
Self-RAGは、LLMが自己評価を行ってRAGの信頼性を向上させる手法です。
この記事では、生成された回答が事実に基づいているか、質問の解決に有用であるかを自己評価するSelf-RAGを構築します。
ざっくり言うと
- Self-RAGは、LLMが自己評価を行いRAGの信頼性を向上するための手法
- RAGエージェント構築にはLangGraphを使用する
- LLMには無料の日本語モデルのLlama-3-ELYZA-JP-8Bを使用する

LangGraphでSelf-RAGエージェントを構築する

Self-RAGでは、生成された回答が事実に基づいているか、質問の解決に有用であるかを自己評価し、必要に応じて再生成や質問の修正を行います。
この記事では、生成された回答に対して自己評価するSelf-RAGエージェントを、LangGraphを使って実装します。
LangGraphは、LangChainやLLMを使ってAIエージェントを構築するライブラリです。
LangGraphのワークフローは次のとおりです。
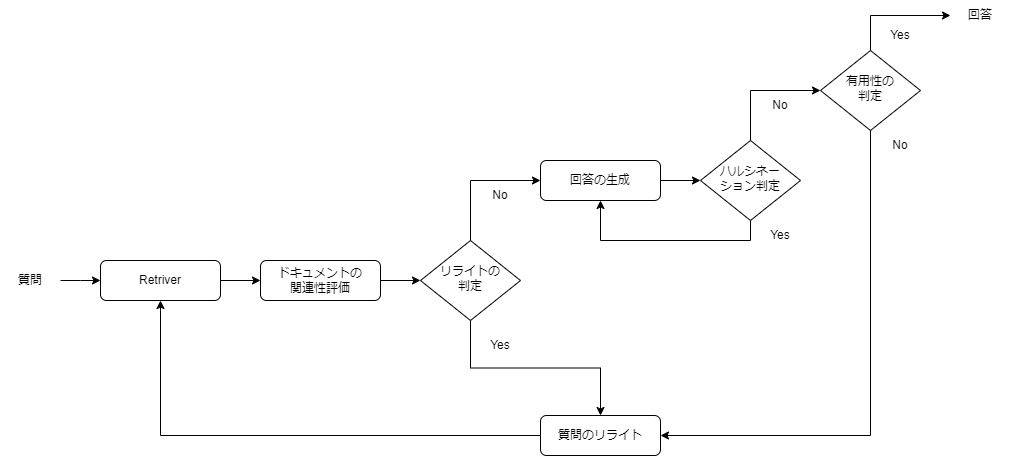
- Retriver:質問をもとにベクトルストアからドキュメントを取得する
- ドキュメントの関連性評価:ベクトルストアから取得したドキュメントが質問に関連しているか評価する
- リライトの判定:関連性評価に応じて、回答を生成するか、質問をリライトするか判定する
- 回答の生成:質問と取得したドキュメントとの関連性がある場合は、RAGで回答を生成する
- 質問のリライト:リライトの判定、または有用性の判定に応じて、質問のリライトを行う
- ハルシネーション判定:生成された回答が事実に基づいているかを評価する
- 有用性の判定:生成された回答が質問を解決するのに役に立つかを評価する

LangGraphの実行環境

この記事で用意した実行環境は以下のとおりです。
- GPU:NVIDIA A100 80GB
- GPUメモリ(VRAM):80GB
- OS :Ubuntu 22.04
- Docker
Dockerで環境構築
Dockerを使用してLangGraphの環境構築をします
Dockerの使い方は以下の記事をご覧ください。

Ubuntuのコマンドラインで、Dockerfileを作成します。
mkdir selfrag
cd selfrag
nano DockerfileDockerfileに以下の記述を貼り付けます。
# ベースイメージ(CUDA)の指定
FROM nvidia/cuda:12.1.0-cudnn8-devel-ubuntu22.04
# 必要なパッケージをインストール
RUN apt-get update && apt-get install -y python3-pip python3-venv git nano curl pciutils lshw python3-dev graphviz libgraphviz-dev pkg-config
RUN curl -fsSL https://ollama.com/install.sh | sh
# 作業ディレクトリを設定
WORKDIR /app
# アプリケーションコードをコピー
COPY . /app
# Python仮想環境の作成
RUN python3 -m venv /app/.venv
# 仮想環境をアクティベートするコマンドを.bashrcに追加
RUN echo "source /app/.venv/bin/activate" >> /root/.bashrc
# JupyterLabのインストール
RUN /app/.venv/bin/pip install Jupyter jupyterlab
# LangChain関連のインストール
RUN /app/.venv/bin/pip install ollama langchain-ollama langchain langsmith langgraph langchain-chroma faiss-gpu langchain-community langchain_huggingface langchain_core tiktoken pygraphviz
# コンテナの起動時にbashを実行
CMD ["/bin/bash"]FROM nvidia/cuda:12.1.0-cudnn8-devel-ubuntu22.04
CUDA12.1のベースイメージを指定しています。
RUN apt-get update && apt-get install -y python3-pip python3-venv git nano curl pciutils lshw python3-dev graphviz libgraphviz-dev pkg-config
必要なパッケージをインストールしています。
RUN curl -fsSL https://ollama.com/install.sh | sh
Linux版のOllamaをインストールしています。PythonでOllamaを動かす際にもLinux版Ollamaのインストールが必要になりますのでご注意ください。
RUN /app/.venv/bin/pip install Jupyter jupyterlab
JupyterLabをインストールしています。
RUN /app/.venv/bin/pip install ollama langchain-ollama langchain langsmith langgraph langchain-chroma faiss-gpu langchain-community langchain_huggingface langchain_core tiktoken pygraphviz
LangChainとOllama関連のパッケージをインストールしています。
LLMはOllamaのライブラリを使って動かしますので、PyTorchやTransformerは別途インストール不要です。
docker-compose.ymlでDockerコンテナの設定をします。
docker-compose.ymlのYAMLファイルを作成して開きます。
nano docker-compose.yml以下のコードをコピーして、YAMLファイルに貼り付けます。
services:
selfrag:
build:
context: .
dockerfile: Dockerfile
image: selfrag
runtime: nvidia
container_name: selfrag
ports:
- "8888:8888"
volumes:
- .:/app/selfrag
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: 1
capabilities: [gpu]
command: >
bash -c '/usr/local/bin/ollama serve & /app/.venv/bin/jupyter lab --ip="*" --port=8888 --NotebookApp.token="" --NotebookApp.password="" --no-browser --allow-root'bash -c ‘/usr/local/bin/ollama serve & /app/.venv/bin/jupyter lab –ip=”*” –port=8888 –NotebookApp.token=”” –NotebookApp.password=”” –no-browser –allow-root’
bash -c '/usr/local/bin/ollama serve
Ollama Serverを起動しています。PythonのOllamaを使用する際に、Ollama Serverを起動しておく必要がありますので、ご注意ください。
& /app/.venv/bin/jupyter lab --ip="*" --port=8888 --NotebookApp.token="" --NotebookApp.password="" --no-browser --allow-root'
JupyterLabを8888番ポートで起動しています。
Dockerfileからビルドしてコンテナを起動します。
docker compose up
Dockerの起動後にブラウザの検索窓に”localhost:8888″を入力すると、Jupyter Labをブラウザで表示できます。
localhost:8888環境変数・LLM・Retrieverの設定

Dockerコンテナで起動したJupyter Lab上でLangChainを使ったRAGの実装をします。
LangChainとTavilyのAPIに関する環境変数を設定します。
import os
from uuid import uuid4
unique_id = uuid4().hex[0:8]
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_PROJECT"] = f"selfrag - {unique_id}"
os.environ["LANGCHAIN_ENDPOINT"] = "https://api.smith.langchain.com"
os.environ["LANGCHAIN_API_KEY"] = "***************"
os.environ["TAVILY_API_KEY"] = "***************"unique_id = uuid4().hex[0:8]
8桁のランダムな一意の識別子unique_idを生成しています。
os.environ[“LANGCHAIN_TRACING_V2”] = “true”
この設定により、LangChainのトレースが可能になります。
os.environ[“LANGCHAIN_PROJECT”] = f”selfrag – {unique_id}”
angChainプロジェクトの名前を設定しています。ここでは、生成したunique_idを使用してプロジェクト名を「selfrag – {unique_id}」の形式で一意にしています。
os.environ[“LANGCHAIN_ENDPOINT”] = “https://api.smith.langchain.com”
LangChainのAPIエンドポイントを指定しています。
os.environ[“LANGCHAIN_API_KEY”] = “***************”
LangChain APIを利用するためのAPIキーを設定しています。
os.environ[“TAVILY_API_KEY”] = “***************”
Tavily APIを利用するためのAPIキーを設定しています。
日本語LLMモデル「Llama-3-ELYZA-JP-8B-q4_k_m.gguf」をダウンロードします。
!curl -L -o Llama-3-ELYZA-JP-8B-q4_k_m.gguf "https://huggingface.co/elyza/Llama-3-ELYZA-JP-8B-GGUF/resolve/main/Llama-3-ELYZA-JP-8B-q4_k_m.gguf?download=true"Llama-3-ELYZA-JPについては、別記事で詳しく解説しています。

LLMの実行にはOllamaを使用します。
LLMのモデルがOllama使えるようにプロンプトテンプレートを指定して、モデルを作成します。
import ollama
from langchain_ollama.chat_models import ChatOllama
modelfile='''
FROM ./Llama-3-ELYZA-JP-8B-q4_k_m.gguf
TEMPLATE """{{ if .System }}<|start_header_id|>system<|end_header_id|>
{{ .System }}<|eot_id|>{{ end }}{{ if .Prompt }}<|start_header_id|>user<|end_header_id|>
{{ .Prompt }}<|eot_id|>{{ end }}<|start_header_id|>assistant<|end_header_id|>
{{ .Response }}<|eot_id|>"""
PARAMETER stop "<|start_header_id|>"
PARAMETER stop "<|end_header_id|>"
PARAMETER stop "<|eot_id|>"
PARAMETER stop "<|reserved_special_token"
'''
ollama.create(model='elyza8b', modelfile=modelfile)
llm = ChatOllama(model="elyza8b", temperature=0)
llm.invoke(("human","推しの子を知っていますか?")).contentFROM ./Llama-3-ELYZA-JP-8B-q4_k_m.gguf
ダウンロードしたモデルのパスが入ります。
TEMPLATE “””{{ if .System }}<|start_header_id|>system<|end_header_id|>…
モデルで使用するプロンプトテンプレートが入ります。
ollama.create(model=’elyza8b’, modelfile=modelfile)
モデルとプロンプトテンプレートを使ってOllama用のモデルを作成します。modelにはOllamaで呼び出す際に使用する名前をつけられます。
ChatOllama(model=”elyza8b”, temperature=0)
ChatOllamaをインスタンス化してLLMモデルを実行できる状態にしています。
確認のため、LLMからテキストを生成しています。
'「推しの子」は、2022年から連載が始まった漫画作品です。作者は田中芳樹で、原作は橘由宇です。\n\n物語の舞台は近未来の日本で、主人公の「推し」と呼ばれる人物が、超高度なAIを搭載した子ども「チャイルド」を育成する施設「グリーフシード」に勤務しています。推しは、チャイルドの教育係として働く中で、チャイルドと深い絆を結び、共に成長していきます。\n\n「推しの子」は、AIや人工知能が日常生活に浸透する近未来社会を舞台に、人間とAIの関係性、倫理、感情などをテーマに描かれていますollama.createのエラー「invalid digest format」の解消方法

Ollamaの詳しい使い方は、別の記事で解説しています。

ベクトルストアに格納するデータをWikipediaから取得します。
Wikipediaは、『推しの子』のページを指定しています。
from langchain_community.document_loaders import WebBaseLoader
from langchain.text_splitter import CharacterTextSplitter
urls = [
"https://ja.wikipedia.org/wiki/%E3%80%90%E6%8E%A8%E3%81%97%E3%81%AE%E5%AD%90%E3%80%91",
]
docs = [WebBaseLoader(url).load() for url in urls]
docs_list = [item for sublist in docs for item in sublist]
text_splitter = CharacterTextSplitter.from_tiktoken_encoder(
separator = "\n",
chunk_size= 500,
chunk_overlap=50,
)
doc_splits = text_splitter.split_documents(docs_list)
doc_splits[5]WebBaseLoader(url).load()
指定したWebページのHTMLコンテンツを取得し、HTMLコンテンツを解析し、使いやすいデータ構造に変換し、そのデータを読み込みます。
CharacterTextSplitter.from_tiktoken_encoder…
テキストを指定された条件でチャンクに分割します。
separator = “\n”
チャンクを分割する際の区切り文字を「\n」として指定します。
chunk_size
各チャンクの最大トークン数を設定します。
chunk_overlap
各チャンク間で重複するトークン数を設定します。
確認のため、分割したチャンクを1つ表示しています。
Document(metadata={'source': 'https://ja.wikipedia.org/wiki/%E3%80%90%E6%8E%A8%E3%81%97%E3%81%AE%E5%AD%90%E3%80%91', 'title': '【推しの子】 - Wikipedia', 'language': 'ja'}, page_content='原作\n赤坂アカ、横槍メンゴ\n脚本\n中屋敷法仁\n演出\n中屋敷法仁\n音楽\n和田俊輔、はるきねる\n製作\n演劇【推しの子】製作委員会\n上演劇場\nシアターH梅田芸術劇場 シアター・ドラマシティ\n上演期間\n第1回:2024年12月13日 - 22日(予定)第2回:2024年12月26日 - 29日(予定)\nテンプレート - ノート\nプロジェクト\n漫画・テレビドラマ・映画\nポータル\n漫画・テレビ・ドラマ・映画・舞台芸術\n『【推しの子】』(おしのこ)は、原作:赤坂アカ、作画:横槍メンゴによる日本の漫画作品。\n『週刊ヤングジャンプ』(集英社)にて、2020年21号より連載中[1]。1週遅れでウェブコミック配信サイト『少年ジャンプ+』(集英社)でも毎週木曜更新で連載されている[2]。')Wikipediaのデータをもとにベクトル検索が可能なRetrieverを構築します。
from langchain.vectorstores import FAISS
from langchain_huggingface import HuggingFaceEmbeddings
embedding = HuggingFaceEmbeddings(model_name="intfloat/multilingual-e5-large")
vectorstore = FAISS.from_documents(doc_splits, embedding)
retriever = vectorstore.as_retriever(k=4)
question = "アクアとは"
retriever.invoke(question)HuggingFaceEmbeddings(model_name=”intfloat/multilingual-e5-large”)
テキストをベクトル表現に変換する埋め込みモデルを読み込みます。
intfloat/multilingual-e5-largeは日本語性能が高く、無料で使える埋め込みモデルです。
FAISS.from_documents(splits, embedding)
ベクトル検索用のインデックスを作成しています。インデックスはDBのテーブルのような概念です。
vectorstore.as_retriever()
インデックスからRetriverを作成しています。
retriever.invoke(question)
質問の内容に類似したドキュメントをRetriverで検索します。
Retriverから取得したデータを確認しています。
[Document(metadata={'source': 'https://ja.wikipedia.org/wiki/%E3%80%90%E6%8E%A8%E3%81%97%E3%81%AE%E5%AD%90%E3%80%91', 'title': '【推しの子】 - Wikipedia', 'language': 'ja'}, page_content='^ 家族や親しい友人からも「アクア」と呼ばれており、自分のことも「アクア」と言っている。「アクアマリン」と呼ばれたり「愛久愛海」と漢字表記される場面はほとんどなく、命名時や陽東高校の入試面接時などのわずかな場面に限られ、呼ばれる場面では「すごい名前(キラキラネーム)」などと驚かれる[56]。\n^ 初登場時は「ゴロー」と表記されフルネームが明かされなかったが、後のアクアの回想[58]で明かされる。テレビアニメ版では第1期第1話からエンドクレジットでフルネームで役名表記されているほか、アクアが自身(吾郎)の死体の行方についての報道をネット上から検索しようとする場面など、原作では「ゴロー」であった場面[59]でも、フルネームの「雨宮吾郎」に変更されている。'),
以下省略各種Chainの構築

LangGraphのワークフロー内の関数で使用するChainを構築していきます。
- ドキュメントの関連性を評価するChain
- 回答を生成するChain
- ハルシネーションを評価するChain
- 回答の有用性を評価するChain
- 質問をリライトするChain
ユーザーの質問と取得したドキュメントが関連しているかを評価するChainを構築しています。
評価はバイナリースコア(yes または no)で表され、その結果はJSON形式で返されます。
# retrieval_chain
from langchain_core.output_parsers import JsonOutputParser
from langchain_core.prompts import PromptTemplate
prompt = PromptTemplate(
template="""<|begin_of_text|><|start_header_id|>system<|end_header_id|>
あなたは、取得された文書がユーザーの質問に関連しているかを評価する採点者です。\n
もし文書がユーザーの質問に関連するキーワードを含んでいる場合、その文書を関連性があると評価してください。\n
厳密なテストである必要はありません。目的は誤った取得をフィルタリングすることです。\n
文書が質問に関連しているかどうかを示すバイナリスコア「yes」または「no」を付けてください。\n
バイナリスコアを単一のキー「score」で、前置きや説明なしにJSON形式で提供してください。
<|eot_id|><|start_header_id|>user<|end_header_id|>
質問: {question} \n
事実: \n\n {documents} \n\n <|eot_id|><|start_header_id|>assistant<|end_header_id|>
""",
input_variables=["question", "documents"],
)
llm = ChatOllama(model="elyza8b",format="json",temperature=0)
retrieval_chain = prompt | llm | JsonOutputParser()
question = "アクアとは?"
docs = retriever.invoke(question)
doc_txt = docs[0].page_content
print(retrieval_chain.invoke({"question": question, "documents": doc_txt}))
print("\nユーザーの質問:\n" + question)
print("\n取得したドキュメント:\n" + docs[0].page_content)PromptTemplate()
プロンプトのテンプレートを定義するために使用されるクラスです。テンプレート内で、指定された変数に動的に値を埋め込み、AIに指示を与えるプロンプトを生成します。
template には、AIに対してどのような指示を与えるかを記述します。
<|begin_of_text|><|start_header_id|>system<|end_header_id|> ...<|eot_id|>には、システムプロンプトが入ります。
<|start_header_id|>user<|end_header_id|>...<|eot_id|>には、ユーザーの質問が入ります。
<|start_header_id|>assistant<|end_header_id|>...には、LLMの回答が入ります。
input_variables では、テンプレート内で動的に置き換えられる変数名をリストで指定します。
この場合、questionの変数が指定されています。
prompt | llm | JsonOutputParser()
プロンプトの作成から、LLMによる応答の生成、JSON形式の出力までを一連の処理として組み合わせたChainを構築しています。
retrieval_chain.invoke({“question”: question})
questionをプロンプトに渡して、定義したChainを実行しています。
出力結果の確認
{'score': 'yes'}
ユーザーの質問:
アクアとは?
取得したドキュメント:
^ 家族や親しい友人からも「アクア」と呼ばれており、自分のことも「アクア」と言っている。「アクアマリン」と呼ばれたり「愛久愛海」と漢字表記される場面はほとんどなく、命名時や陽東高校の入試面接時などのわずかな場面に限られ、呼ばれる場面では「すごい名前(キラキラネーム)」などと驚かれる[56]。
^ 初登場時は「ゴロー」と表記されフルネームが明かされなかったが、後のアクアの回想[58]で明かされる。テレビアニメ版では第1期第1話からエンドクレジットでフルネームで役名表記されているほか、アクアが自身(吾郎)の死体の行方についての報道をネット上から検索しようとする場面など、原作では「ゴロー」であった場面[59]でも、フルネームの「雨宮吾郎」に変更されている。回答を生成するChainを構築します。
# generate_chain
from langchain_core.output_parsers import StrOutputParser
prompt = PromptTemplate(
template="""<|begin_of_text|><|start_header_id|>system<|end_header_id|>
あなたは質問応答のためのアシスタントです。
次のドキュメントを使って質問に答えてください。
答えがわからない場合は、正直に「わかりません」と言ってください。
回答は最大で3文にまとめ、簡潔にしてください。
<|eot_id|><|start_header_id|>user<|end_header_id|>
質問: {question}
コンテキスト: {documents}
回答: <|eot_id|><|start_header_id|>assistant<|end_header_id|>""",
input_variables=["question", "documents"],
)
llm = ChatOllama(model="elyza8b",temperature=0)
generate_chain = prompt | llm | StrOutputParser()
question = "アクアとは?"
docs = retriever.invoke(question)
generation = generate_chain.invoke({"documents": docs, "question": question})
print("\nユーザーの質問:\n" + question)
print("\n生成した回答:\n" + generation)prompt | llm | StrOutputParser()
プロンプトの作成から、LLMによる応答の生成、文字列形式の出力までを一連の処理として組み合わせたChainを構築しています。
出力結果の確認
ユーザーの質問:
アクアとは?
生成した回答:
アクアは、【推しの子】という作品の主人公で、雨宮吾郎が星野アイの息子として転生した姿です。芸名は「アクア」や「星野アクア」と表記されますが、本名で呼ばれることはほとんどないとされています。生成された回答が事実に基づいているかどうかを判定するChainを構築しています
# hallucination_chain
prompt = PromptTemplate(
template=""" <|begin_of_text|><|start_header_id|>system<|end_header_id|>
あなたは、ある回答が事実に基づいているか、または事実によって裏付けられているかを評価する採点者です
<|eot_id|><|start_header_id|>user<|end_header_id|>
以下は事実です:
\n ------- \n
{documents}
\n ------- \n
以下は回答です: {generation}
回答が事実に基づいているか、または裏付けられているかを示すために、
バイナリスコアを「score」というキーを持つJSON形式で、「yes」または「no」で評価してください。
<|eot_id|><|start_header_id|>assistant<|end_header_id|>""",
input_variables=["generation", "documents"],
)
llm = ChatOllama(model="elyza8b",format="json",temperature=0)
hallucination_chain = prompt | llm | JsonOutputParser()
print(hallucination_chain.invoke({"documents": docs, "generation": generation}))
print("\n回答:\n" + generation)
print("\n事実:\n" + docs[0].page_content)出力結果の確認
{'score': 'yes'}
回答:
アクアは、【推しの子】という作品の主人公で、雨宮吾郎が星野アイの息子として転生した姿です。芸名は「アクア」や「星野アクア」と表記されますが、本名で呼ばれることはほとんどないとされています。
事実:
^ 家族や親しい友人からも「アクア」と呼ばれており、自分のことも「アクア」と言っている。「アクアマリン」と呼ばれたり「愛久愛海」と漢字表記される場面はほとんどなく、命名時や陽東高校の入試面接時などのわずかな場面に限られ、呼ばれる場面では「すごい名前(キラキラネーム)」などと驚かれる[56]。
^ 初登場時は「ゴロー」と表記されフルネームが明かされなかったが、後のアクアの回想[58]で明かされる。テレビアニメ版では第1期第1話からエンドクレジットでフルネームで役名表記されているほか、アクアが自身(吾郎)の死体の行方についての報道をネット上から検索しようとする場面など、原作では「ゴロー」であった場面[59]でも、フルネームの「雨宮吾郎」に変更されている。生成された回答が質問を解決するのに役に立つかを判定するChainを構築しています
# answer_chain
prompt = PromptTemplate(
template="""<|begin_of_text|><|start_header_id|>system<|end_header_id|>
あなたは、回答が質問を解決するのに役立つかどうかを評価する採点者です。
回答が質問を解決するのに役立つかどうかを示すために、バイナリースコア「yes」または「no」を付けてください。
バイナリースコアは、前置きや説明なしで、単一のキー「score」を持つJSONとして提供してください。
<|eot_id|><|start_header_id|>user<|end_header_id|>
回答:
\n ------- \n
{generation}
\n ------- \n
質問: {question}
<|eot_id|><|start_header_id|>assistant<|end_header_id|>""",
input_variables=["generation", "question"],
)
llm = ChatOllama(model="elyza8b",format="json",temperature=0)
answer_chain = prompt | llm | JsonOutputParser()
print(answer_chain.invoke({"question": question, "generation": generation}))
print("\n回答:\n" + generation)
print("\n質問:\n" + question)出力結果の確認
{'score': 'yes'}
回答:
アクアは、【推しの子】という作品の主人公で、雨宮吾郎が星野アイの息子として転生した姿です。芸名は「アクア」や「星野アクア」と表記されますが、本名で呼ばれることはほとんどないとされています。
質問:
アクアとは?生成された回答が質問を解決するのに役に立つかを判定するChainを構築しています
#Rewrite_chain
re_write_prompt = PromptTemplate(
template="""あなたは、入力された質問をベクターストアでの検索に最適化された形に書き直すライターです。\n
最初の質問と回答を確認し、改良された質問を前置きなしで作成してください。\n
最初の質問:\n\n {question}。
改良された質問:\n """,
input_variables=["question"],
)
llm = ChatOllama(model="elyza8b",temperature=0)
rewriter_chain = re_write_prompt | llm | StrOutputParser()
rewriter_chain.invoke({"question": question})出力結果の確認
'アクアの定義'LangGraphワークフローで使用する関数の定義

LangGraphのワークフローで使用する各種関数の定義をしていきます。
- GraphStateの定義
- Retriver関数
- 回答を生成する関数
- ドキュメントの関連性を評価する関数
- 質問をリライトする関数
- リライトを判断する関数
- 「ハルシネーション」と「回答の有用性」を判定する関数
必要なライブラリをインポートします。
from pprint import pprint
from typing import List
from langchain_core.documents import Document
from typing_extensions import TypedDictGraphを初期化したときのノードやエッジの状態を定義します。
class GraphState(TypedDict):
question: str
generation: str
documents: List[str]Retriverを使用してベクトルストアからユーザーの質問に関連するドキュメントを取得します。
「question(質問)」と「documents(ドキュメント)」、「steps」を次のステップで使用するため、状態 (state) を更新します。
# Retriver関数
def retrieve(state):
print("---RETRIEVE---")
question = state["question"]
documents = retriever.invoke(question)
return {"documents": documents, "question": question}ユーザーの質問にもとづいた回答を生成します。
「documents(ドキュメント)」と「question(質問)」、「generation(回答)」、「steps」を次のステップで使用するため、状態 (state) を更新します。
# 回答を生成する関数
def generate(state):
print("---GENERATE---")
question = state["question"]
documents = state["documents"]
generation = generate_chain.invoke({"documents": documents, "question": question})
return {
"documents": documents,
"question": question,
"generation": generation,
}取得したドキュメントが質問に関連しているかどうかを評価します。
関連性の高いドキュメントを選別し、リストに格納します。
関連性が低いドキュメントが存在する場合は、Web検索に進むフラグを立てます。
「filtered_docs(関連性のあるドキュメント)」と「question(質問)」、「search(検索)」、「steps」を次のステップで使用するため、状態(sate)を更新します。
# ドキュメントの関連性を評価する関数
def grade_documents(state):
print("---CHECK DOCUMENT RELEVANCE TO QUESTION---")
question = state["question"]
documents = state["documents"]
filtered_docs = []
search = "No"
for d in documents:
score = retrieval_chain.invoke(
{"question": question, "documents": d.page_content}
)
grade = score["score"]
if grade == "yes":
print("---GRADE: DOCUMENT RELEVANT---")
filtered_docs.append(d)
else:
print("---GRADE: DOCUMENT NOT RELEVANT---")
continue
return {
"documents": filtered_docs,
"question": question,
}rewriter_chainを使用して、元の質問を改善した質問にリライトしています。
関連性が低いドキュメントが存在する場合、Web検索が必要なフラグを立てます。
「question(質問)」、「documents(ドキュメント)」を次のステップで使用するため、状態(sate)を更新します。
# 質問をリライトする関数
def transform_query(state):
print("---TRANSFORM QUERY---")
question = state["question"]
documents = state["documents"]
better_question = rewriter_chain.invoke({"question": question})
return {"documents": documents, "question": better_question}ドキュメントが質問に適切に関連しているかどうかを基に、生成された回答を使用するか、追加のウェブ検索を行うかを決定します。
この関数は「websearch」または「generate」を返します。この返り値は、後続のステップで利用されます。
# リライトを判断する関数
def decide_to_generate(state):
print("---ASSESS GRADED DOCUMENTS---")
state["question"]
filtered_documents = state["documents"]
if not filtered_documents:
print(
"---DECISION: ALL DOCUMENTS ARE NOT RELEVANT TO QUESTION, TRANSFORM QUERY---"
)
return "transform_query"
else:
print("---DECISION: GENERATE---")
return "generate"生成された回答がドキュメントに基づいているか(ハルシネーション)を評価します。
ハルシネーションのチェックを通過した場合、回答が質問を解決するのに役に立つか(回答の有用性)を評価します。
# 「ハルシネーション」と「回答の有用性」を判定する関数
def grade_generation_v_documents_and_question(state):
print("---CHECK HALLUCINATIONS---")
question = state["question"]
documents = state["documents"]
generation = state["generation"]
score = hallucination_chain.invoke(
{"documents": documents, "generation": generation}
)
grade = score["score"]
if grade == "yes":
print("---DECISION: GENERATION IS GROUNDED IN DOCUMENTS---")
print("---GRADE GENERATION vs QUESTION---")
score = answer_chain.invoke({"question": question, "generation": generation})
grade = score["score"]
if grade == "yes":
print("---DECISION: GENERATION ADDRESSES QUESTION---")
return "useful"
else:
print("---DECISION: GENERATION DOES NOT ADDRESS QUESTION---")
return "not useful"
else:
pprint("---DECISION: GENERATION IS NOT GROUNDED IN DOCUMENTS, RE-TRY---")
return "not supported"LangGraphワークフローの構築

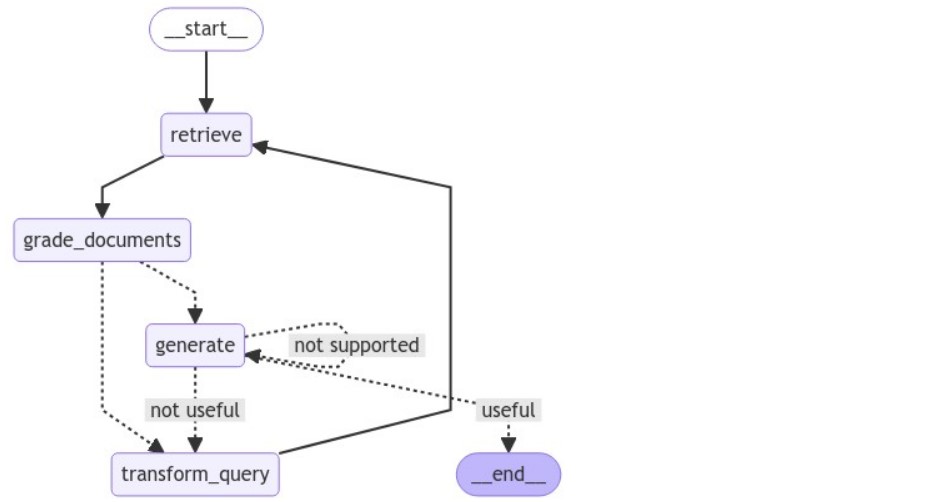
LangGraphのワークフローを構築していきます。
ワークフローは図のような流れになります。
- Retriver:質問をもとにベクトルストアからドキュメントを取得する
- ドキュメントの関連性評価:ベクトルストアから取得したドキュメントが質問に関連しているか評価する
- リライトの判定:関連性評価に応じて、回答を生成するか、質問をリライトするか判定する
- 回答の生成:質問と取得したドキュメントとの関連性がある場合は、RAGで回答を生成する
- 質問のリライト:リライトの判定、または有用性の判定に応じて、質問のリライトを行う
- ハルシネーション判定:生成された回答が事実に基づいているかを評価する
- 有用性の判定:生成された回答が質問を解決するのに役に立つかを評価する
必要なライブラリをインポートします。
from langgraph.graph import END, StateGraph, START
from IPython.display import Image, display
from langchain_core.runnables.graph import CurveStyle, MermaidDrawMethod, NodeStylesGraphのワークフローを作成し、各ノードを追加します。
#Graphのワークフローを作成
workflow = StateGraph(GraphState)
#ノードの追加
workflow.add_node("retrieve", retrieve)
workflow.add_node("grade_documents", grade_documents)
workflow.add_node("generate", generate)
workflow.add_node("transform_query", transform_query)StateGraph(GraphState)
StateGraphは、複数の処理ステップ(ノード)をグラフ構造として扱い、それぞれのノード間で状態を渡しながら処理を進めることができます。
workflow.add_node(“web_search”, web_search)
web_searchという名前のノードがワークフローに追加され、web_search関数がそのノードで実行されます。
ワークフローにおけるエッジ(ノード間の接続)の設定を行います。
エッジは、各ノードをどの順序で実行するか、どのような条件で次のノードに進むかを定義します。
# Edgeの追加
workflow.add_edge(START, "retrieve")
workflow.add_edge("retrieve", "grade_documents")
workflow.add_conditional_edges(
"grade_documents",
decide_to_generate,
{
"transform_query": "transform_query",
"generate": "generate",
},
)
workflow.add_edge("transform_query", "retrieve")
workflow.add_conditional_edges(
"generate",
grade_generation_v_documents_and_question,
{
"not supported": "generate",
"useful": END,
"not useful": "transform_query",
},
)workflow.add_edge():エッジの追加
workflow.add_edge(START, "retrieve")
ワークフローの開始点 START から "retrieve" ステップに進みます。
workflow.add_edge("retrieve", "grade_documents")
"retrieve" ステップから "grade_documents" ステップに進みます。
workflow.add_edge("transform_query", "retrieve")
"transform_query" が完了した後に "retrieve" ステップに進みます。
workflow.add_conditional_edges():条件付きエッジの追加
workflow.add_conditional_edges(
"grade_documents",
decide_to_generate,
{
"transform_query": "transform_query",
"generate": "generate",
},
)
"grade_documents"ノードは、質問と取得したドキュメントの関連性を評価するステップです。
decide_to_generate 関数は2つの条件分岐をします。
1)質問のリライトが必要と判断した場合、ワークフローは "transform_query" ステップに進みます。
2)回答の生成に進むと判断した場合、ワークフローは "generate" ステップに進みます。
workflow.add_conditional_edges(
"generate",
grade_generation_v_documents_and_question,
{
"not supported": "generate",
"useful": END,
"not useful": "transform_query",
},
)
"generate"ノードは、質問に対して応答を生成するステップです。
grade_generation_v_documents_and_question関数は次の3つの条件分岐をします。
1)生成された応答がドキュメントに基づいていない、または信頼性が低いと判断された場合、"not supported"が返され、ワークフローは再度"generate"ノードに戻り、新しい応答が生成されます。
2)生成された応答が質問に対して有用であると評価された場合、"useful"が返され、ワークフローはENDに進み、プロセスが完了します。
3)生成された応答が質問に対して有用でないと判断された場合、"not useful"が返され、ワークフローは再度"transform_query"ノードに戻り、質問をリライトして生成し直します。
全体のワークフローをコンパイルして、実行可能な形にします。
# コンパイル
app = workflow.compile()定義したLangGraphワークフローのグラフ構造を、Mermaid形式で可視化します。
# ワークフローの可視化
display(
Image(
app.get_graph().draw_mermaid_png(
draw_method=MermaidDrawMethod.API,
)
)
)
Self-RAGエージェントに『推しの子』について聞く

構築したSelf-RAGエージェントに『推しの子』について質問をしてみます。
RAGエージェントに質問する(1)
「星野愛久愛海の読みを教えて下さい」と質問してみます。
from pprint import pprint
inputs = {"question": "星野愛久愛海の読みを教えて下さい"}
for output in app.stream(inputs):
for key, value in output.items():
pprint(f"Node '{key}':")
pprint("\n---\n")
pprint(value["generation"])星野愛久愛海の読みを教えて下さい
—RETRIEVE—
“Node ‘retrieve’:”
‘\n—\n’
—CHECK DOCUMENT RELEVANCE TO QUESTION—
—GRADE: DOCUMENT NOT RELEVANT—
—GRADE: DOCUMENT RELEVANT—
—GRADE: DOCUMENT RELEVANT—
—GRADE: DOCUMENT RELEVANT—
—ASSESS GRADED DOCUMENTS—
—DECISION: GENERATE—
“Node ‘grade_documents’:”
‘\n—\n’
—GENERATE—
—CHECK HALLUCINATIONS—
—DECISION: GENERATION IS GROUNDED IN DOCUMENTS—
—GRADE GENERATION vs QUESTION—
—DECISION: GENERATION ADDRESSES QUESTION—
“Node ‘generate’:”
‘\n—\n’
‘星野愛久愛海の読みは「ほしの あくあまりん」です。’
RAGエージェントに質問する(2)
「有馬かなとMEMちょはどちらの身長が高いですか?」と質問してみます。
inputs = {"question": "有馬かなとMEMちょはどちらの身長が高いですか?"}
for output in app.stream(inputs):
for key, value in output.items():
pprint(f"Node '{key}':")
pprint("\n---\n")
pprint(value["generation"])有馬かなとMEMちょはどちらの身長が高いですか?
—RETRIEVE—
“Node ‘retrieve’:”
‘\n—\n’
—CHECK DOCUMENT RELEVANCE TO QUESTION—
—GRADE: DOCUMENT RELEVANT—
—GRADE: DOCUMENT RELEVANT—
—GRADE: DOCUMENT NOT RELEVANT—
—GRADE: DOCUMENT NOT RELEVANT—
—ASSESS GRADED DOCUMENTS—
—DECISION: GENERATE—
“Node ‘grade_documents’:”
‘\n—\n’
—GENERATE—
—CHECK HALLUCINATIONS—
—DECISION: GENERATION IS GROUNDED IN DOCUMENTS—
—GRADE GENERATION vs QUESTION—
—DECISION: GENERATION ADDRESSES QUESTION—
“Node ‘generate’:”
‘\n—\n’
‘有馬かなとMEMちょの身長を比較すると、有馬かなは150cm、MEMちょは155cmなので、MEMちょが5cm高いです。’
RAGエージェントに質問する(3)
「有馬かなと黒川あかねの共通点を教えて下さい。」と質問してみます。
inputs = {"question": "有馬かなと黒川あかねの共通点を教えて下さい。"}
for output in app.stream(inputs):
for key, value in output.items():
pprint(f"Node '{key}':")
pprint("\n---\n")
pprint(value["generation"])質問:
有馬かなと黒川あかねの共通点を教えて下さい。
—RETRIEVE—
“Node ‘retrieve’:”
‘\n—\n’
—CHECK DOCUMENT RELEVANCE TO QUESTION—
—GRADE: DOCUMENT RELEVANT—
—GRADE: DOCUMENT NOT RELEVANT—
—GRADE: DOCUMENT NOT RELEVANT—
—GRADE: DOCUMENT RELEVANT—
—ASSESS GRADED DOCUMENTS—
—DECISION: GENERATE—
“Node ‘grade_documents’:”
‘\n—\n’
—GENERATE—
—CHECK HALLUCINATIONS—
—DECISION: GENERATION IS GROUNDED IN DOCUMENTS—
—GRADE GENERATION vs QUESTION—
—DECISION: GENERATION ADDRESSES QUESTION—
“Node ‘generate’:”
‘\n—\n’
‘有馬かなと黒川あかねの共通点は、子役出身で女優であることです。また、同い年であり、互いに実力を認め合うライバル関係にあります。’
生成AI・LLMのコストでお困りなら
GPUのスペック不足で生成AIの開発が思うように進まないことはありませんか?
そんなときには、高性能なGPUをリーズナブルな価格で使えるGPUクラウドサービスがおすすめです!

GPUSOROBANは、高性能GPU「NVIDIA H200」を業界最安級の料金で使用することができます。
NVIDIA H200は、生成AI・LLMの計算にかかる時間を大幅に短縮することが可能です。
クラウドで使えるため、大規模な設備投資の必要がなく、煩雑なサーバー管理からも解放されます。







