
Tavily Searchは、AIエージェント用に設計された検索エンジンAPIで、リアルタイムかつ正確な情報を提供します。
外部情報の検索や抽出が可能でRAG向けに最適化されており、LangChainやLlamaIndexへの統合が簡単にできます。
この記事では、Tavily Search APIキーの発行から、LangChainにおける使い方まで紹介します。
ざっくり言うと
- Tavily Search APIは、AIエージェント向けに設計された検索エンジンAPI
- Tavily Search APIキーの発行方法がわかる
- LangChainにおけるTavily Search APIの使い方がわかる

Tavily Search APIとは

Tavily Search APIは、AIエージェント用に設計された検索エンジンAPIで、リアルタイムかつ正確な情報を提供します。
外部情報の検索や抽出が可能でRAG向けに最適化されており、LangChainやLlamaIndexへの統合が簡単にできます。
単一のAPI呼び出しで情報の検索、フィルタリング、抽出を行える便利なツールです。

Tavily Search APIの料金
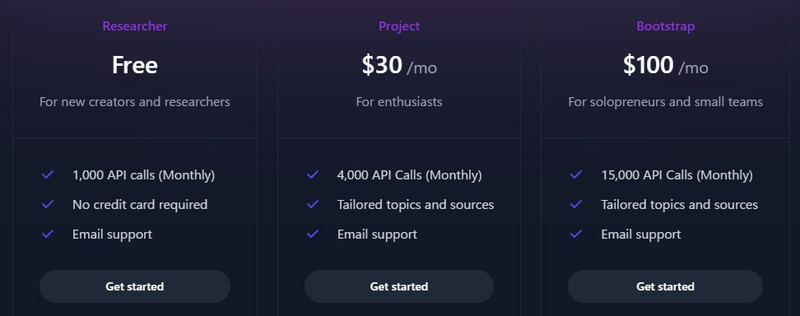
Tavily Search APIの料金プランは、APIのコール数に応じてプランが用意されています。
月に1,000回まで無料でAPIコールが可能です。
無料で使用する場合は、クレジットカードの登録は不要で気軽に試すことができます。
Tavily Search APIキーの発行

Tavily Search APIを使用するには、APIキーが必要になります。
以下の手順でAPIキーの発行ができます。
Tavily公式サイトにアクセスし、「Get Started」ボタンをクリックします。

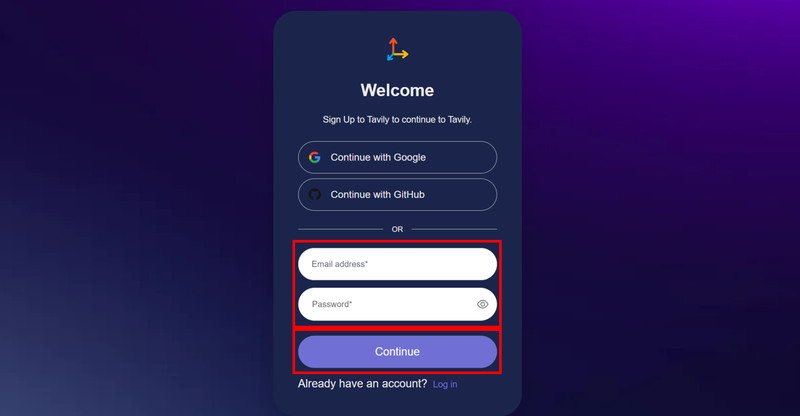
「Sign In」ボタンをクリックします。
「メールアドレス」、「パスワード」を入力し、「Continue」 ボタンをクリックします。
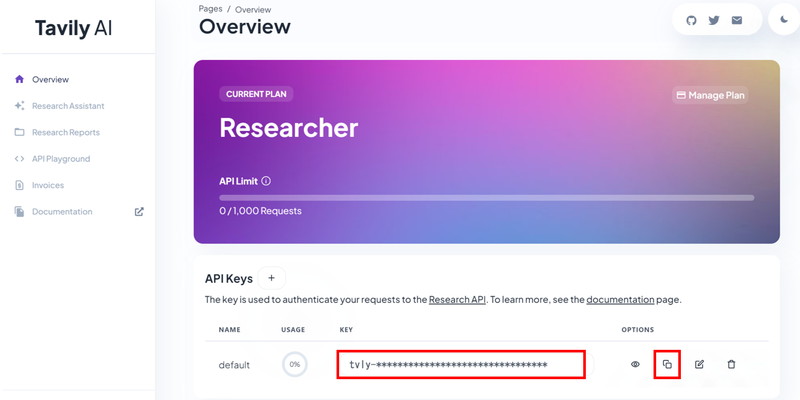
ホーム画面に発行されたAPIキーが表示されるので、これをコピーして安全な場所に保存します。
LangChainの環境構築

この記事ではLangChainの環境で、Tavily search APIの使い方を紹介します。
用意した実行環境は以下のとおりです。
- GPU:NVIDIA A100 80GB
- GPUメモリ(VRAM):80GB
- OS :Ubuntu 22.04
- Docker
Dockerで環境構築
Dockerを使用してLangChainの環境構築をします
Dockerの使い方は以下の記事をご覧ください。

Ubuntuのコマンドラインで、Dockerfileを作成します。
mkdir tavily
cd tavily
nano DockerfileDockerfileに以下の記述を貼り付けます。
# ベースイメージ(CUDA)の指定
FROM nvidia/cuda:12.1.0-cudnn8-devel-ubuntu22.04
# 必要なパッケージをインストール
RUN apt-get update && apt-get install -y python3-pip python3-venv git nano curl
RUN curl -fsSL https://ollama.com/install.sh | sh
# 作業ディレクトリを設定
WORKDIR /app
# アプリケーションコードをコピー
COPY . /app
# Python仮想環境の作成
RUN python3 -m venv /app/.venv
# 仮想環境をアクティベートするコマンドを.bashrcに追加
RUN echo "source /app/.venv/bin/activate" >> /root/.bashrc
# JupyterLabのインストール
RUN /app/.venv/bin/pip install Jupyter jupyterlab
# LangChain関連のインストール
RUN /app/.venv/bin/pip install ollama langchain-ollama langchain langsmith langchain-chroma faiss-gpu langchain-community langchain_huggingface langchain_core tiktoken tavily-python
# コンテナの起動時にbashを実行
CMD ["/bin/bash"]FROM nvidia/cuda:12.1.0-cudnn8-devel-ubuntu22.04
CUDA12.1のベースイメージを指定しています。
RUN apt-get update && apt-get install -y python3-pip python3-venv git nano curl
必要なパッケージをインストールしています。
RUN curl -fsSL https://ollama.com/install.sh | sh
Linux版のOllamaをインストールしています。PythonでOllamaを動かす際にもLinux版Ollamaのインストールが必要になりますのでご注意ください。
RUN /app/.venv/bin/pip install Jupyter jupyterlab
JupyterLabをインストールしています。
RUN /app/.venv/bin/pip install ollama langchain-ollama langchain langsmith langchain-chroma faiss-gpu langchain-community langchain_huggingface langchain_core tiktoken tavily-python
LangChainとOllama、Tavily Search関連のパッケージをインストールしています。
LLMはOllamaのライブラリを使って動かしますので、PyTorchやTransformerは別途インストール不要です。
docker-compose.ymlでDockerコンテナの設定をします。
docker-compose.ymlのYAMLファイルを作成して開きます。
nano docker-compose.yml以下のコードをコピーして、YAMLファイルに貼り付けます。
services:
tavily:
build:
context: .
dockerfile: Dockerfile
image: tavily
runtime: nvidia
container_name: tavily
ports:
- "8888:8888"
volumes:
- .:/app/tavily
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: 1
capabilities: [gpu]
command: >
bash -c '/usr/local/bin/ollama serve & /app/.venv/bin/jupyter lab --ip="*" --port=8888 --NotebookApp.token="" --NotebookApp.password="" --no-browser --allow-root'bash -c ‘/usr/local/bin/ollama serve & /app/.venv/bin/jupyter lab –ip=”*” –port=8888 –NotebookApp.token=”” –NotebookApp.password=”” –no-browser –allow-root’
bash -c '/usr/local/bin/ollama serve
Ollama Serverを起動しています。PythonのOllamaを使用する際に、Ollama Serverを起動しておく必要がありますので、ご注意ください。
& /app/.venv/bin/jupyter lab --ip="*" --port=8888 --NotebookApp.token="" --NotebookApp.password="" --no-browser --allow-root'
JupyterLabを8888番ポートで起動しています。
Dockerfileからビルドしてコンテナを起動します。
docker compose up
Dockerの起動後にブラウザの検索窓に”localhost:8888″を入力すると、Jupyter Labをブラウザで表示できます。
localhost:8888LangChainのTavily Searchを実装

Dockerコンテナで起動したJupyter Lab上でLangChainのTavily searchを実装します。
LangChainに関する環境変数を設定します。
import os
from uuid import uuid4
unique_id = uuid4().hex[0:8]
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_PROJECT"] = f"tavily - {unique_id}"
os.environ["LANGCHAIN_ENDPOINT"] = "https://api.smith.langchain.com"
os.environ["LANGCHAIN_API_KEY"] = "***************"
os.environ["TAVILY_API_KEY"] = "***************"unique_id = uuid4().hex[0:8]
8桁のランダムな一意の識別子unique_idを生成しています。
os.environ[“LANGCHAIN_TRACING_V2”] = “true”
この設定により、LangChainのトレースが可能になります。
os.environ[“LANGCHAIN_PROJECT”] = f”tavily- {unique_id}”
angChainプロジェクトの名前を設定しています。ここでは、生成したunique_idを使用してプロジェクト名を「tavily – {unique_id}」の形式で一意にしています。
os.environ[“LANGCHAIN_ENDPOINT”] = “https://api.smith.langchain.com”
LangChainのAPIエンドポイントを指定しています。
os.environ[“LANGCHAIN_API_KEY”] = “***************”
LangChain APIを利用するためのAPIキーを設定しています。
os.environ[“TAVILY_API_KEY”] = “***************”
Tavily Search APIを利用するためのAPIキーを設定してます。
日本語LLMモデル「Llama-3-ELYZA-JP-8B-q4_k_m.gguf」をダウンロードします。
!curl -L -o Llama-3-ELYZA-JP-8B-q4_k_m.gguf "https://huggingface.co/elyza/Llama-3-ELYZA-JP-8B-GGUF/resolve/main/Llama-3-ELYZA-JP-8B-q4_k_m.gguf?download=true"Llama-3-ELYZA-JPについては、別記事で詳しく解説しています。

LLMの実行にはOllamaを使用します。
LLMのモデルがOllama使えるようにプロンプトテンプレートを指定して、モデルを作成します。
import ollama
from langchain_ollama.chat_models import ChatOllama
modelfile='''
FROM ./Llama-3-ELYZA-JP-8B-q4_k_m.gguf
TEMPLATE """{{ if .System }}<|start_header_id|>system<|end_header_id|>
{{ .System }}<|eot_id|>{{ end }}{{ if .Prompt }}<|start_header_id|>user<|end_header_id|>
{{ .Prompt }}<|eot_id|>{{ end }}<|start_header_id|>assistant<|end_header_id|>
{{ .Response }}<|eot_id|>"""
PARAMETER stop "<|start_header_id|>"
PARAMETER stop "<|end_header_id|>"
PARAMETER stop "<|eot_id|>"
PARAMETER stop "<|reserved_special_token"
'''
ollama.create(model='elyza8b', modelfile=modelfile)
llm = ChatOllama(model="elyza8b", temperature=0)FROM ./Llama-3-ELYZA-JP-8B-q4_k_m.gguf
ダウンロードしたモデルのパスが入ります。
TEMPLATE “””{{ if .System }}<|start_header_id|>system<|end_header_id|>…
モデルで使用するプロンプトテンプレートが入ります。
ollama.create(model=’elyza8b’, modelfile=modelfile)
モデルとプロンプトテンプレートを使ってOllama用のモデルを作成します。modelにはOllamaで呼び出す際に使用する名前をつけられます。
ChatOllama(model=”elyza8b”, temperature=0)
ChatOllamaをインスタンス化してLLMモデルを実行できる状態にしています。
ollama.createのエラー「invalid digest format」の解消方法

Ollamaの詳しい使い方は、別の記事で解説しています。

TavilySearchを使用したRetriever Chainの構築

TavilySearchを使用したRetriever Chainを構築していきます。
TavilySearchAPIRetrieverを使用して、Web検索の設定とRetrieverの設定をします。
from langchain_community.retrievers import TavilySearchAPIRetriever
retriever = TavilySearchAPIRetriever(
k=5,
search_depth="advanced",
include_answer=True,
include_raw_content=True,
)
retriever.invoke("キングオブコント2024のファイナリストを教えてください")TavilySearchAPIRetriever()
max_results=5:
検索結果の最大件数を5件に制限します。
search_depth="advanced":
高度な検索オプションを使用して、より深い検索を実行します。
include_answer=True:
検索結果に直接的な回答を含めるように設定しています。
include_raw_content=True:
検索結果に、元の未加工のコンテンツ(原文)を含めるように設定しています。
tool.invoke({“query”: “キングオブコント2024のファイナリストを教えて下さい。”})
「キングオブコント2024のファイナリストを教えて下さい。」というリクエストをTavily Search APIに送信して、結果を返します。
5件の検索結果が得られています。
[Document(metadata={'title': '『キングオブコント2024』コットン、ロコディ、ニッ社、や団、隣人ら決勝進出10組が決定(ENCOUNT) - Yahoo!ニュース', 'source': 'https://news.yahoo.co.jp/articles/ca13e5720f71ba0095afbf5153037a77563e2140', 'score': 0.99937123, 'images': []}, page_content='『キングオブコント2024』決勝進出10組が決定。コットン、ロコディ、ニッ社、や団、隣人らがファイナリスト。以下省略'),
Document(metadata={'title': '『キングオブコント2024』決勝進出10組決定 cacao、ダンビラムーチョ、シティホテル3号室が初進出 決戦は10月12日【コメントあり ...', 'source': 'https://news.yahoo.co.jp/articles/70aed1d9a276a60060b8897c29eb33cec3dc4085', 'score': 0.9990782, 'images': []}, page_content='『キングオブコント2024』決勝進出10組決定。cacao、ダンビラムーチョ、シティホテル3号室が初進出。以下省略'),
Document(metadata={'title': '『キングオブコント』ファイナリスト10組発表 ロングコートダディ、ラブレターズ、ニッポンの社長ら【一覧掲載】', 'source': 'https://news.goo.ne.jp/article/oricon/entertainment/oricon-2344376.html', 'score': 0.99890983, 'images': []}, page_content='『キングオブコント』ファイナリスト10組が発表され、ロングコートダディ、ラブレターズ、ニッポンの社長らが進出。以下省略'),
Document(metadata={'title': '『キングオブコント』ファイナリスト10組発表【随時更新】 | Oricon News', 'source': 'https://www.oricon.co.jp/news/2344376/full/', 'score': 0.9988531, 'images': []}, page_content='『キングオブコント2024』ファイナリスト10組が発表。ロングコートダディ、ラブレターズ、隣人らが進出。以下省略'),
Document(metadata={'title': '【会見レポート】「キングオブコント2024」cacao、シティホテル3号室、ダンビラムーチョが初の決勝(写真36枚)', 'source': 'https://natalie.mu/owarai/news/590531', 'score': 0.9986276, 'images': []}, page_content='「キングオブコント2024」cacao、シティホテル3号室、ダンビラムーチョが初の決勝進出。以下省略')
]
コンテキストに基づいて質問に答えるためのプロンプトテンプレートを定義しています。
from langchain_core.prompts import ChatPromptTemplate
prompt = ChatPromptTemplate.from_messages([
("system", "提供されたコンテキストのみに基づいて質問に答えてください。"),
("user", "Context: {context}\n\n Question: {question}")
])ChatPromptTemplate.from_messages()
("system", "提供されたコンテキストのみに基づいて質問に答えてください。"):
systemロールとして、このメッセージを定義しています。
("user", "Context: {context}\n\n Question: {question}"):
userロールとして、このメッセージを定義しています。{context}と{question}というプレースホルダーは、実際にプロンプトが使用される際に具体的な内容で置き換えられます。
ユーザーの質問を元にコンテキストを取得し、プロンプトを通じてLLMに質問を投げ、結果を文字列として出力するChainを構築しています。
from langchain_core.runnables import RunnablePassthrough
from langchain_core.output_parsers import StrOutputParser
chain = (
RunnablePassthrough.assign(context=(lambda x: x["question"]) | retriever)
| prompt
| llm
| StrOutputParser()
)chain = ()
RunnablePassthrough.assign(context=(lambda x: x["question"]) | retriever):
RunnablePassthroughは、そのままデータを次に渡すための「パススルー」機能です。assignメソッドを使って、contextという名前のキーに特定のデータを割り当てます。(lambda x: x["question"])は、入力データから"question"というキーに対応する値を取り出します。lambdaによって取得したquestionの値を使ってretrieverで検索を行います。
| prompt:
- 先ほどのステップから渡されたデータを元に、モデルに渡すためのプロンプトを生成します。
| llm:
- 生成されたプロンプトを言語モデル(LLM)に入力し、応答を得ます。
| StrOutputParser():
モデルからの応答を文字列として整形し、最終的な結果として返します。
Tavily searchに『キングオブコント』について聞いてみる

RAGチャットボットを使って、『弱虫ペダル』について質問してみます。
result = chain.invoke({"question": "キングオブコント2024のファイナリストを教えてください"})
print(result)キングオブコント2024のファイナリストを教えてください
1. cacao
2. ファイヤーサンダー
3. ロングコートダディ
4. 隣人
5. ラブレターズ
6. や団
7. コットン
8. ニッポンの社長
9. シティホテル3号室
10. ダンビラムーチョ
result = chain.invoke({"question": "キングオブコント2023の優勝者は誰ですか?"})
print(result)キングオブコント2023の優勝者は誰ですか?
キングオブコント2023の優勝者は、サルゴリラの児玉と赤羽です。
result = chain.invoke({"question": "キングオブコントの司会者は誰ですか?"})
print(result)キングオブコントの司会者は誰ですか?
キングオブコント2024の司会進行は小籔千豊が務めた。
生成AI・LLMのコストでお困りなら
GPUのスペック不足で生成AIの開発が思うように進まないことはありませんか?
そんなときには、高性能なGPUをリーズナブルな価格で使えるGPUクラウドサービスがおすすめです!

GPUSOROBANは、生成AI・LLM向けの高速GPUを業界最安級の料金で使用することができます。
インターネット環境さえあれば、クラウド環境のGPUサーバーをすぐに利用可能です。
大規模な設備投資の必要がなく、煩雑なサーバー管理からも解放されます。







