
PICSOROBANは、テキストや画像からAIが画像を生成するStableDiffusion WebUIを使ったサービスで、誰でも簡単に画像生成を楽しむことができます。
この記事では、「PICSOROBAN」でプロンプト、パラメータ、拡張機能…あらゆる要素を掌握し、Stable Diffusionを完全に使いこなす方法を解説していきます。
- 思い通りのプロンプトを組み立てる方法
- ControlNetの使いこなす方法
- LoRAを使ってメリハリのある画像を生成する方法
画像生成AI「PICSOROBAN」とは

PICSOROBAN(ピクソロ)は、Stable Diffusionを簡単に利用できる画像生成AI サービスです。
通常、Stable Diffusionを使うためには高スペックのパソコンが必要ですが、PICSOROBANなら、特別な準備も不要で、今のパソコンのまま、美しい画像を簡単に作り出せます。
この記事ではPICSOROBANの使い方「上級編」を紹介します。
基本的な使い方を知りたい方は、「初級編」、拡張機能の基礎について知りたい方は「中級編」をぜひご確認ください。

Stable Diffusionの使い方は、機能別に下記の記事にまとめているのでぜひご覧ください

PICSOROBANにおける画像生成の基本

Stable Diffusionで、画像を生成する際にいくつか重要なポイントがあります。
わずかな設定の違いでも、画像の品質や特徴に大きな影響を与えることがあります。
PICSOROBANで対応しているSD1.5を基準に、主な要素と応用した使い方を解説していきます。
checkpoint(チェックポイント)
checkpointは、画像生成に必要な学習済みパラメータを含んでいる、いわば「脳」ともいえる部分です。
より洗練されたcheckpointを使用することで、パフォーマンスと品質が向上します。
画風や画像スタイルを安定させるためには、checkpointを固定しておくことをおすすめします。
PICSOROBANで使えるおすすめcheckpoint
PICSOROBANで使えるおすすめのcheckpointモデルを紹介します。
アニメ・イラスト系やフォトリアル系など、異なるジャンルのモデルをそれぞれの特徴とともに解説します。
アニメ・イラスト系checkpoint
HotaruBreed CuteAnimeMix
HotaruBreed CuteAnimeMixで作成した画像!
バックパッカー
backpacker

ファンタジー
fantasy girl

姉妹
sisterhood

カップル
couple

HotaruBreed は、テレビアニメのような画風を再現できるcheckpointモデルです。
線の細さと塗りに特徴があります。
kawaiiRealisticAnime
kawaiiRealisticAnimeで作成した画像!
予言者
spakona

ギターを弾く女の子
gitar girl

探偵
detective

エルフ
elf

kawaiiRealisticAnimeは、光の当たり具合や光彩が細かく描かれるcheckpointモデルです。
また、プロンプト次第で2.5Dのスタイルに近づけることも可能で、アニメとリアルな質感の中間的な描写を表現することができます。
ligneClaireAnime
ligneClaireAnimeで作成した画像!
姫
prince

猫
colorful cat

暗殺者
assassin

バーガーショップ
burger shop

ligneClaireAnimeは、イラスト塗りに特徴を持つcheckpointモデルです。
特に、細かい配色やグラデーションが美しく表現され、鮮やかに描かれます。
フォト・リアル系checkpoint
majicmixLux_v3
majicmixLux_v3で作成した画像!
モデル
fashion model

未来の警官
futuristic police

アイドルグループ
idol group
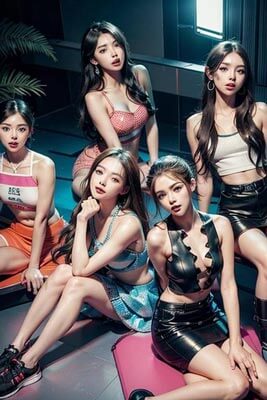
未来型ロボット
robot

majicmixLux_v3は、人物の描写に特化したcheckpointモデルです。
特に、近代的なファッションやレンドに合わせたメイクを施した顔が多く学習されています。
chilled_re-generic_v3
chilled_re-generic_v3で作成した画像!
西洋人
Westerner

車
super car

不気味な影
eerie shadow

写実的な女性
realistic woman

kawaiiRealisticAnimeは、現実離れしたポスターや構図などを得意とするcheckpointモデルです。
リアルよりも近未来やファンタジーのエフェクトなどを得意としています。
おすすめのcheckpointは下記の記事でも紹介していますのでぜひご覧ください。



プロンプトの組み立て方
PICSOROBANで画像生成を行う際に、最も重要な要素としてプロンプト(通称:呪文)が挙げられます。
プロンプトの内容次第で、生成される画像の品質や特徴が大きく左右されます。
思い通りに画像を生成するための基本的なポイントについては、Stable Diffusion(Stability AI社)が公開しているプロンプトガイドラインに沿って解説していきます。
Stable Diffusionのプロンプトは、75単語で1グループとして認識され、基本的に前に記述した単語が優先され、後ろの単語は優先度が低くなります。
画像に関する情報は、なるべく多く入力する必要があります。
例えば、人物の特徴だけを入力すると、背景や服装、品質などは自動で補完されてしまいます。
実際に、入力例のプロンプト(呪文)を各要素に分けて解説していきます。
生成した妖精風のアニメイラスト!

((ultra-detailed)), (highly detailed CG illustration), (best quality:1.2),((masterpiece)),((best quality)),(ultra-detailed),(illustration),clear-cut margin,alphonse mucha,extremely detailed CG unity 8k wallpaper,((an extremely delicate and beautiful)),super fine, 16k, incredibly absurdres, extremely detailed, 2.5D, delicate and dynamic,1girl, solo, anime,(messy floating pink hair:1.3), Portrait,upper body,(arms behind back),perfect face,(beautiful detailed eyes),cute pink eyes,golden pupil,detailed face,white dress,disheveled hair,focus,sidelighting, lustrous skin,(shine), lighting, ray tracing,,(((Personage as the main perspective))),(((character in the middle))),(dynamic angle),An enchanted forest at night illuminated by glowing mushrooms,((Tyndall effect)),(Fluorescent mushroom forests background),(beautiful water),river,flying butterfly,sunlight,shine,chiaroscuro
out of focus, 3d model, poorly drawn, crossed eyes, painting, watermark, signature, split image, pixelized, blurry, (ugly:1.3), (duplicate:1.2), (mutilated:1.1), [out of frame], (bad face), extra fingers, mutated hands, (poorly drawn hands:1.1), (poorly drawn face:1.2), (mutation:1.3), (deformed:1.3),(bad anatomy:1.1), (bad proportions:1.2), (extra limbs:1.1), cloned face, (disfigured:1.2), out of frame, extra limbs, (bad anatomy), gross proportions, (malformed limbs), (missing arms:1.1), (missing legs:1.1), (extra arms:1.2), (extra legs:1.2), mutated hands, (fused fingers), (too many fingers), (long neck:1.2)
プロンプトの冒頭には、最も優先させたい要素を入力するため、まずは画像の品質を高める要素を入力します。
たとえば、「精密描写(ultra-detailed)」や「高品質(best quality)」など、品質に関わるプロンプトを入力することで、全体の仕上がりが向上します。
次の内容は、実写・アニメ・風景などで使い分けが必要になります。
品質に関するプロンプト
① ((ultra-detailed)), (highly detailed CG illustration), (best quality:1.2),((masterpiece)),((best quality)),(ultra-detailed),(illustration),clear-cut margin,alphonse mucha,extremely detailed CG unity 8k wallpaper,((an extremely delicate and beautiful)),super fine, 16k, incredibly absurdres, extremely detailed, 2.5D, delicate and dynamic,

次に、キャラクターの詳細な情報を入力します。
ここでは、一人の女性が被写体であることやアングルを指定します。
さらに、年齢、人種、身長などの情報もここで入力します。
人物の特徴に関するプロンプト
次の内容は、一人の女性キャラクターの特徴を指定するプロンプト例です。髪型や目の色、服装なども含めて詳細に入力することで、思い通りのキャラクターを生成できます。
②1girl, solo, anime,(messy floating pink hair:1.3), Portrait,upper body,(arms behind back),perfect face,(beautiful detailed eyes),cute pink eyes,golden pupil,detailed face,white dress,disheveled hair

次に光彩・エフェクト・フィルターの内容を入力します。
背景の光量や目の輝きに対しての明るさなどが含まれています。
光源や立ち位置に関するプロンプト
③focus,sidelighting, lustrous skin,(shine), lighting, ray tracing,(((Personage as the main perspective))),(((character in the middle))),(dynamic angle)

最後に背景に関する情報を入力します。
全体の雰囲気やオブジェクトなど人物以外の要素が含まれています。
背景に関するプロンプト
④An enchanted forest at night illuminated by glowing mushrooms,((Tyndall effect)),(Fluorescent mushroom forests background),(beautiful water),river,flying butterfly,sunlight,shine,chiaroscuro

ネガティブプロンプトは、ある程度形式化しても問題ありません。
四肢の崩れや画質に関しては最低限の入力が必要となります。
その他、テキストやロゴの表示などが目立つ場合は「強調構文」を利用して処理しましょう。
ネガティブプロンプトの詳しい詳細は次の記事で紹介しているのでぜひご覧ください。
強調構文の詳しい使い方は次の記事で紹介しています。
ControlNetの使い方をマスターする

ControlNetとは、細かな条件を指定して画像生成できるStable Diffusionの拡張機能です。
ControlNetにはいくつかの機能が搭載されていて、生成する画像のポーズや構図、画風やテクスチャの変換、線画への色付けなどが可能です。
プロンプトだけでは指定できないさまざまな要素を画像に反映することができます。一般的な使い方としては、ポーズの指定、キャラクター固定、線画の色塗りなどです。
今回は、利用度の高い機能について、具体例を挙げて応用した使い方を解説していきます。
Cannyの応用
Cannyは、画像の輪郭を抽出して、それをもとに新しい画像を生成する拡張機能です。
プロンプトでは表現しにくい輪郭に至るまでの細かい描写を再現することができます。
基本的なCannyの利用例

Cannyには、さまざまな調整機能があります。各設定に関して解説します。
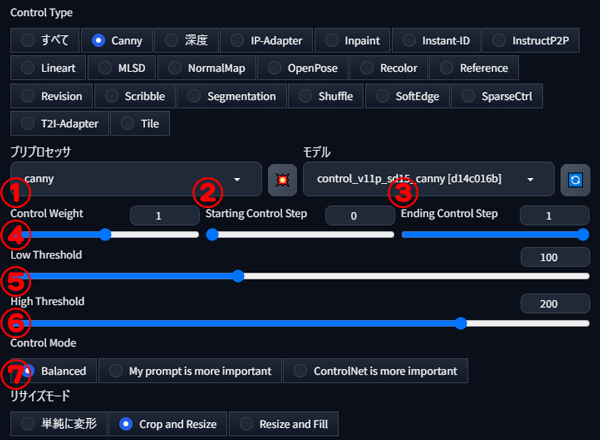
①Control Weight

Control Weightは、線画に対する描写の影響度をコントロールする数値です。
値が高いほど線画の線画の影響が強く、低いほど影響が弱くなります。
②Starting Control Step

Starting Control Stepは、ControlNetが動作を開始するステップ数を指定します。
数値が低いほど、ControlNetの設定内容が早い段階で反映されるため、線画の影響が強く画像に反映されます。
③Ending Control Step

Ending Control Stepは、ControlNetの効果が終了するステップ数を指定します。
②Starting Control Stepとは逆に、数値が低いほど、ControlNetの影響が早く終了し、線画から離れた結果になります。
一方、数値が高いほどControlNetの影響が長く続き、設定内容が画像に強く反映されやすくなります。
④Low Threshold

Low Thresholdは、線画の細かさを指定する値です。
値が低いほど細かい線を抽出し、高いほどラフな線を抽出します。
⑤High Threshold

High Thresholdは、④Low Thresholdの効果に上乗せし、さらに細かい線を抽出するための調整です。
Low Thresholdの値を参照して、値が低いほど細かく、高いほどラフになります。
⑥Control Mode

プロンプトとControlNetのバランスを調整します。
Balanced(バランス)、My prompt is more important(プロンプトを優先)、ControlNet is more important(ControlNetの内容を優先) の3つの選択肢があります。
⑦リサイズモード
画像のリサイズ方法を制御します。ベース画像と生成したい画像のサイズが異なる場合に、余白部分が反映されずに切れてしまうのを防ぎます。
次の3つのモードがあります。
- Just Resize:画像全体を、ベース画像のサイズに合わせてリサイズ
- Crop and Resize:画像の比率を維持、指定されたサイズに収まらない部分はカット
- Resize and Fill:画像の比率を維持し、余白部分を自動生成
線画と描き出す画像のサイズが同じ場合は、どのモードを選んでも生成結果は同じになります。
詳しいCannyの使い方は、下記のページでも紹介しているのでぜひご覧ください。

OpenPoseの応用
OpenPoseは、キャラクターのポーズを抽出し、新たに画像を生成する機能です。
OpenPose使用することで、プロンプトでは表現しにくい複雑なポーズも簡単に再現できます。
基本的なOpenPoseの利用例
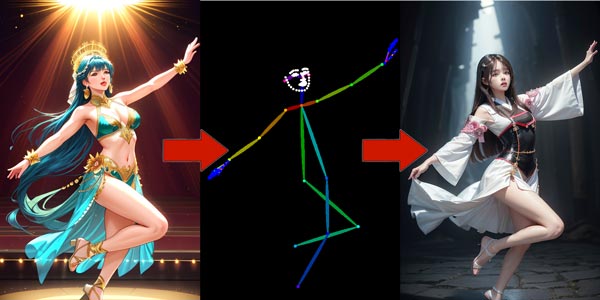
ここからはOpenPoseの細かい使用例を解説していきます。
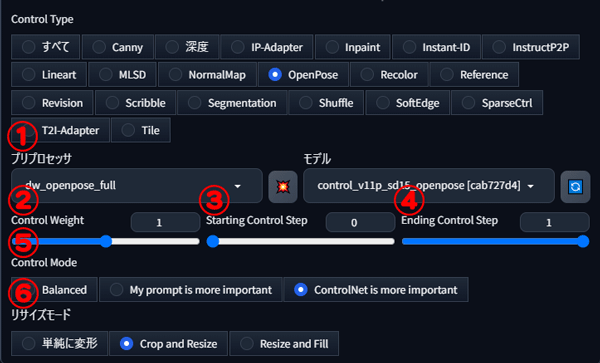
①プリプロセッサ
今回使用する素材画像

OpenPoseには、棒人間画像を抽出するためのプリプロセッサが標準で搭載されています。
プリプロセッサごとにポーズ抽出方法が異なるため、画像の特徴に合わせて適切なものを選択しましょう。
オーソドックス
openpose_full

手の形を重視
openpose_hand

顔のみ
openpose_faceonly

顔を重視
openpose_face
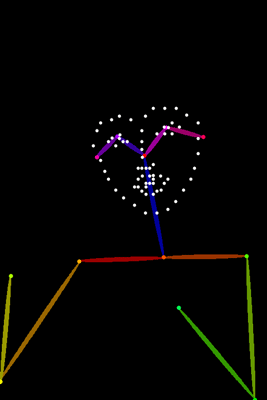
体型を重視
openpose
スタンダード
dw_openpose_full

姿勢を制御
densepose_parula

姿勢を制御
densepose

②Control Weight

Control Weightは、抽出した棒人間画像に対して描写の影響度を調整する数値です。
数値が高いほど、棒人間画像の効果が強く反映され、低いほど影響が弱くなります。
③Starting Control Step

Starting Control Stepは、ControlNetが動作を開始するステップ数を指定します。
数値が低いほど、早い段階でControlNetの設定が反映されます。
④Ending Control Step

Ending Control Stepは、ControlNetの効果を終了するステップ数を指定します。
数値が高いほど、ControlNetの設定が長く反映されます。
⑤Control Mode

プロンプトとControlNetのバランスを調整します。
チェックはそれぞれ、 Balanced(バランスをとった中間)、My prompt is more important(プロンプトを重視)、ControlNet is more important(ControlNetの内容を重視) があります。
⑥リサイズモード
画像のリサイズ方法を制御します。
ベース画像と生成する画像のサイズが異なる場合に、画像の切れや余白を自動調整するための設定です。
- Just Resize:画像全体を、ベース画像のサイズに合わせてリサイズ
- Crop and Resize:画像の比率を維持、指定されたサイズに収まらない部分はカット
- Resize and Fill:画像の比率を維持し、余白部分を自動生成
線画と描き出す画像のサイズが同じ場合、生成結果はどのモードでも同じになります。
詳しいOpenPoseの使い方は、下記のページでも紹介しているのでぜひご覧ください。

Lineartの応用
Lineartは、元の画像から線画を抽出し、さらに線画をベースに色を塗り直すことができる拡張機能です。
Lineartを使用すると、通常のプロンプトでは調整が難しい背景や肌の細かい線画を正確に抽出できます。
基本的なLineartの利用例

ここからはLineartの細かい使用例を解説していきます。
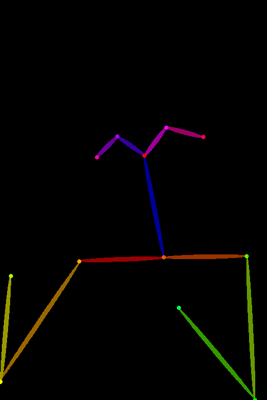
①プリプロセッサ
Lineartには、線画を抽出するためのプリプロセッサが標準で用意されています。
使用する素材や目的に応じて、適切なプリプロセッサを選びます。
今回使用する素材画像

実写系の画像とアニメ・イラスト系の画像では、抽出に使用するプリプロセッサによる違いが大きくでます。
実写の画像では「lineart_realistic」と「lineart_coarse」の二つの利用が推奨されます。
スタンダード
lineart_realistic

粗めの書き出し
lineart_coarse

アニメノイズカット
anime_denoise

アニメタッチ
lineart_anime

モノクロ反転
standard

モノクロのみ対応
lineart_invert

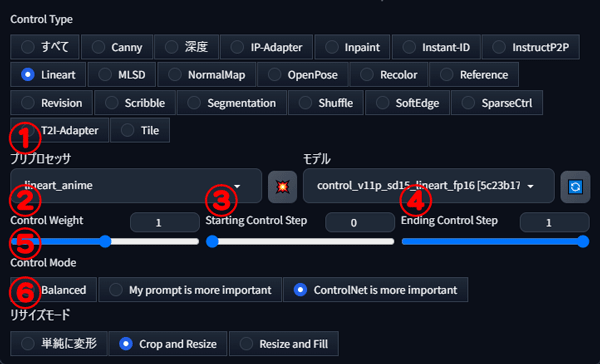
②Control Weight

Control Weightは、線画に対する描写の影響度を調整する数値です。
数値が高いほど、線画の効果が強く反映され、数値が低いほど効果が弱くなります。
③Starting Control Step

Starting Control Stepは、ControlNetが動作を開始するステップ数を指定します。
数値が低いほど、早い段階でControlNetの設定が反映され、線画に忠実な画像が生成されます。
④Ending Control Step

Ending Control Stepは、ControlNetの効果を終了するステップ数を指定します。
数値が高いほど、ControlNetの影響が長く続き、線画に忠実な画像が生成されます。
⑤Control Mode

プロンプトとControlNetのバランスを調整します。
チェックはそれぞれ、 Balanced(バランスをとった中間)、My prompt is more important(プロンプトを重視)、ControlNet is more important(ControlNetの内容を重視) があります。
⑥リサイズモード
画像のリサイズ方法を制御します。
ベース画像と生成する画像のサイズが異なる場合に、画像の切れや余白を自動調整するための設定です。
- Just Resize:画像全体を、ベース画像のサイズに合わせてリサイズ
- Crop and Resize:画像の比率を維持、指定されたサイズに収まらない部分はカット
- Resize and Fill:画像の比率を維持し、余白部分を自動生成
線画と描き出す画像のサイズが同じ場合、生成結果はどのモードでも同じになります。
詳しいLineartの使い方は下記ページでも紹介しています。

\登録はこちら/

「PICSOROBAN」でLoRAを使いこなす

Stable Diffusion のcheckpoint(モデル)には、一定の人物が学習されており、同じプロンプトを入力すると同じ人物が生成されがちです。
毎回同じチェックポイントを使っていると、人物がパターン化され、クリエイティブな作品を作るのが難しくなることがあります。そんな時に役立つのがLoRAです。
LoRAを使うことによって、モデルに追加学習データを適用し、生成される画像に変化を加えることができます。
LoRAを使って日本人風に変更
まずは、素材の画像を日本人風にアレンジします。
もし使用するcheckpointに日本人が学習されていない場合は、このようなLoRAを使って顔つきなどを日本人らしく補正できます。
「JapaneseDollLikeness」は多くの日本人の特徴を学習したLoRAです。
今回使用した素材画像

LoRAを使用

LoRAを使用

LoRAを使って髪型を変更
次に、生成された画像にさらにLoRAを適用して髪型をポニーテールに変更します。
「Hairstyles Collection」は、多様な髪型を学習したLoRAです。


LoRAを使って背景を変更
最後に、画像の背景を変更します。今回は東京の新宿に背景を設定します。
「Shinjuku: City street background」は、東京の新宿区の画像を学習したLoRAです。



PICSOROBANを使いこなしてStable Diffusionを極めよう!
今回は「PICSOROBAN」でStable Diffusionをマスターする細かい技法ついて解説しました。
ここで紹介した機能以外にも生成に関するテクニックは、たくさんあります。
さまざまな拡張機能などをカスタマイズして、Stable Diffusionを極めてみましょう!
Stable Diffusionの使い方は、機能別に下記の記事にまとめているのでぜひご覧ください







