
Phi-3は、Microsoftが開発した無料で使える高性能なSLM(小規模言語モデル)です。
軽量モデルであるため、小さなGPUメモリのローカル環境でも動かすことができます。
この記事では、Phi-3の性能から使い方まで紹介します。

Phi-3とは

Phi-3(ファイスリー)は、Microsoftが開発したオープンソースの高性能SLM(小規模言語モデル)です。
Phi-3は、同じパラメータサイズの言語モデルよりも大幅に優れたパフォーマンスをもつと言われています。
Phi-3の特徴は以下のとおりです。
- 同等以上のサイズのモデルと比較して性能が高い
- 軽量モデルであるため生成の処理速度が速い
- モデルをダウンロードして、ローカル環境でも実行が可能

Phi-3のモデル

Phi-3には複数の種類があり、「パラメータサイズ」、「サポートするコンテキスト長」、「マルチモーダル」で分けられます。
| モデルID | パラメータサイズ | コンテキスト長 | マルチモーダル |
|---|---|---|---|
| microsoft/Phi-3-mini-4k-instruct | 3.8億パラメータ | 4kトークン | 無(テキスト入力のみ) |
| microsoft/Phi-3-mini-128k-instruct | 3.8億パラメータ | 128kトークン | 無(テキスト入力のみ) |
| microsoft/Phi-3-small-8k-instruct | 70億パラメータ | 8kトークン | 無(テキスト入力のみ) |
| microsoft/Phi-3-small-128k-instruct | 70億パラメータ | 128kトークン | 無(テキスト入力のみ) |
| microsoft/Phi-3-medium-4k-instruct | 140億パラメータ | 4kトークン | 無(テキスト入力のみ) |
| microsoft/Phi-3-medium-128k-instruct | 140億パラメータ | 長い(128kトークン) | 無(テキスト入力のみ) |
| microsoft/Phi-3-vision-128k-instruct | 42億パラメータ | 128kトークン | 有(テキスト+画像入力) |
mini:3.8億パラメータ
small:70億パラメータ
medium:140億パラメータ
4K:短いコンテキスト長(トークン数)
128k:長いコンテキスト長(トークン数)
vision:画像とテキストを入力して、テキスト生成するマルチモーダルAIモデル
マルチモーダルモデルの「Phi-3-vision-128k-instruct」は別記事で解説しています。

Phi-3の性能
LLMの主要ベンチマークを比較しながら、Phi-3の性能を見ていきます。

主要ベンチマーク
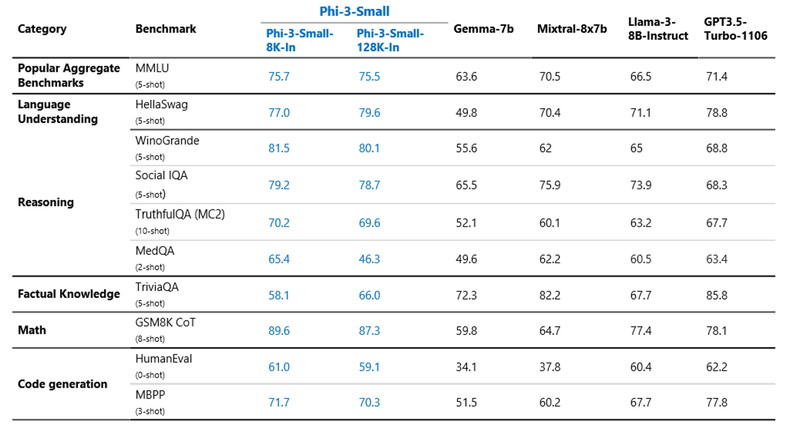
Phi-3-small(70億パラメータ)は、主要なベンチマークで GPT-3.5TurboやLlama3 8Bを上回っています。
ベンチマークの種目は、質疑応答、プログラミング、推論、数学になります。
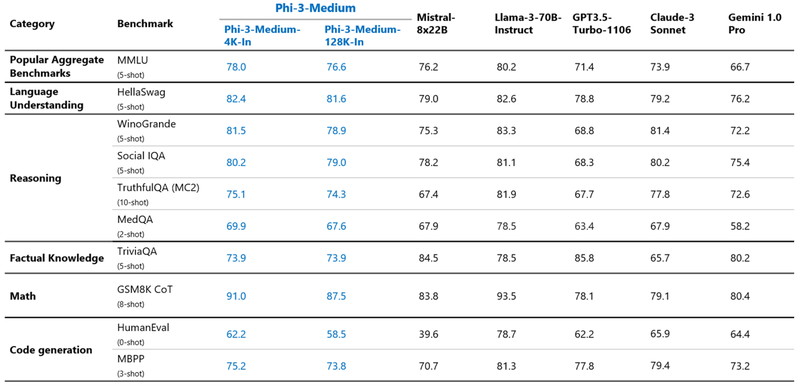
Phi-3-Medium(140億パラメータ)は、Llama3 70B(700億パラメータ)と同等の結果を出しています。
Phi-3の日本語能力は?

Phi-3-miniは英語のみに対応しており、日本語には対応していません。
この記事では、Phi-3を使って日本語生成のテストをしてみます。
Phi-3の商用利用・ライセンス

Phi-3は、MITライセンスをもとに提供されており、無料で商用利用できます。
MITライセンスは、ソフトウェアの配布に使用される非常に寛容なオープンソースライセンスです
商用利用:ソフトウェアやコードを商用利用することが完全に許可されています。
改変:ソフトウェアを自由に修正したり改変したりすることができます。
配布:修正したり変更したりしたソフトウェアを自由に配布することができます。
著作権の表示:再配布時にオリジナルの著作権表示とライセンス条項を含める必要があります。
特許利用:特許利用に関する明示的な規定はありません。
Phi-3の使い方

ここからPhi-3を使ったテキスト生成について解説していきます。
実行環境
この記事で用意した実行環境は以下のとおりです。
- GPU:NVIDIA A100 80GB
- GPUメモリ(VRAM):80GB
- OS :Ubuntu 22.04
- Docker
Ollamaを使ってChatGPTのようなインターフェイスでテキスト生成をしたい方は以下の記事をご覧ください。

Dockerで環境構築
Dockerを使用してPhi-3の環境構築をします
Dockerの使い方は以下の記事をご覧ください。

コンテナにインストールするパッケージは以下のとおりです。
CUDA、PyTorch、Transformersはバージョン依存関係によるエラーが起きやすいので、動作検証済のバージョン指定してインストールしています。
- CUDA:12.1
- Python:3.10
- PyTorch:2.2.2
- transformers:4.41.2
- accelerate
- triton
- tiktoken
- pytest
- wheel
- flash-attn
Ubuntuのコマンドラインで、Dockerfileを作成します。
mkdir phi3_inference
cd phi3_inference
nano DockerfileDockerfileに以下の記述を貼り付けます。
# ベースイメージ(CUDA)の指定
FROM nvidia/cuda:12.1.0-cudnn8-devel-ubuntu22.04
# 必要なパッケージをインストール
RUN apt-get update && apt-get install -y python3-pip python3-venv git nano
# 作業ディレクトリを設定
WORKDIR /app
# アプリケーションコードをコピー
COPY . /app
# Python仮想環境の作成
RUN python3 -m venv /app/.venv
# 仮想環境をアクティベートするコマンドを.bashrcに追加
RUN echo "source /app/.venv/bin/activate" >> /root/.bashrc
# JupyterLabのインストール
RUN /app/.venv/bin/pip install Jupyter jupyterlab
# PyTorchのインストール
RUN /app/.venv/bin/pip install torch==2.2.2 torchvision==0.17.2 torchaudio==2.2.2 triton --index-url https://download.pytorch.org/whl/cu121
# Transformer関連のインストール
RUN /app/.venv/bin/pip install transformers==4.41.2 tiktoken accelerate pytest wheel
# Flash attentionをインストール
RUN /app/.venv/bin/pip install flash-attn --no-build-isolation
# コンテナの起動時にbashを実行
CMD ["/bin/bash"]docker-compose.ymlでDockerコンテナの設定をします。
docker-compose.ymlのYAMLファイルを作成して開きます。
nano docker-compose.yml以下のコードをコピーして、YAMLファイルに貼り付けます。
services:
phi3_inference:
build:
context: .
dockerfile: Dockerfile
image: phi3_inference
runtime: nvidia
container_name: phi3_inference
ports:
- "8888:8888"
volumes:
- .:/app/phi3_inference
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: 1
capabilities: [gpu]
command: >
bash -c '/app/.venv/bin/jupyter lab --ip="*" --port=8888 --NotebookApp.token="" --NotebookApp.password="" --no-browser --allow-root'Dockerfileからビルドしてコンテナを起動します。
docker compose up
Dockerの起動後にブラウザの検索窓に”localhost:8888″を入力すると、Jupyter Labをブラウザで表示できます。
localhost:8888Phi-3の実装
Dockerコンテナで起動したJupyter Lab上でPhi-3の実装をします。
Jupyter Labのコードセルに次のコマンドを実行して、ライブラリをインポートします。
import torch
import transformers
from transformers import AutoModelForCausalLM, AutoTokenizer, pipelinePhi-3のモデルとトークナイザーを読み込みます。
model_id = "microsoft/Phi-3-medium-128k-instruct"
model = AutoModelForCausalLM.from_pretrained(
model_id,
device_map="cuda",
torch_dtype="auto",
trust_remote_code=True,
)
tokenizer = AutoTokenizer.from_pretrained(model_id)model_id : Phi-3のモデルタイプを指定します。
pipeline : テキスト生成タスクのためのTransformerのパイプラインを設定しています。
| モデルID | パラメータサイズ | コンテキスト長 | GPUメモリ使用量 |
|---|---|---|---|
| microsoft/Phi-3-mini-4k-instruct | 3.8億パラメータ | 4kトークン | 8GB |
| microsoft/Phi-3-mini-128k-instruct | 3.8億パラメータ | 128kトークン | 8GB |
| microsoft/Phi-3-small-8k-instruct | 70億パラメータ | 8kトークン | 15GB |
| microsoft/Phi-3-small-128k-instruct | 70億パラメータ | 128kトークン | 15GB |
| microsoft/Phi-3-medium-4k-instruct | 140億パラメータ | 4kトークン | 28GB |
| microsoft/Phi-3-medium-128k-instruct | 140億パラメータ | 128kトークン | 28GB |
Phi-3でテキスト生成

Phi-3を使って、英語での質問応答、日本語での質問応答、コード生成を試してみます。
英語での質問応答
なぜラクダは砂漠で生活できるのか?というプロンプトを英語で実行してみます。
messages = [
{"role": "system", "content": "You are an excellent chatbot"},
{"role": "user", "content": "Why can camels live in the desert?"}
]
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
)
generation_args = {
"max_new_tokens": 128,
"return_full_text": False,
"temperature": 0.6,
"do_sample": False,
}
output = pipe(messages, **generation_args)
print(output[0]['generated_text'])messages:モデルへのプロンプトを定義しています。「Why can camels live in the desert?」がプロンプトです。
pipeline:Transformerのパイプラインを実行してテキストを生成します。出力するトークン数や生成確率などを指定できます。
Why can camels live in the desert?
————————————–
(翻訳)
なぜラクダは砂漠で生活できるのか?
Camels are remarkably adapted to live in desert environments, thanks to a range of physiological and behavioral adaptations. Here are some key reasons why camels can thrive in the desert: 1. Water conservation: Camels can survive for long periods without water, thanks to their ability to store water in their bodies. They can drink up to 40 gallons of water in one go and can lose up to 25% of their body weight in water without suffering from dehydration. Their red blood cells are oval-shaped, which allows them to flow more easily when
以下省略
————————————————————————–
(翻訳)
ラクダは、広範な生理学的および行動的適応のおかげで、砂漠環境に驚くほど適応しています。以下は、ラクダが砂漠で繁栄できる主な理由です:
水の保存:ラクダは体内に水を蓄える能力のおかげで、長期間水なしで生き延びることができます。一度に最大40ガロンの水を飲むことができ、水分が体重の25%減少しても脱水症状に陥ることはありません。彼らの赤血球は楕円形をしており、水分が失われた時でも容易に流れることができます。
以下省略
日本語での質問応答
「なぜコアラはユーカリを食べるのですか?」というプロンプトを日本語で実行してみます。
messages = [
{"role": "system", "content": "あなたは日本語で回答するアシスタントです"},
{"role": "user", "content": "なぜコアラはユーカリを食べるのですか?"}
]
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
)
generation_args = {
"max_new_tokens": 256,
"return_full_text": False,
"temperature": 0.6,
"do_sample": False,
}
output = pipe(messages, **generation_args)
print(output[0]['generated_text'])なぜコアラはユーカリを食べるのですか?
コアラはユーカリの葉を食べるのは、その食事に適応しているからです。コアラは、ユーカリの葉に含まれる特定の化合物を効率的に消化できるように進化してきました。ユーカリの葉は、他の多くの植物に比べて栄養価が低く、タンニンやセルロースなどの消化しにくい成分が多く含まれています。しかし、コアラはユーカリの葉を効率的に消化するために、長い消化管と特殊な胃の構造を持っています。 コアラの胃には、食物を分解するための特殊な細菌が含まれて
コード生成
「Pythonのrequestsライブラリを使ってコードを生成してください。」というプロンプトを英語で投げてみます。
messages = [
{"role": "system", "content": "You are an excellent chatbot"},
{"role": "user", "content": "Please Generate the code using Python's requests library"}
]
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
)
generation_args = {
"max_new_tokens": 256,
"return_full_text": False,
"temperature": 0.6,
"do_sample": False,
}
output = pipe(messages, **generation_args)
print(output[0]['generated_text'])Generate the code using Python’s requests library.
———————————————————————
(翻訳)
Pythonのrequestsライブラリを使ってコードを生成してください。
モデルの応答
Certainly! Below is an example of how to use the `requests` library in Python to make a simple GET request to a web API. This example will retrieve data from a placeholder API provided by JSONPlaceholder, which is a fake online REST API for testing and prototyping.
First, ensure you have the `requests` library installed. If not, you can install it using pip:
```bash
pip install requests
```
Here's a simple Python script that uses the `requests` library to make a GET request to the JSONPlaceholder API to fetch a list of posts:
```python
import requests
# The URL of the API endpoint
url = 'https://jsonplaceholder.typicode.com/posts'
# Make a GET request to the API
response = requests.get(url)
# Check if the request was successful
if response.status_code == 200:
# Parse the response JSON
posts = response.json()
# Print the first 5 posts
for post in posts[:5]:
print(f"Post ID: {post['id']}")
print(f生成AI・LLMのコストでお困りなら
GPUのスペック不足で生成AIの開発が思うように進まないことはありませんか?
そんなときには、高性能なGPUをリーズナブルな価格で使えるGPUクラウドサービスがおすすめです!

GPUSOROBANは、生成AI・LLM向けの高速GPUを業界最安級の料金で使用することができます。
インターネット環境さえあれば、クラウド環境のGPUサーバーをすぐに利用可能です。
大規模な設備投資の必要がなく、煩雑なサーバー管理からも解放されます。







