大幅に短縮することが可能です。
クラウドで使えるため、大規模な設備投資の必要がなく、煩雑なサーバー管理からも解放されます。







