
Stable Diffusionには、データ学習に関する機能が搭載されており、学習されたモデルやデータを活用することによって手間を省きつつ、より精度の高い画像を生成することができます。
この記事では、Stable Diffusionの各学習機能の詳細や活用方法をわかりやすく解説します。
Stable Diffusionの学習モデル/データとは?

Stable Diffusionの学習モデル/データは、画像生成に使用する学習済みファイルのことです。
実写、アニメ、アートなどのジャンルと画風をプロンプトだけで入力して生成を繰り返すと時間がかかりますが、あらかじめ学習されたモデルやデータを利用することで、詳細な画風の指定を省略できます。
Stable Diffusionでは学習モデル/データを使用することで、テキストから画像を生成する基本機能が強化され、画風やスタイルを簡単に再現できます。
さくさく画像生成したい方に!

Stable Diffusionの使い方は、機能別に下記の記事にまとめているのでぜひご覧ください

各Stable Diffusion学習モデル/データの特徴

Stable Diffusion学習モデル/データは、いくつかの種類があり、使用するシーンに応じて使い分けることで、理想の画像を生成するのに役立ちます。
それぞれの学習モデル/データには強みがあり、目的に応じて適切に選ぶことが重要です。
Stable Diffusionの学習モデル/データには次のような種類があります。
- Checkpoint(モデル):主に画像の画風を決定
- LoRA:構図や画風、人物の特徴などを追加学習
- ControlNet:ポーズ、構図、線画、深度情報など、出力画像のスタイルを詳細に指定可能
- VAE:質感や彩度を向上
- Embedding:ネガティブプロンプトの記述を省略し、クオリティを向上
ここからは、Stable Diffusion学習モデル/データの特徴を種類別に解説していきます。
Checkpoint
Checkpointとは、一般的に「モデル」と呼ばれ、Stable Diffusionで主に生成する画像の画風を決める際に使用されます。
Stable Diffusionの学習データの中で、最も基本的な機能がこのCheckpointです。
異なるCheckpointを使用することで、同じプロンプトでも全く異なる画風の画像を生成できます。
実際に同じプロンプトでアニメ系と実写系のCheckpointを使用した場合の画像を以下に示します。


使用したプロンプト
「(masterpiece),((ultra-detailed)), (highly detailed CG illustration), (best quality:1.2), 1girl, solo, anime, perfect face, Portrait, sidelighting, lustrous skin,(Bubblegum and Mint hair color:1.0), (shine), lighting, ray tracing, ultra-detailed,highly detailed,realistic,photorealistic, close up, slim body, school uniform, long hair, laughing, evening, Tokyo Electric Town background, colorful lights, photon mapping, radiosity, physically-based rendering, cinematic lighting, intricate, High Detail, Sharp focus, dramatic」
ネガティブプロンプト
「(lowres:1.1), (worst quality:1.2), (low quality:1.1), bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, normal quality, jpeg artifacts, signature, watermark, username, blurry」
Stable DiffusionにCheckpointを導入する方法やおすすめのモデルについてはこちらの記事でも紹介していますので、参考にしてください。

LoRA
LoRAとは、「Low-Rank Adaptation」の略で、構図や画風、人物の特徴を追加学習することができます。
Stable DiffusionでLoRAを使うことで人物を固定したり、プロンプトでは表現が難しい画像を生成したりすることができます。
LoRAはCheckpointに対しての追加学習データであり、Stable Diffusionでは対応する学習済みモデルと常に一緒に使う必要があります。
例えば、「お嬢様ポーズ」と呼ばれている片手を口元に添えるポーズは、プロンプト「ojousama pose」では現在Stable Diffusionに学習されていません。
このポーズをStable Diffusionで表現したい場合は、詳細をプロンプトで書く必要がります。
しかし、お嬢様ポーズ専用の追加学習データであるLoRAを利用することで、Stable Diffusionでもこのポーズを簡単に再現できるのです。

Stable DiffusionにLoRAを導入する方法やおすすめのLoRAについてはこちらの記事でも紹介していますので、参考にしてください。

ControlNet
ControlNetは、プロンプトで指示しきれないポーズや構図などを指定することができるStable Diffusionの拡張機能です。
Stable DiffusionでControlNetを利用すると次のことが可能です。
- 入力画像からポーズを検出し、同じポーズで新しい画像を生成する
- 画像から線画を抽出し、構図を維持して再描画する
- 下書きから画像を生成する
- 画像の一部だけを指定して修正する
- 画像の深度情報をベースに新たな画像を生成する
Stable DiffusionでControlNetを使うことで、画像に対してより専門的な処理や指定を加えることができます。
プロンプトでは指示できない複雑な構図や、文字で説明するのが難しいポーズなどが生成可能となります。
Stable DiffusionにControlNetを導入する方法や機能の種類については下記の記事で紹介していますので、参考にしてください。

VAE
VAEとは「Variational Auto-Encoder」の略で、画像生成における質感や彩度を向上させるStable Diffusionの拡張機能です。
画像の質感を向上させて劣化を防ぐために積極的に利用したい機能です。
VAEをStable Diffusionで使用する際は、モデルとの相性が重要になります。
モデルとセットで提供されているVAEを必ず確認し、適切に使用することが大切です。

VAEの詳しい説明は、こちらの記事でもご覧いただくことができます。

Embedding
Embedding(エンベディング)は、日本語で「埋め込み」とも呼ばれる機能です。
Embeddingは、Stable Diffusionの中で特定のプロンプトをまとめて1つのキーワードとして呼び出せるようにします。
これにより、複雑な指示やスタイルを一度で適用できます。
例えば、通常Stable Diffusionでは「美しい顔の女性、長い髪、笑顔」といった一連のプロンプトを入力しなければなりませんが、Embeddingを使うと「美しいスタイル」というキーワードだけで同じプロンプトを適用できます。
このようにして、何度も同じプロンプトを入力する手間を省くことができます。
Stable DiffusionでEmbeddingは、主にネガティブプロンプトの記述を省略するのに利用されており、特に手の崩れなど、細かな修正に役立ちます。
Embeddingを利用することで、プロンプトの簡略化とともに、より精細で高品質な画像を生成することができます。
Embeddingの中でも人気なのは、ネガティブプロンプトをまとめる「EasyNegative」や手の奇形を防いでくれる「Bad-Hands-5」です。
EasyNegativeについては、こちらの記事で詳しく説明していますので、あわせてご覧ください。

スポンサーリンク
Stable Diffusion学習モデル/データの使い方

それではLoRAを例にして、実際にStable Diffusionで学習データを利用して画像を生成してみましょう。
学習モデル/データを使う準備
LoRAファイルのダウンロード方法
まずはLoRAのデータをCivitaiからダウンロードします。
CivitaiのLoRAページにアクセスします。
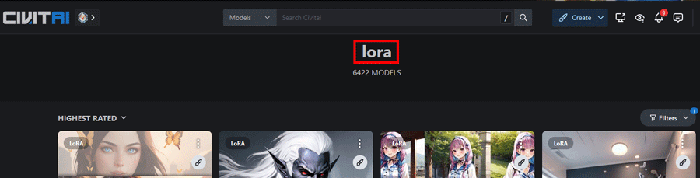
Stable Diffusionで生成された作品やモデルを共有できるプラットフォームです。
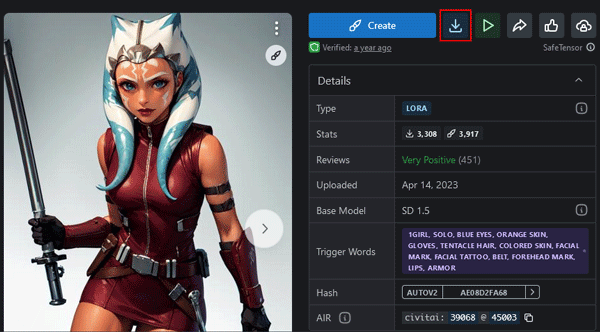
気になる構図や背景をクリックして詳細ページからデータ「.safetensorsファイル」をダウンロードします。
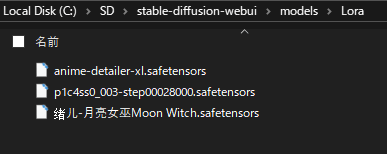
Stable Diffusion Web UIを「models」>「Lora」の順で開き、先ほどダウンロードした「○○.safetensors」ファイルを配置すれば完了です。
学習モデル/データを使って画像生成する
LoRAの構図に近いモデルとプロンプトを用意します。
モデルとLoRAのスタイルが離れていると構図が崩れる場合があるので注意しましょう。
できるだけジャンルや画風スタイルを寄せた方が生成の成功率が上がります。
Stable DiffusionにあるLoRAのタブからダウンロードしたファイルをクリックしてプロンプトに反映させます。
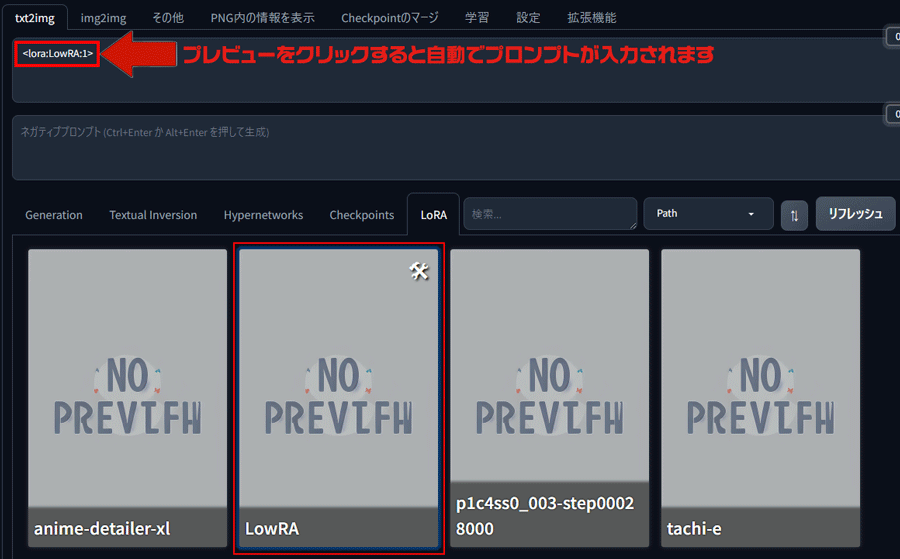
今回使用したのは「Escalatorview」のLoRAで、エスカレーターを構図に含んだものです。
<lora:***:1>と表示されますので、続いてプロンプトを入力します。

Stable DiffusionでLoRAのテーマと同じ構図の画像が生成されました。


Stable Diffusionの学習モデル/データを使うならピクソロがおすすめ

Stable Diffusionの学習モデル/データを使うには12G以上のVRAMが推奨とされていますが、進化が速いため、12Gでも不足がちになっているのが現状です。
さらに拡張機能の利用には高い計算力が必要なので、パワー不足に陥る時があります。
そんな時は、パソコンのスペックに関係なく、どこでもStable Diffusionが利用できるサービスがおすすめです。
手軽に使いたい方へ:ピクソロの利用がおすすめ
PICSOROBANは、インストール不要・ブラウザから簡単にStable Diffusionを始められるサービスです。
ピクソロのメリット
- すぐ使える:高額PC不要で、ブラウザからすぐに利用可能。必要な分だけポイントを購入できます。
- リーズナブル:30分約60円で利用可能。さらに今なら約2時間分が無料。
- 無制限作成:時間内であれば、何枚でも画像生成可能。短時間でたくさんの作品を生成できます。
ブラウザで簡単!ピクソロ!

PICSOROBANは、インストールの必要なくブラウザで簡単にStable Diffusionを利用できます。
さらに、今ならリリースキャンペーンとして無料会員登録するだけで、2,000ポイント(約2時間分)貰えます!
詳しい使い方は下記の記事で紹介しています。
\今なら約2時間無料で使える!/
本格的に使いたい方へ:クラウドGPUの利用がおすすめ
クラウドGPUとは、インターネット上で高性能なパソコンを借りることができるサービスです。これにより、最新の高性能GPUを手軽に利用することができます。
クラウドGPUのメリット
- コスト削減:高額なGPUを購入する必要がなく、使った分だけ支払い
- 高性能:最新の高性能GPUを利用できるため、高品質な画像生成が可能
- 柔軟性:必要なときに必要なだけ使えるので便利
こんな人におすすめ
- 少ない予算でStable Diffusionを快適に使いたい
- 自分のパソコンの性能が不足していると感じる人
- 常に最新の高性能GPUを使いたい人

GPUSOROBANは、高性能なGPU「NVIDIA A4000 16GB」を業界最安値の1時間50円で使用することができます。
さらに、クラウドGPUを利用しない時は停止にしておくことで、停止中の料金はかかりません。
クラウドGPUを使えばいつでもStable Diffusionの性能をフルに引き出すことができるので、理想の環境に近づけることができます。
\快適に生成AI!1時間50円~/
Stable Diffusionが快適に使えるおすすめのパソコンやグラボに関しては下記の記事で紹介しています。










