
PICSOROBAN(ピクソロ)は、インストール不要で、Webブラウザさえあれば、誰でも簡単に使える画像生成AIツールです。
この記事では、PICSOROBANを使いこなして、高品質な画像を誰でも作れるようになるためのポイントを解説します。
- VAE/Embedding/LoRAを使って生成画像の品質を上げる方法
- ControlNetを使って自由に線画やポーズを抽出する方法
- ADetailerを使って表情差分を作成する方法

画像生成AI「PICSOROBAN」とは

PICSOROBAN(ピクソロ)は、Stable Diffusionを簡単に利用できる画像生成AI サービスです。
通常、Stable Diffusionを使うためには高スペックのパソコンが必要ですが、PICSOROBANなら、特別な準備も不要で、今のパソコンのまま、美しい画像を簡単に作り出せます。
この記事ではPICSOROBANの使い方「中級編」を紹介します。
基本的な使い方や特徴は、下記の記事で紹介していますのでまだご覧になっていない方はぜひご確認ください。


Stable Diffusionの使い方は、機能別に下記の記事にまとめているのでぜひご覧ください

PICSOROBANで使える追加学習モデルデータ

Stable Diffusion Web UI には、生成画像の質を上げるさまざまな機能があります。
ここからは、PICSOROBANでの追加学習モデルデータの使い方を紹介していきます。
追加学習機能に関しては下記の記事で概要を紹介しているので、ご興味がある方はぜひご覧ください。

VAEの使い方
VAEとは、プロンプトで調整できない画像品質を向上させるツールです。
VAEを利用することで、画像生成AIでよく見られる「くすみ」や「彩度の低さ」といった問題を改善し、鮮やかで明るくクリアな画像に仕上げることが可能です。
VAEの導入は簡単です。配布されているモデルデータをダウンロードし、PICSOROBANにアップロードすることで利用できます。
モデルデータごとに特徴が異なるため、配布元の説明を確認し、目的に合わせて最適なものを選びましょう。
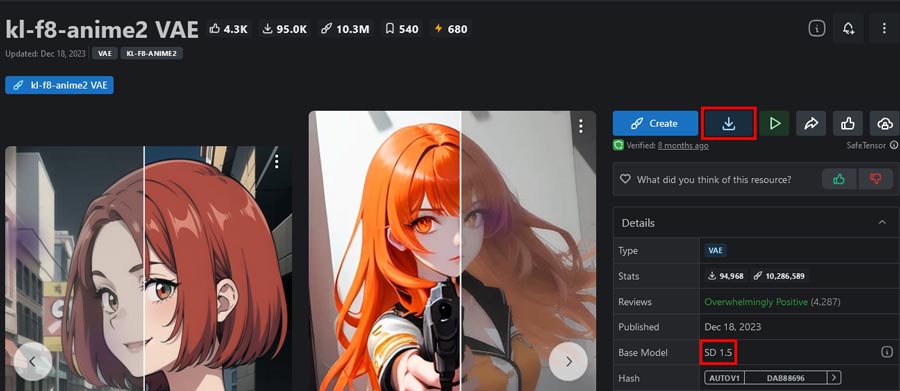
VAEのモデルデータは、主にHuggingFaceやCivitaiで配布されています。
ダウンロードのボタンをクリックしてデータを入手します。
PICSOROBANは、SD1.5のモデルデータに対応しているため、ベースモデルのバージョンを確認しましょう。
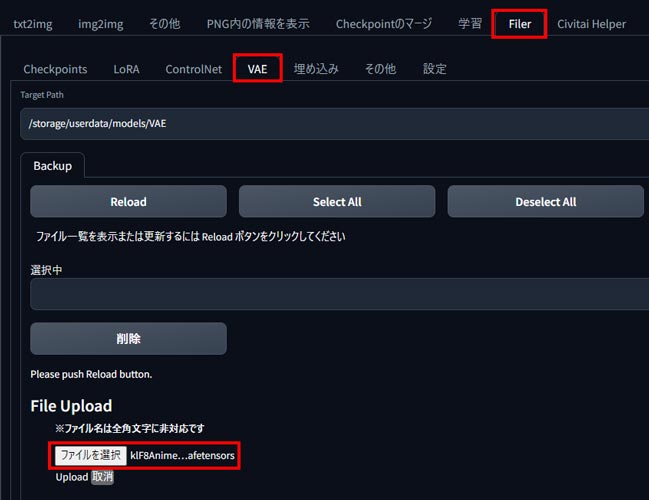
次に、PICSOROBANの「Filerタブ」から「VAEタブ」を選択し、モデルファイルをアップロードします。
「ファイルを選択」ボタンから先ほどダウンロードしてきたモデルファイルを読み込んで、Uploadをクリックします。
VAEは、ファイルを指定することで生成に反映されます。画像生成時にモデルファイルを選択する必要があります。

実際にVAEを使用しない場合とする場合で画像を比較してみます。
使用しているモデルデータは以下の通りです。
- checkpoint「AnythingXL_v50.safetensors」
- VAE「klF8Anime2VAE_klF8Anime2VAE」

VAEを使用すると、全体的に鮮やかになり、画像全体のくすみがなくなりました。
VAEに関しては、下記の記事でも紹介していますのでぜひご覧ください。

Embeddingの使い方
Embeddingは、AIにおいて「埋め込み表現」と呼ばれる技術です。
通常、複雑なプロンプトを入力するには時間や手間がかかりますが、Embeddingを使うことで、それらの表現を一つにまとめ、簡単に再利用できます。
EmbeddingもVAEと同様に、配布されているモデルデータをダウンロードして、PICSOROBANにアップロードすることで利用できます。
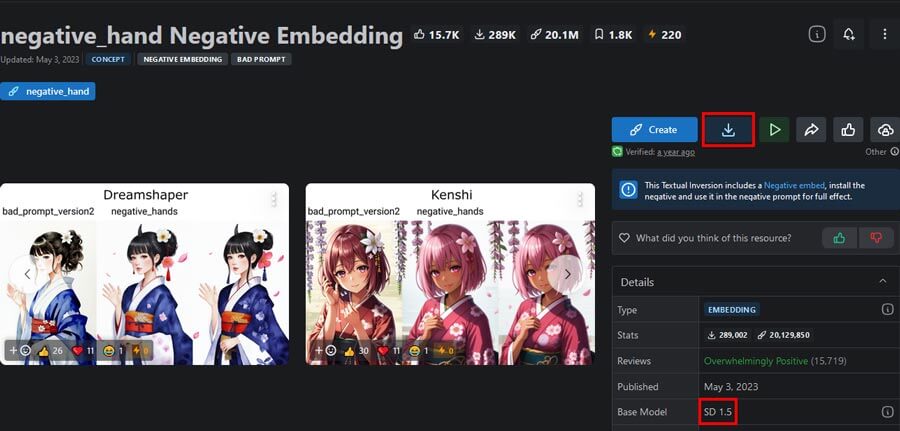
Embeddingのモデルデータは、主にHuggingFaceやCivitaiで配布されています。
ダウンロードのボタンをクリックしてデータを入手します。
PICSOROBANは、SD1.5のモデルデータに対応しているため、ベースモデルのバージョンを確認することが重要です。
次に、PICSOROBANのFilerから「埋め込みタブ」を選び、モデルファイルをアップロードします。
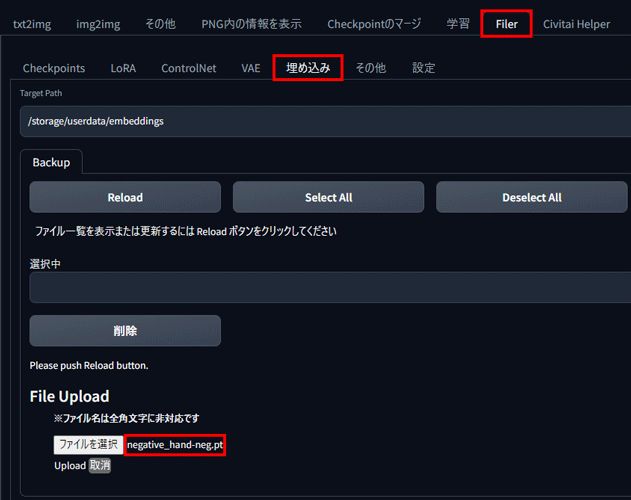
「ファイルを選択」ボタンから先ほどダウンロードしてきたモデルファイルを読み込んで、Uploadをクリックします。
Embeddingは、プロンプト内に単語を入力することで生成に反映できます。
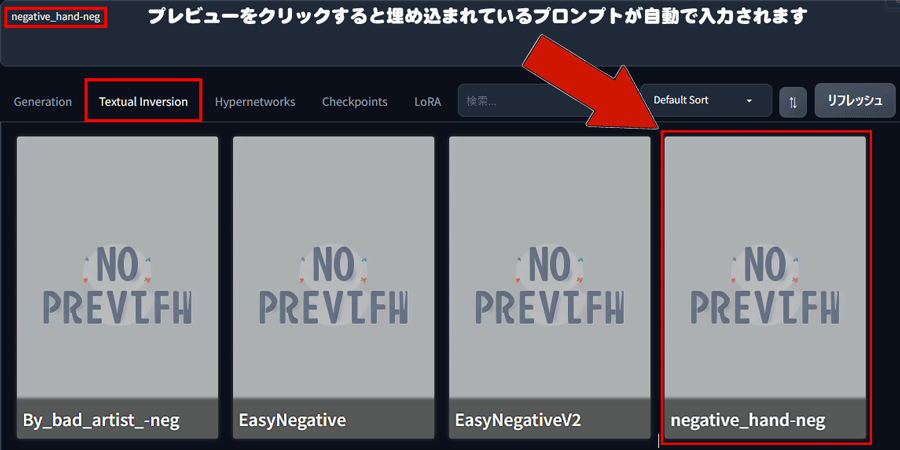
txt2imgの下部にある「Textual Inversion」タブを選択して一覧を表示します。
プロンプト欄にカーソルを合わせてプレビュー画面をクリックすると、プロンプトにEmbedding単語が入力されます。
実際にEmbeddingを使用しない場合と使用した場合で画像を比較してみます。
今回は、手の崩れや形状を修正してくれるEmbeddingを使用します。
使用しているモデルデータは以下の通りです。
- checkpoint「AnythingXL_v50.safetensors」
- Embedding「negative_hand-neg」

Embeddingを使用した結果、指の数が不自然に生成されていた部分が修正され、正常な見た目になりました。
また、爪部分など細かい部分で綺麗になるように補正されています。
PICSOROBANにプリインストールされている「EasyNegative」に関しては下記の記事で詳しく紹介しています。

LoRAの使い方
LoRAとは「Low-Rank Adaptation」の略で、モデルに追加学習を行い、独自のコンセプトやスタイルを画像生成に反映させることができる技術です。
LoRAはCheckpointに対して追加学習データを適用するため、対応するCheckpointとセットで利用するのが理想的です。
この組み合わせによって、LoRAの効果を最大限に引き出すことができ、より正確なスタイルを再現できます。
LoRAのモデルデータは主にHuggingFaceやCivitaiで配布されています。
配布ページからダウンロードのボタンをクリックしてデータを入手しましょう。
PICSOROBANは、SD1.5のモデルデータに対応しているため、ベースモデルのバージョンを確認することが重要です。
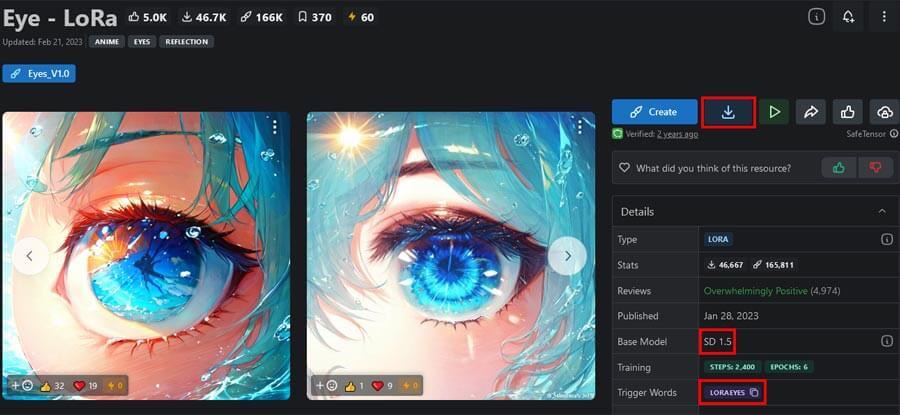
その後、PICSOROBANの「Filerタブ」から「LoRAタブ」を選択してモデルファイルをアップロードします。
「ファイルを選択」ボタンから先ほどダウンロードしてきたモデルファイルを読み込んで、Uploadをクリックします。
LoRAを使用するためには、プロンプト内にLoRAタグとトリガーワードを入力する必要があります。
以下の手順でLoRAを反映させましょう。
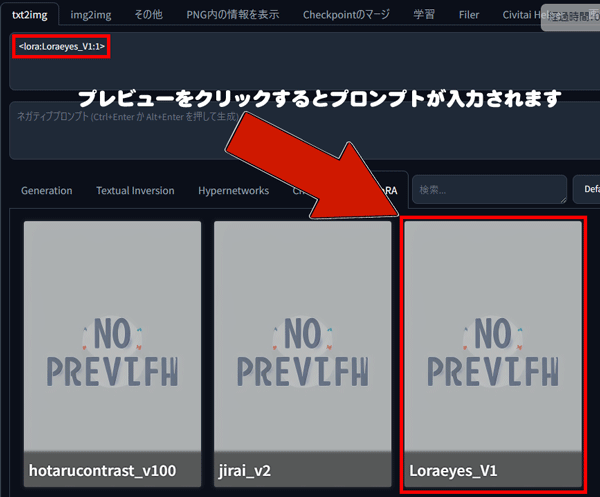
PICSOROBANのtxt2imgの下部にある「LoRA」タブを選択して、利用可能なLoRAの一覧を表示します。
プロンプト欄にカーソルを合わせてプレビュー画面をクリックすると、選択したLoRAタグが自動で入力されます。
例:< lora:Loraeyes_V1:1 >のようにLoRA名:数字の形式で表示されます。
数字部分は、LoRAの反映強度を表し、0.8(弱)~1.3(強)の範囲内で調整します。
トリガーワードは、自身でプロンプト欄へ入力します。
※トリガーワードは、配布されている紹介ページのバージョン表記の下に表示されています。
実際にLoRAを使用しない場合と使用した場合の画像を比較してみましょう。
今回は、輝きを加えてくれるLoRAを使用しました。
使用しているモデルデータは以下の通りです。
- checkpoint「AnythingXL_v50.safetensors」
- LoRA「Eye – LoRa」

LoRAを適用することで、目の描写が細かく、キレイな見た目に仕上がりました。
LoRAは、追加学習データとして動作するため、同じ内容のプロンプトでもCheckpointとの相性によって画風そのものが変化してしまうことがあります。最適な組み合わせを試してみましょう。
LoRAに関しては下記の記事で詳しく紹介しているため、より詳細を知りたい人はぜひご覧ください。

\登録はこちら/

「PICSOROBAN」に導入したいおすすめ拡張機能

Stable Diffusion Web UI には、初期機能のほかにカスタマイズできる拡張機能があります。
ここからはPICSOROBANで使えるおすすめの拡張機能を紹介していきます。
ControlNet
ControlNetは、Stable Diffusionの拡張機能で、生成する画像に対して細かい条件を指定できる強力なツールです。
ポーズや構図の指定、画風の変更、線画抽出など、通常のプロンプトでは難しい要素を反映することが可能です。
この機能を使うことで、より細部にこだわった画像を生成できます。
PICSOROBANにControlNetをインストール
PICSOROBANにControlNetをインストールする手順を紹介します。
容量はモデルデータを含めて10Gほど使用しますので、インストールする前に使用中の容量を確認しましょう。
拡張機能タブから「URLをインストールする」を選びます。
「拡張機能のリポジトリのURL」入力欄に次のアドレスを入力し、「インストール」ボタンをクリックします。
https://github.com/Mikubill/sd-webui-controlnet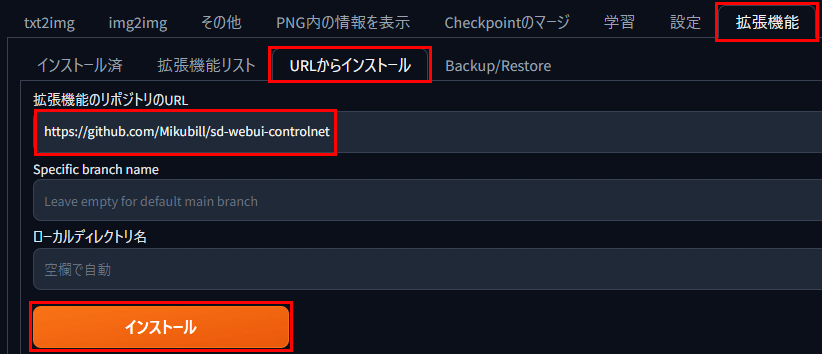
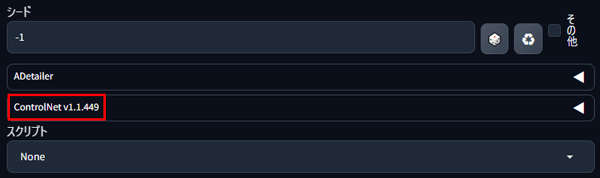
ControlNetのインストールが完了したら「インストール済」タブに移動し、「適用して再起動」ボタンをクリックしてPICSOROBANを再起動します。

PICSOROBANを再起動し、シード値の下にControlNetタブが表示されていればインストール完了です。
PICSOROBANにControlNet用のモデルを追加する
ControlNetを利用するには、使いたい機能に対応したControlNet専用のモデルを追加する必要があります。
PICSOROBANは、SD1.5用ControlNetモデルデータを使用します。
SD1.5用ControlNetモデルデータ
https://huggingface.co/comfyanonymous/ControlNet-v1-1_fp16_safetensors/tree/main
ControlNetには、さまざまなモデルが公開されています。
例えば、ControlNetの「OpenPose」が使いたい場合は、リンク先のファイルから「OpenPose」と名前が追加ファイルをダウンロードします。
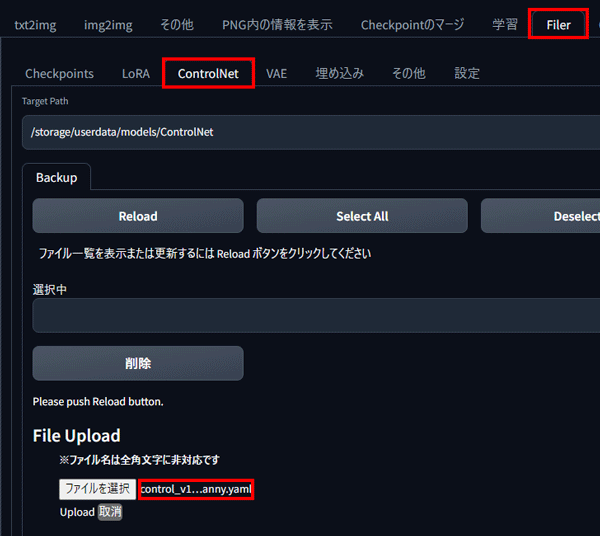
ダウンロード後は、PICSOROBANの「Filerタブ」から「ControlNetタブ」を選択してアップロードします。
「ファイルを選択」ボタンから先ほどダウンロードしてきたファイルを選択して、Uploadをクリックします。
【ControlNet】Cannyの使い方

Cannyは、元の画像から輪郭線を抽出し、新たに画像を生成する機能です。
デザイン線画を元に画像を再生成することで、塗り方のパターンを増やすことができます。
ControlNet Cannyの基本的な使い方を解説します。
線画作成から着色する方法
まずは、Cannyで使用するモデルデータをHuggingFaceからダウンロードします。
- control_v11p_sd15_canny.yaml
- control_v11p_sd15_canny.pth
PICSOROBANにControlNetがインストールされている場合、「◀マーク」をクリックしてControlNetパネルを開きます。
線画を抽出したい画像を左側にドラッグ&ドロップします。
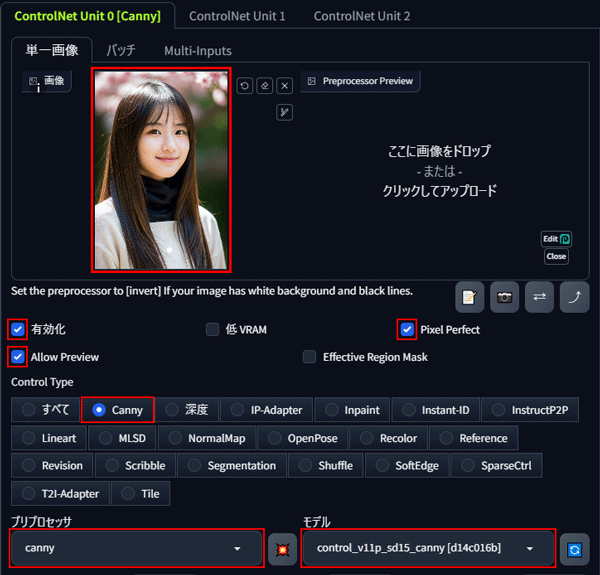
「有効化」、「Pixel Perfect」、「Allow Preview」、「Canny」にチェックを入れます。
プリプロセッサに「canny」、モデルに「control_v11p_sd15_canny」を選択します。
選択が完了したら、真ん中の「💥ボタン」を押して線画を抽出します。
右側に白黒の線画が表示されれば抽出完了です。

Cannyによる線画抽出が完了したら、プロンプト入力欄に移動して変更したい内容を入力します。
今回は、この線画に対して髪色をシルバーに変更します。
[silver hair color]
しばらく待つと生成が完了します。体の線はしっかり保持され、髪色のみがシルバーに変更されました。

指定していない部分は、髪色に合わせて自動的に変更されています。
必要に応じて、維持したい部分は、プロンプトで指定したり、シード値を固定すると良いでしょう。
詳しいCannyの使い方は、ぜひ下記の記事を参考にしてくださいね。

【ControlNet】OpenPoseの使い方
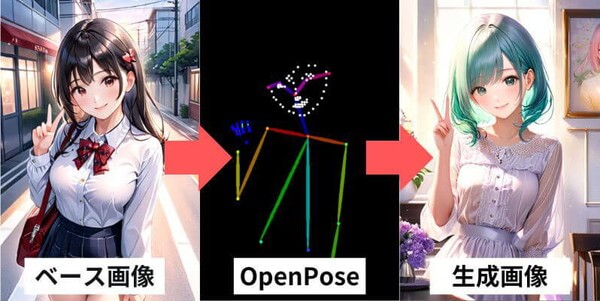
OpenPoseとは、元画像からポーズを抽出して、そのポーズを新たな画像に反映させるControlNetの機能です。
複雑な構図やポーズをプロンプトで指定する手間を省けるため、非常に便利です。
棒人間のフレームをベースに画像を生成する方法
ここからは、OpenPoseの基本的な使い方を解説していきます。
まずは、OpenPoseで使用するモデルデータをHuggingFaceからダウンロードします。
- control_v11p_sd15_openpose.yaml
- control_v11p_sd15_openpose.pth
PICSOROBANでControlNetがインストールされている場合、「◀マーク」をクリックしてControlNetパネルを開きます。
ポーズを抽出したい画像を左側にドラッグ&ドロップします。
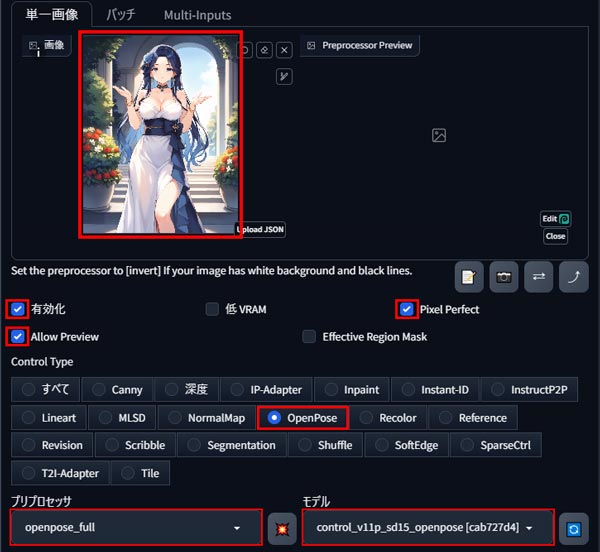
「有効化」、「Pixel Perfect」、「Allow Preview」、「OpenPose」にチェックを入れます。
プリプロセッサに「openpose_full」、モデルに「control_v11p_sd15_openpose」を選択します。
選択が完了したら、真ん中の「💥ボタン」を押して線画抽出を開始します。
右側に棒人間の画像が表示されたらポーズの抽出が完了です。

OpenPoseによるポーズの抽出が完了したら、プロンプト入力欄に移動して変更したい内容を入力します。
今回は、実写風の人物にこのポーズを反映して生成します。
[((asian face)), (realistic, photo-realistic:1.37),best quality, 1girl, (skindentation), (dark night), blur background, outdoor, (street:0.6), (people, crowds:1), (oversize shirt:1.5), gorgeous, (white hair:1.5), (dynamic pose:0.8), finely detail, official art, absurdres, incredibly absurdres, war city, extremely detailed eyes and face, beautiful detailed eyes,plugsuit, medium hair, bodysuit, ((ultra realistic details)), portrait, 8k,sun flare, soft shadows, vibrant colors, painterly effect, high rise building, reflection, sunlit clouds, peaceful ambiance, idyllic night, ultra sharp, cold colour, highly intricate details, realistic light, ((sit at old tank)) (8k, best quality), ultra-detailed, from the front, beautiful girl wearing a black shirt, ((black pants)), ((in the dark city)), cyberpunk theme]
しばらく待つと生成が完了します。ポーズはそのままに、人物や背景が変更できます。
元のポーズを維持しながら、さまざまな場面を簡単に再現することができます。

【ControlNet】Lineartの使い方
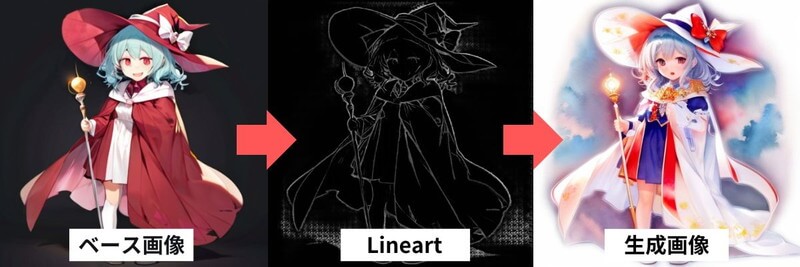
Lineartは、元の画像から線画を抽出し、その線画を元に色を塗り直すことができるControlNetの拡張機能です。
Lineartを使用すると、背景や人の肌のような細かい線を含む線画を正確に抽出できます。
線画を抽出して色の塗り直しをする方法
ここからは、Lineartの基本的な使い方を解説していきます。
まずは、Lineartで使用するモデルデータをHuggingFaceからダウンロードします。
汎用性が高く、多くのモデルが公開されています。
- control_v11p_sd15_lineart_fp16
ControlNetがインストールされている場合、PICSOROBANにControlNetのパネルが表示されます。「◀マーク」をクリックしてパネルを開きます。
Lineartで線画を抽出したい画像を左側にドラッグ&ドロップします。
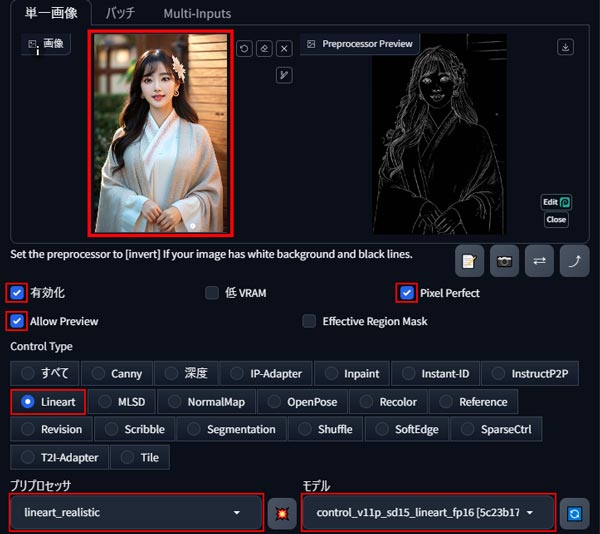
「有効化」、「Pixel Perfect」、「Allow Preview」、「Lineart」にチェックを入れます。
プリプロセッサに「lineart_realistic」、モデルに「control_v11p_sd15_lineart_fp16」を選択します。
選択が完了したら、真ん中の「💥ボタン」を押して線画を抽出します。
右側に白黒の線画が表示されたら、抽出は完了です。
線画には濃淡があり、奥行きまで表現されているのが特徴です。

※今回は実写の素材画像を使用しているので、プリプロセッサを「lineart_realistic」にしています。
Lineartによる線画抽出が完了したら、プロンプト入力欄に移動して変更したい内容を入力します。
今回は、線画を維持しつつアニメ風に変換します。
使用するCheckpoint:AnythingXL_v50.safetensors
[(masterpiece),((ultra-detailed)), (highly detailed CG illustration), (best quality:1.2), (Dynamic wide cowboy shot:1.4, ankle in of frame:1.3),Highest Quality, Highest quality, Highest Resolution, Perfect dynamic composition, Shoot from the most attractive perspective,Watercolor style, high-definition images, atmospheric perspective, 8k, super detail, accurate,Best quality details,8K UHD, High definition, hyperdetailed, High quality detailed texture, High quality shadow, Detailed beautiful delicate face, Detailed beautiful delicate eyes, 20’s, only one person, contrast, light and shadow contrast, dusk, (dark + private china courtyard + pavilion nearby + beam of light), hair stick, hairpin, hair ornaments, light smile, lovely face, slender face, fair white skin, glowing eyes, glossy lips, bags_under_eyes, pale pink lip, beautiful eyes, eyelashes, Thin lips, (noble girl), eyeshadow, makeup, eyeliner, shawl, hagoromo, hanfu, detailed clothes]
しばらく待つと生成が完了します。
線画をベースにして全体の特徴を維持しながら、アニメ風の画像を生成することができました。

詳しいLineartの使い方は、ぜひ下記の記事を参考にしてください。

ADetailer
ADetailerとは、キャラクターを固定したまま表情を自由に変えられる拡張機能です。
プロンプトの指示では反映がしづらい、眉毛、目、口など細かい表情までを変更でき、自然な仕上がりになります。
その他、顔や手の崩れを防ぐ機能もあります。
ADetailerのインストール方法
「拡張機能」タブを開いて「URLからインストール」タブを選択します。
拡張機能のリポジトリのURL欄に「https://github.com/Bing-su/adetailer」を入力してインストールを開始します。
https://github.com/Bing-su/adetailer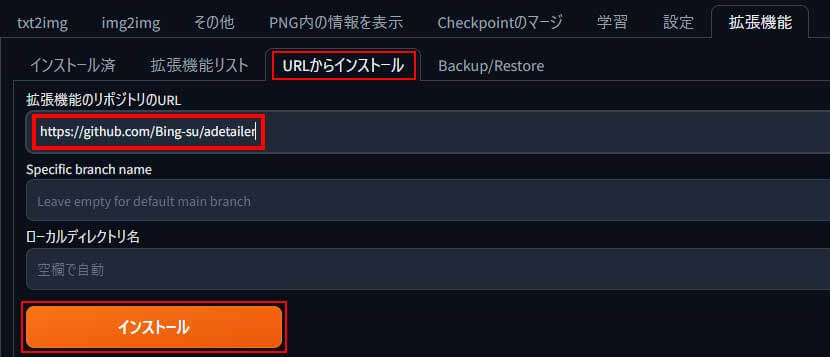
インストールが完了したら、PICSOROBANを再起動します。
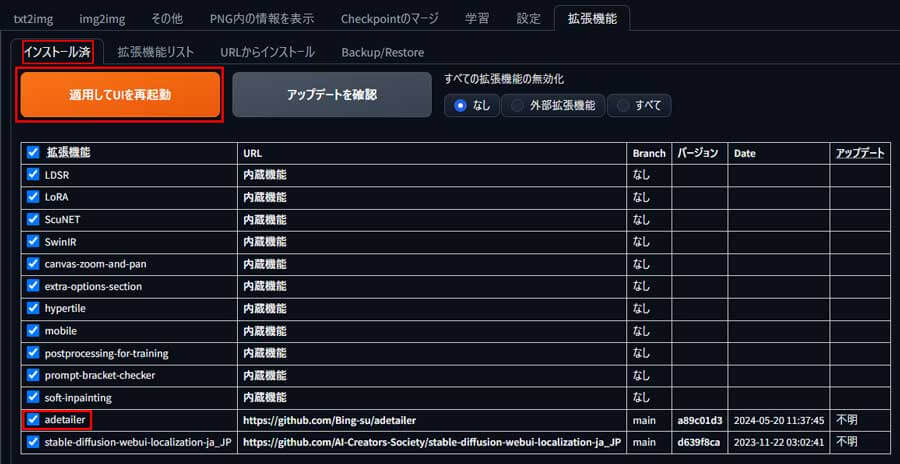
再起動後に「拡張機能」から「インストール済」タブを開いて「ADetailer」が表示されていることを確認します。
「適用してUIを再起動」ボタンをクリックしてPICSOROBANに反映させます。
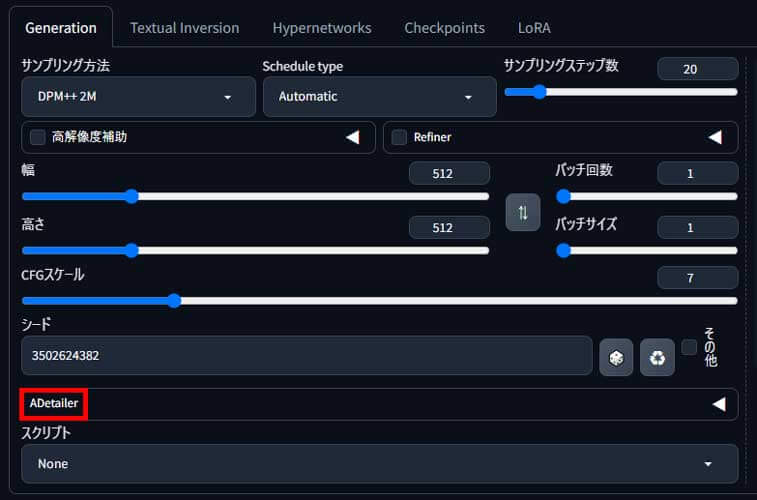
シードの下に「ADetailer」が表示されていれば準備完了です。
ADetailerの使用方法
ここからは、ADetailerを使って表情差分を生成する方法を紹介します。
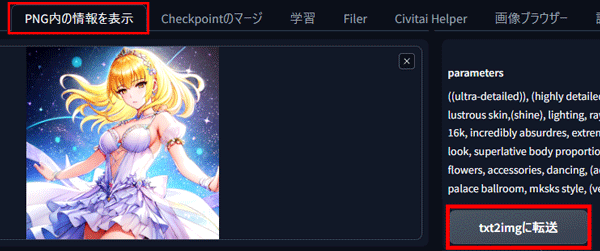
PICSOROBANの「PNG内の情報を表示」タブを開いて素材画像を読み込みます。
右側に表示される情報の下部に表示されている「txt2imgに転送」ボタンをクリックします。
その後、Seed値を固定します。
Seed値を固定方法に関しては、「Stable DiffusionのSeed値(シード値)とは?意味やおすすめの使い方を解説」で詳細を紹介しています。
「ADetailer」の◀をクリックしてメニューを開きます。
「Enable ADetailer」にチェックを入れて、 「face_yolov8n.pt」モデルを選択します。
※「face_yolov8n.pt」モデルはデフォルトで入っています。
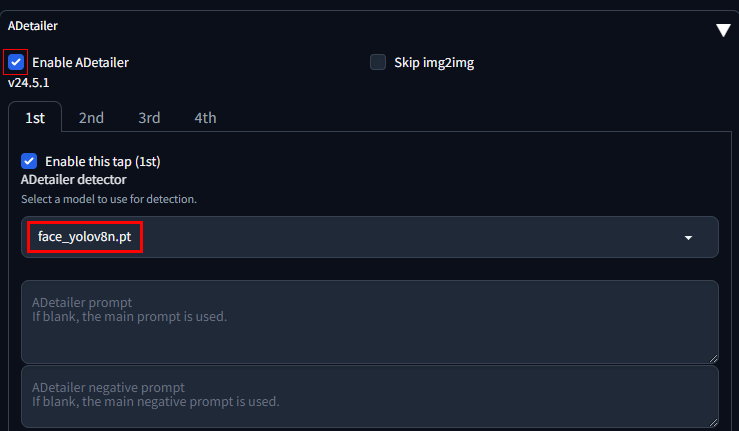
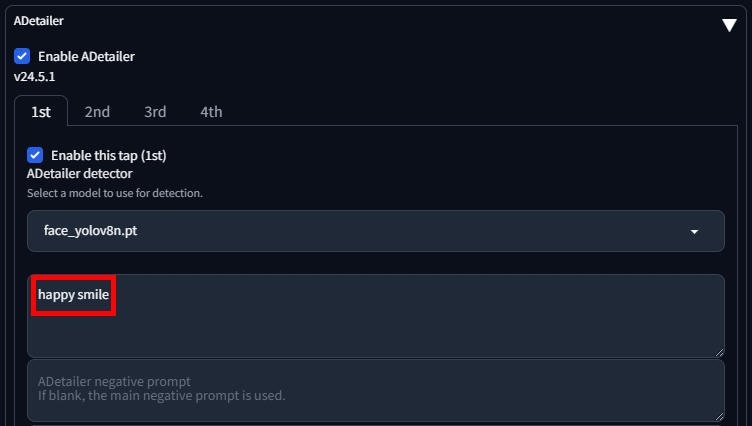
「ADetailer prompt」に表情を表すプロンプトを入力します。
例えば、「happy smile(幸せな笑顔)」と入力して生成を開始します。
表情が幸せな笑顔に変更されました!


Stable Diffusionの使い方は、機能別に下記の記事にまとめているのでぜひご覧ください
PICSOROBANを使いこなして画像生成の幅を広げよう!
今回は「PICSOROBAN」でツールを活用した画像生成の使い方を解説しました。
特に、VAEやLoRA、ControlNetなどのツールを駆使することで、さらに精度の高い画像を簡単に作成できます。
- VAE/Embedding/LoRAを使って生成画像の品質を上げる方法
- ControlNetを使って自由に線画やポーズを抽出
- ADetailerを使って表情差分を作成方法
ここで紹介した機能以外にもPICSOROBANには、多くの便利なツールや拡張機能が備わっています。
さまざまな拡張機能をカスタマイズして、PICSOROBANを極めましょう!
PICSOROBANは、インストールの必要なくブラウザで簡単にStable Diffusionを利用できます。
さらに、今ならリリースキャンペーンとして無料会員登録するだけで、2,000ポイント貰えます!
詳しい使い方は下記の記事で紹介しています。
\約2時間無料で使える!/







