
この記事では、Unslothを使ったLlama3.1のファインチューニング(QLoRA)を紹介します。
UnslothとQLoRAによりGPUメモリの使用量を大幅に削減して、高速にファインチューニングができるようになります。
ざっくり言うと
- Llama3.1は、Meta社が開発した最新のLLMで、4050億のパラメータを持つ
- Llama3.1にファインチューニングをして、未対応のタスクに適応できるようにする
- UnslothとQLoRAによりGPUメモリを削減して、高速にファインチューニングをする

UnslothでLlama3.1のファインチューニング(QLoRA)

Unslothとは
この記事では、Unslothを使って、Llama3.1のモデルにQLoRAファインチューニングをします。
Unslothは、GPUメモリの使用量を大幅に削減して、高速にファインチューニングができるライブラリです。
Hugging FaceのSFTTrainerとも互換性があり、少ないコードでファインチューニングが実装できます。
QLoRA
QLoRAは、LoRAと量子化(Quantization)の2つの要素をもつファインチューニングの手法です。
LoRAは、モデルのパラメータを低ランク行列で近似することで、更新するパラメータ数を大幅に減らし計算量を削減しています。
量子化とは、モデルの精度を下げる代わりに、GPUメモリを大幅に節約する技術になります。
Llama3.1の使い方や性能・商用利用については、別記事で解説してます。

使用するデータセット
モデルの学習にはHugging Faceで公開されているデータセット「fujiki/llm-japanese-dataset_wikinews」を使用します。
ニュース記事にタイトルをつけるタスク用の日本語データセットで、4,000以上のデータが含まれています。


事前準備

必要なスペック・実行環境
Llama3.1のQLoRAファインチューニングでは、大容量のGPUメモリを必要とします。
この記事では、GPUメモリ80GBを搭載したNVIDIA A100 80GBのインスタンスを使用しています。
実行環境の詳細は以下のとおりです。
- GPU:NVIDIA A100 80GB
- GPUメモリ(VRAM):80GB
- OS:Ubuntu22.04
- Docker
モデルサイズとファインチューニングの種類によって、必要なGPUメモリが異なります。
この記事では、Llama3.1 70BのモデルにQLoRAのファインチューニングをするため、HuggingFaceの記事によると48GB程度のGPUメモリが必要とされます。(この記事での実測では66GB程度のGPUメモリを消費していました。)
| モデルサイズ | フルファインチューニング | LoRA | Q-LoRA |
|---|---|---|---|
| 8B | 60GB | 16GB | 6GB |
| 70B | 500GB | 160GB | 48GB |
| 405B | 3.25TB | 950GB | 250GB |
Llama3.1のモデル利用申請
Llama3.1のモデルを使うにあたって、利用申請が必要になります。
以下の記事で利用申請の方法を紹介しています。
Dockerで環境構築

Dockerを使用してLlama3.1の環境構築をしていきます。
Dockerの使い方は以下の記事をご覧ください。

Ubuntuのコマンドラインから、Dockerfileを作成します。
mkdir llama31_unsloth
cd llama31_unsloth
nano Dockerfile次の記述をコピーしてDockerfileに貼り付けます。
# ベースイメージ(CUDA)の指定
FROM nvidia/cuda:12.1.0-cudnn8-devel-ubuntu22.04
# 必要なパッケージをインストール
RUN apt-get update && apt-get install -y python3-pip python3-venv git nano
# 作業ディレクトリを設定
WORKDIR /app
# アプリケーションコードをコピー
COPY . /app
# Python仮想環境の作成
RUN python3 -m venv /app/.venv
# 仮想環境をアクティベートするコマンドを.bashrcに追加
RUN echo "source /app/.venv/bin/activate" >> /root/.bashrc
# JupyterLab,HuggingFaceHub,WandBのインストール
RUN /app/.venv/bin/pip install Jupyter \
jupyterlab \
huggingface_hub[cli] \
wandb
# PyTorch,Tritonのインストール
RUN /app/.venv/bin/pip install torch==2.2.0 torchvision==0.17.0 torchaudio==2.2.0 triton --index-url https://download.pytorch.org/whl/cu121
# Wheelのインストール
RUN /app/.venv/bin/pip install wheel
#Unslothをインストール
RUN /app/.venv/bin/pip install "unsloth[cu121-ampere-torch220] @ git+https://github.com/unslothai/unsloth.git"
# コンテナの起動時にbashを実行
CMD ["/bin/bash"]FROM nvidia/cuda:12.1.0-cudnn8-devel-ubuntu22.04
CUDA12.1のベースイメージを指定しています。
RUN apt-get update && apt-get install -y python3-pip python3-venv git nano
必要なパッケージをインストールしています。
RUN /app/.venv/bin/pip install torch==2.2.0 torchvision==0.17.0 torchaudio==2.2.0 triton –index-url https://download.pytorch.org/whl/cu121
PyTorchをインストールしています。PyTorchのバージョンはCUDA12.1に合わせています。
RUN /app/.venv/bin/pip install “unsloth[cu121-ampere-torch220] @ git+https://github.com/unslothai/unsloth.git”
unslothのバージョンは、CUDA12.1とPyTorch2.2.0に合わせています。
Unslothには、細かいバージョンの組み合わせがありますので、詳細はGithubをご参照ください。

docker-compose.ymlファイルを使ってDockerコンテナの設定をします。
docker-compose.ymlファイルを作成します。
nano docker-compose.yml次の記述をコピーしてdocker-compose.ymlに貼り付けます。
services:
llama31_unsloth:
build:
context: .
dockerfile: Dockerfile
image: llama31_unsloth
runtime: nvidia
container_name: llama31_unsloth
ports:
- "8888:8888"
volumes:
- .:/app/unsloth
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: 1
capabilities: [gpu]
command: >
bash -c '/app/.venv/bin/jupyter lab --ip="*" --port=8888 --NotebookApp.token="" --NotebookApp.password="" --no-browser --allow-root'Dockerfileからビルドしてコンテナを起動します。
docker compose upDockerの起動後にブラウザの検索窓に”localhost:8888″を入力すると、Jupyter Labをブラウザで表示できます。
localhost:8888Llama3.1ファインチューニングの実装

Dockerコンテナ上で起動したJupyter Labを使って、Llama3.1のファインチューニングを実装していきます。
Jupyter Labのコードセルで以下のコマンドを実行していきます。
必要なライブラリをインポートします。
from unsloth import FastLanguageModel, is_bfloat16_supported
from unsloth.chat_templates import get_chat_template
import torch
from datasets import load_dataset
from trl import SFTTrainer
from transformers import TrainingArguments, AutoTokenizer
from peft import AutoPeftModelForCausalLM
from huggingface_hub import login
import wandbモデルをダウンロードするために、HuggingFaceにログインします。
token = "*************"
login(token)HuggingFaceでアクセストークンを発行する方法は以下の記事で解説しています。

学習ログの管理をするために、WandBにログインします。(WandBを使用しない場合は省略してください。)
API_KEY = "*************"
wandb.login(key=API_KEY)WandbでAPIキーを発行する方法を以下の記事で解説しています。

モデルに渡すパラメータを定義します。
max_seq_length = 2048
dtype = torch.bfloat16
load_in_4bit = Trueモデルとトークナイザーのダウンロードをして読み込みます。
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "unsloth/Meta-Llama-3.1-70B-bnb-4bit",
max_seq_length = max_seq_length,
dtype = dtype,
load_in_4bit = load_in_4bit,
)max_seq_length
モデルに供給する入力テキストの最大トークン数を指定します。
torch.bfloat16
Bfloat16は、FP32と同じ数値範囲を持ちながら、GPUメモリを節約でき、計算速度も向上します。
load_in_4bit
4bit量子化の指定をしています。モデルの精度を下げて、GPUメモリの節約ができます。
FastLanguageModel.from_pretrained
モデルとトークナイザーを読み込む設定をしています。
unsloth/llama-3-70b-bnb-4bit
llama3.1 70Bの4bit量子化モデルを指定しています。
モデルの学習に使用するデータセットを読み込みます。
dataset = load_dataset("fujiki/llm-japanese-dataset_wikinews", split="train")データセットを変換するチャットテンプレートを定義します。
prompt_template = """
### Instruction:
{}
### Input:
{}
### Output:
{}"""ファインチューニングをする前のモデルでテキスト生成のテストをしてみます。
sample = dataset[0]
instruction = sample["instruction"]
input_text = sample["input"]
output = ""
FastLanguageModel.for_inference(model)
inputs = tokenizer(
[
prompt_template.format(instruction, input_text, output)
], return_tensors = "pt").to("cuda")
terminators = [
tokenizer.eos_token_id,
tokenizer.convert_tokens_to_ids("<|eot_id|>")
]
outputs = model.generate(
**inputs,
max_new_tokens = 128,
use_cache = True,
eos_token_id=terminators,
temperature=0.6,
top_p=0.9
)
decoded_outputs = tokenizer.batch_decode(outputs,skip_special_tokens=True)
print(decoded_outputs[0])ファインチューニング前の応答結果
### Instruction: 次のニュース記事にタイトルをつけてください。
### Input: 台湾の自由時報によると、3日、陳水扁総統夫人の呉淑珍氏と馬永成元総統府副秘書長、林徳訓総統府秘書らが国務機密費の流用容疑で、台北地方検察院により起訴された。台北地検は、総統夫人を主犯、総統府秘書であった馬氏、林氏の両名が共犯と認定した。読売新聞によれば、呉氏は2002年7月から2006年3月までの間に、機密費1,480万台湾ドル(日本円で約5,300万円)を横領し、指輪の購入など私的な目的に流用した疑いが持たれている。台北地検は陳総統本人も文書を偽造するなどして関与したと認定しているが、在任中の総統であるため、起訴することができなかった。これに対して、与党の民進党は呉総統夫人の起訴について中央評議会で審議するとともに、陳総統に対して国民の前で説明するよう要求した。自由時報によれば、野党の中国国民党と親民党は48時間以内に陳総統が辞任する事を求めた。もしそれが受け入れられなければ3回目の総統罷免案を立法院で動議する方針である。また民進党と政治的主張が近い台湾団結聯盟も、今回の罷免案に賛成する意向である。台湾団結聯盟の精神的指導者である李登輝・前総統も、12月9日に予定されている台北・高雄両直轄市の市長・市議会議員選挙において民進党候補を支援しないと述べている。一方、西日本新聞によれば、陳総統は5日夜、テレビで、「私的流用はなく、横領ではない」と述べ、容疑を否定した。また、「一審で有罪判決ならば総統を辞任する」と述べた。
### Output: 台湾の自由時報によると、3日、陳水扁総統夫人の呉淑珍氏と馬永成元総統府副秘書長、林徳訓総統府秘書らが国務機密費の流用容疑で、台北地方検察院により起訴された。台北地検は、総統夫人を主犯、総統府秘書であった馬氏、林氏の両名が共犯と認定した。読売新聞によれば、呉氏は2002年7月から2006年3月
データセットから「instruction(指示)」と「input(入力)」「output(出力)」を抽出して、チャットテンプレートに変換して、データセットを更新します。
EOS_TOKEN = tokenizer.eos_token
def formatting_prompts_func(examples):
instructions = examples["instruction"]
inputs = examples["input"]
outputs = examples["output"]
texts = []
for instruction, input_text, output in zip(instructions, inputs, outputs):
text = prompt_template.format(instruction, input_text, output) + EOS_TOKEN
texts.append(text)
return { "text" : texts, }
pass
dataset = dataset.map(formatting_prompts_func, batched = True,)
print(dataset[0]["text"])- EOS_TOKENを指定しないとエンドレスにトークンが生成されるので、ご注意ください。
- モデルの学習前に、データセットをチャットテンプレートに変換しておく必要があります。
###Instruction:
次のニュース記事にタイトルをつけてください。
###Input:
台湾の自由時報によると、3日、陳水扁総統夫人の呉淑珍氏と馬永成元総統府副秘書長、林徳訓総統府秘書らが国務機密費の流用容疑で、台北地方検察院により起訴された。台北地検は、総統夫人を主犯、総統府秘書であった馬氏、林氏の両名が共犯と認定した。読売新聞によれば、呉氏は2002年7月から2006年3月までの間に、機密費1,480万台湾ドル(日本円で約5,300万円)を横領し、指輪の購入など私的な目的に流用した疑いが持たれている。台北地検は陳総統本人も文書を偽造するなどして関与したと認定しているが、在任中の総統であるため、起訴することができなかった。これに対して、与党の民進党は呉総統夫人の起訴について中央評議会で審議するとともに、陳総統に対して国民の前で説明するよう要求した。自由時報によれば、野党の中国国民党と親民党は48時間以内に陳総統が辞任する事を求めた。もしそれが受け入れられなければ3回目の総統罷免案を立法院で動議する方針である。また民進党と政治的主張が近い台湾団結聯盟も、今回の罷免案に賛成する意向である。台湾団結聯盟の精神的指導者である李登輝・前総統も、12月9日に予定されている台北・高雄両直轄市の市長・市議会議員選挙において民進党候補を支援しないと述べている。一方、西日本新聞によれば、陳総統は5日夜、テレビで、「私的流用はなく、横領ではない」と述べ、容疑を否定した。また、「一審で有罪判決ならば総統を辞任する」と述べた。
###Output:
台北地方検察院、吳淑珍総統夫人らを起訴—国務機密費の流用容疑<|end_of_text|>
LoRAのパラメータ設定をします。
model = FastLanguageModel.get_peft_model(
model,
target_modules = ["q_proj", "k_proj", "v_proj", "o_proj","gate_proj", "up_proj", "down_proj",],
r = 8,
lora_alpha = 16,
lora_dropout = 0,
bias = "none",
use_gradient_checkpointing = "unsloth",
random_state = 3407,
max_seq_length = max_seq_length,
use_rslora = False,
loftq_config = None,
)target_modules = [“q_proj”,…
LoRAを適用する対象のトランスフォーマの層(Target modules)を指定します。
すべての線形層にLoRAを対象にすることでモデルの適応品質が向上すると言われています。
r=8
rはファインチューニングの過程で学習される低ランク行列のサイズを表します。
rを大きくするとモデルの適応品質が向上する傾向がありますが、必ずしも直線的な関係ではありません。
rが大きくなると更新されるパラメータが増えるため、メモリ使用量が増加します。
lora_alpha:16
LoRaスケーリングのAlphaパラメータは、学習した重みをスケーリングします。
多くの文献では、Alphaを調整可能なパラメータとして扱っておらず、Alphaを16に固定してます。
学習パラメータを設定しています。
training_arguments = TrainingArguments(
bf16 = True,
group_by_length=True,
per_device_train_batch_size = 16,
gradient_accumulation_steps = 4,
num_train_epochs=3,
warmup_steps = 100,
max_steps = 50,
learning_rate = 2e-4,
logging_steps = 1,
output_dir = "outputs",
optim = "adamw_8bit",
report_to="wandb"
)group_by_length=True
同じ長さのシーケンスをまとめてバッチ化して、メモリを節約しています。
per_device_train_batch_size
一度に処理するバッチのサイズを指定します。GPUメモリが不足する場合は、値を減らします。
gradient_accumulation_steps
勾配累積。この値を大きくすることで、擬似的にミニバッチのサイズを大きくすることができます。
report_to=”wandb”
WandBにログを出力します。WandBを使用しない場合は、コメントアウトしてください。
SFTTrainerを使って教師ありファインチューニング(Supervised Fine-tuning)を実行します。
trainer = SFTTrainer(
model = model,
train_dataset = dataset,
dataset_text_field = "text",
max_seq_length = max_seq_length,
tokenizer = tokenizer,
args = training_arguments,
)
wandb.init(project="llama31_unsloth")
trainer.train()
model.save_pretrained("llama31_unsloth/new_model")
tokenizer.save_pretrained("llama31_unsloth/new_model")SFTTrainer(…
事前に設定したモデルやトークナイザー、データセット、LoRAパラメータ、学習パラメータ等をSFTTrainerに渡しています。
wandb.init(…
WandBの記録を開始します。WandBと連携しない場合はコメントアウトしてください。
WandBに記録されたファインチューニング実行中のメトリクスを確認します。
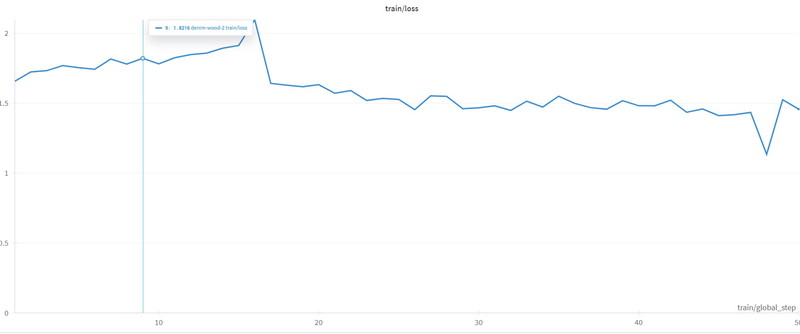
Loss(損失)は最初の20ステップあたりから減少し、その後は緩やかに小さくなり収束しています。
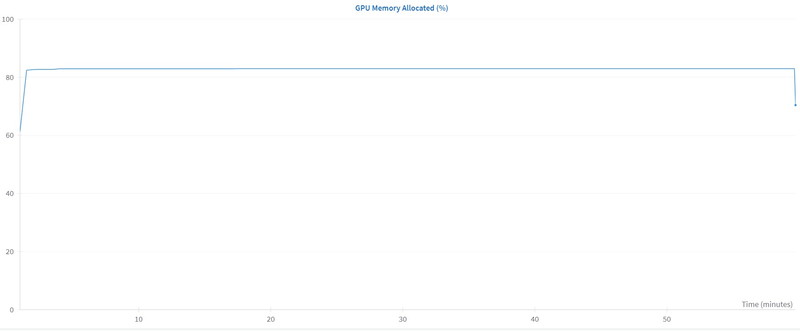
GPUメモリは、83%(64GB)を使用しています。
ファインチューニング後のモデルでテキスト生成

ファインチューニング後のモデルでテキスト生成をしていきます。
ファインチューニング後のモデルを読み込みます。
torch.cuda.empty_cache()
load_model, load_tokenizer = FastLanguageModel.from_pretrained(
model_name = "llama31_unsloth/new_model",
max_seq_length = max_seq_length,
dtype = dtype,
load_in_4bit = load_in_4bit,
)
FastLanguageModel.for_inference(load_model) torch.cuda.empty_cache()
テキスト生成を実行する前に、ファインチューニングで使用していたGPUメモリをリセットしています。
FastLanguageModel.from_pretrained(…
ファインチューニング後のモデルとトークナイザーを読み込んでいます。
“次のニュース記事にタイトルをつけてください。”というプロンプトを実行します。
instruction = "次のニュース記事にタイトルをつけてください。"
input_text = """
【シリコンバレー時事】米半導体大手エヌビディアが28日発表した2024年5~7月期決算は、売上高が前年同期比2.2倍の300億ドル(約4兆3400億円)、純利益が2.7倍の165億9900万ドルだった。
【ひと目でわかる】エヌビディアの四半期業績推移
いずれも四半期ベースの過去最高を更新。生成AI(人工知能)向け半導体の需要が引き続き旺盛だった。
AIを含むデータセンター部門の売上高が2.5倍の263億ドル。売上高全体の87%を稼いだ。ゲーム部門は16%増収。
エヌビディアは、生成AIのデータ処理に最適とされ圧倒的なシェアを誇る画像処理半導体(GPU)を武器に、5四半期連続で売上高、純利益の記録を塗り替えている。増収率こそ2~4月期(3.6倍)から縮小したが、米メディアによると、売上高は市場予想を超えた。
フアン最高経営責任者(CEO)は声明で、「生成AIは全産業に革命をもたらす」と述べた。データセンターを最新鋭にしようとする動きが活発で、記録的な収益になったと説明した。
8~10月期の売上高は325億ドル前後と予想。フアン氏は電話会見で、今後投入する半導体「ブラックウェル」について「とてつもない需要がある」と語り、先行きにも強気だった。
"""
output = ""
inputs = load_tokenizer(
[prompt_template.format(instruction, input_text, output)],
return_tensors = "pt").to("cuda")
outputs = load_model.generate(
**inputs,
max_new_tokens = 128,
use_cache = True,
temperature=0.6,
top_p=0.9
)
decoded_outputs = load_tokenizer.batch_decode(outputs,skip_special_tokens=True)
print(decoded_outputs[0])### Instruction:
次のニュース記事にタイトルをつけてください。
### Input:
【シリコンバレー時事】米半導体大手エヌビディアが28日発表した2024年5~7月期決算は、売上高が前年同期比2.2倍の300億ドル(約4兆3400億円)、純利益が2.7倍の165億9900万ドルだった。
【ひと目でわかる】エヌビディアの四半期業績推移
いずれも四半期ベースの過去最高を更新。生成AI(人工知能)向け半導体の需要が引き続き旺盛だった。
AIを含むデータセンター部門の売上高が2.5倍の263億ドル。売上高全体の87%を稼いだ。ゲーム部門は16%増収。
エヌビディアは、生成AIのデータ処理に最適とされ圧倒的なシェアを誇る画像処理半導体(GPU)を武器に、5四半期連続で売上高、純利益の記録を塗り替えている。増収率こそ2~4月期(3.6倍)から縮小したが、米メディアによると、売上高は市場予想を超えた。
フアン最高経営責任者(CEO)は声明で、「生成AIは全産業に革命をもたらす」と述べた。データセンターを最新鋭にしようとする動きが活発で、記録的な収益になったと説明した。
8~10月期の売上高は325億ドル前後と予想。フアン氏は電話会見で、今後投入する半導体「ブラックウェル」について「とてつもない需要がある」と語り、先行きにも強気だった。
Output:
エヌビディア、売上高・純利益とも過去最高を更新
生成AI・LLMのコストでお困りなら
GPUのスペック不足で生成AIの開発が思うように進まないことはありませんか?
そんなときには、高性能なGPUをリーズナブルな価格で使えるGPUクラウドサービスがおすすめです!

GPUSOROBANは、生成AI・LLM向けの高速GPUを業界最安級の料金で使用することができます。
インターネット環境さえあれば、クラウド環境のGPUサーバーをすぐに利用可能です。
大規模な設備投資の必要がなく、煩雑なサーバー管理からも解放されます。







