
RAGは外部から取得した情報をもとに、LLMの知識を強化して生成するしくみです。
RAGを使うとLLMが学習していない新しい情報を答えられるようになります。
この記事では、LangChainを使ってRAGを構築する方法を紹介しています。
ざっくり言うと
- LangChainの概要としくみを紹介
- LangChainを使ってRAGを構築する
- 日本語のローカルLLM「Llama-3-ELYZA-JP-8B」を使用

RAG(検索拡張生成)とは

RAG(検索拡張生成)は、データベースの「検索する機能」とLLMの「生成する機能」を組み合わせて実現します。
データベースから質問に関連する情報を取得して、その情報をもとにLLMが回答を生成します。
LLMの知識は学習データに限定されていますが、RAGを使えば新しい情報を参照して生成できるようになります。

LangChainでRAGを簡単に構築できる!

LangChainは、RAGを簡単に構築できるフレームワークです。
RAGは様々な要素で構成されますが、いずれもLangChainおよび統合されたライブラリを使用して実装ができます。
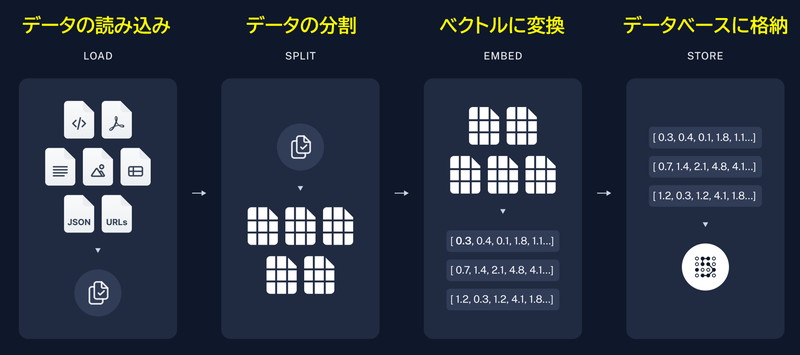
LangChainでは次のようなRAGの機能を提供しています。
- 用意したデータを読み込む
- データをチャンクに分割する
- データをベクトルに変換する
- データベースに格納する
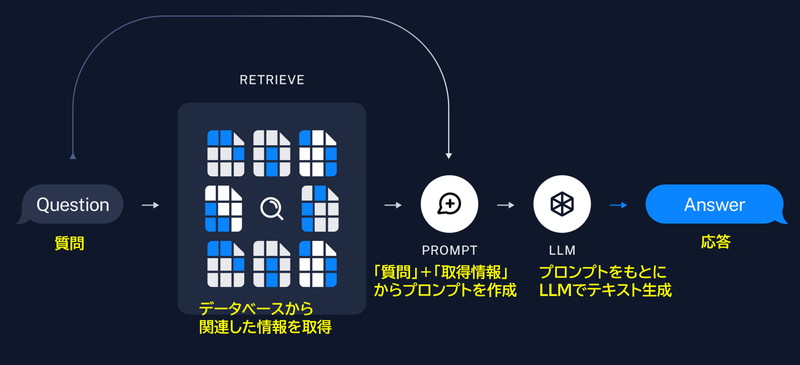
- ユーザーの質問をもとにデータベースから関連情報を取得する
- 「質問」と「取得情報」をもとにプロンプトを作成する
- プロンプトをもとにLLMからテキストを生成する
LangChain RAGの実行環境

この記事で用意した実行環境は以下のとおりです。
- GPU:NVIDIA A100 80GB
- GPUメモリ(VRAM):80GB
- OS :Ubuntu 22.04
- Docker
Dockerで環境構築
Dockerを使用してLangChainの環境構築をします
Dockerの使い方は以下の記事をご覧ください。

Ubuntuのコマンドラインで、Dockerfileを作成します。
mkdir langchain_rag
cd langchain_rag
nano DockerfileDockerfileに以下の記述を貼り付けます。
# ベースイメージ(CUDA)の指定
FROM nvidia/cuda:12.1.0-cudnn8-devel-ubuntu22.04
# 必要なパッケージをインストール
RUN apt-get update && apt-get install -y python3-pip python3-venv git nano curl
RUN curl -fsSL https://ollama.com/install.sh | sh
# 作業ディレクトリを設定
WORKDIR /app
# アプリケーションコードをコピー
COPY . /app
# Python仮想環境の作成
RUN python3 -m venv /app/.venv
# 仮想環境をアクティベートするコマンドを.bashrcに追加
RUN echo "source /app/.venv/bin/activate" >> /root/.bashrc
# JupyterLabのインストール
RUN /app/.venv/bin/pip install Jupyter jupyterlab
# LangChain関連のインストール
RUN /app/.venv/bin/pip install ollama=0.4.4 langchain-ollama langchain langsmith langchain-chroma faiss-gpu langchain-community langchain_huggingface langchain_core tiktoken
# コンテナの起動時にbashを実行
CMD ["/bin/bash"]FROM nvidia/cuda:12.1.0-cudnn8-devel-ubuntu22.04
CUDA12.1のベースイメージを指定しています。
RUN apt-get update && apt-get install -y python3-pip python3-venv git nano curl
必要なパッケージをインストールしています。
RUN curl -fsSL https://ollama.com/install.sh | sh
Linux版のOllamaをインストールしています。PythonでOllamaを動かす際にもLinux版Ollamaのインストールが必要になりますのでご注意ください。
RUN /app/.venv/bin/pip install Jupyter jupyterlab
JupyterLabをインストールしています。
RUN /app/.venv/bin/pip install ollama=0.4.4 langchain-ollama langchain langsmith langchain-chroma faiss-gpu langchain-community langchain_huggingface langchain_core tiktoken
LangChainとOllama関連のパッケージをインストールしています。
LLMはOllamaのライブラリを使って動かしますので、PyTorchやTransformerは別途インストール不要です。
docker-compose.ymlでDockerコンテナの設定をします。
docker-compose.ymlのYAMLファイルを作成して開きます。
nano docker-compose.yml以下のコードをコピーして、YAMLファイルに貼り付けます。
services:
langchain_rag:
build:
context: .
dockerfile: Dockerfile
image: langchain_rag
runtime: nvidia
container_name: langchain_rag
ports:
- "8888:8888"
volumes:
- .:/app/langchain_rag
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: 1
capabilities: [gpu]
command: >
bash -c '/usr/local/bin/ollama serve & /app/.venv/bin/jupyter lab --ip="*" --port=8888 --NotebookApp.token="" --NotebookApp.password="" --no-browser --allow-root'bash -c ‘/usr/local/bin/ollama serve & /app/.venv/bin/jupyter lab –ip=”*” –port=8888 –NotebookApp.token=”” –NotebookApp.password=”” –no-browser –allow-root’
bash -c '/usr/local/bin/ollama serve
Ollama Serverを起動しています。PythonのOllamaを使用する際に、Ollama Serverを起動しておく必要がありますので、ご注意ください。
& /app/.venv/bin/jupyter lab --ip="*" --port=8888 --NotebookApp.token="" --NotebookApp.password="" --no-browser --allow-root'
JupyterLabを8888番ポートで起動しています。
Dockerfileからビルドしてコンテナを起動します。
docker compose up
Dockerの起動後にブラウザの検索窓に”localhost:8888″を入力すると、Jupyter Labをブラウザで表示できます。
localhost:8888LangChain RAGの実装

Dockerコンテナで起動したJupyter Lab上でLangChainを使ったRAGの実装をします。
LangChainに関する環境変数を設定します。
import os
from uuid import uuid4
unique_id = uuid4().hex[0:8]
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_PROJECT"] = f"langchainrag - {unique_id}"
os.environ["LANGCHAIN_ENDPOINT"] = "https://api.smith.langchain.com"
os.environ["LANGCHAIN_API_KEY"] = "***************"unique_id = uuid4().hex[0:8]
8桁のランダムな一意の識別子unique_idを生成しています。
os.environ[“LANGCHAIN_TRACING_V2”] = “true”
この設定により、LangChainのトレースが可能になります。
os.environ[“LANGCHAIN_PROJECT”] = f”langchainrag – {unique_id}”
LangChainプロジェクトの名前を設定しています。ここでは、生成したunique_idを使用してプロジェクト名を「langchainrag – {unique_id}」の形式で一意にしています。
os.environ[“LANGCHAIN_ENDPOINT”] = “https://api.smith.langchain.com”
LangChainのAPIエンドポイントを指定しています。
os.environ[“LANGCHAIN_API_KEY”] = “***************”
LangChain APIを利用するためのAPIキーを設定しています。
日本語LLMモデル「tokyotech-llm-Llama-3.1-Swallow-8B-Instruct-v0.1-Q4_K_M.gguf」をダウンロードします。
!curl -L -o tokyotech-llm-Llama-3.1-Swallow-8B-Instruct-v0.1-Q4_K_M.gguf "https://huggingface.co/mmnga/tokyotech-llm-Llama-3.1-Swallow-8B-Instruct-v0.1-gguf/resolve/main/tokyotech-llm-Llama-3.1-Swallow-8B-Instruct-v0.1-Q4_K_M.gguf?download=true"Llama-3.1-Swallow-8B-Instructについては、別記事で詳しく解説しています。

LLMの実行にはOllamaを使用します。
LLMのモデルがOllama使えるようにプロンプトテンプレートを指定して、モデルを作成します。
import ollama
from langchain_ollama.chat_models import ChatOllama
modelfile='''
FROM ./tokyotech-llm-Llama-3.1-Swallow-8B-Instruct-v0.1-Q4_K_M.gguf
TEMPLATE """{{ if .System }}<|start_header_id|>system<|end_header_id|>
{{ .System }}<|eot_id|>{{ end }}{{ if .Prompt }}<|start_header_id|>user<|end_header_id|>
{{ .Prompt }}<|eot_id|>{{ end }}<|start_header_id|>assistant<|end_header_id|>
{{ .Response }}<|eot_id|>"""
PARAMETER stop "<|start_header_id|>"
PARAMETER stop "<|end_header_id|>"
PARAMETER stop "<|eot_id|>"
PARAMETER stop "<|reserved_special_token"
'''
ollama.create(model='swallow3_1', modelfile=modelfile)
llm = ChatOllama(model='swallow3_1', temperature=0)
llm.invoke(("human","呪術廻戦を知っていますか?")).contentFROM ./tokyotech-llm-Llama-3.1-Swallow-8B-Instruct-v0.1-Q4_K_M.gguf
ダウンロードしたモデルのパスが入ります。
TEMPLATE “””{{ if .System }}<|start_header_id|>system<|end_header_id|>…
モデルで使用するプロンプトテンプレートが入ります。
ollama.create(model=’swallow3_1′, modelfile=modelfile)
モデルとプロンプトテンプレートを使ってOllama用のモデルを作成します。modelにはOllamaで呼び出す際に使用する名前をつけられます。
ChatOllama(model=’swallow3_1′, temperature=0)
ChatOllamaをインスタンス化してLLMモデルを実行できる状態にしています。
確認のため、LLMからテキストを生成しています。
'「呪術廻戦」は、芥見下々による日本の漫画作品です。2020年から週刊少年ジャンプで連載が開始されました。\n\n物語は、主人公の虎杖悠仁が、呪術師である乙骨憂太と出会い、呪術界に足を踏み入れることから始まります。呪術師とは、呪いを祓うことができる特殊な能力者で、呪霊と呼ばれる悪霊や、他人を呪って生存する「呪詛師」などとの戦いが描かれます。\n\n作中では、呪術師の世界の暗部や、人間の負の感情が生み出す呪いの恐ろしさが描写され、主人公とその仲間たちが、呪霊や呪詛師に立ち向かいながら成長していくストーリーです。\n\n「呪術廻戦」は、2020年からTVアニメ化もされており、人気を博しています。'ollama.createのエラー「invalid digest format」の解消方法

Ollamaの詳しい使い方は、別の記事で解説しています。

Wikipediaからテキストデータを抽出して、読み込みます。
Wikipediaの『呪術廻戦』のページからテキストを抽出しています。
from langchain_community.document_loaders import WebBaseLoader
urls = [
"https://ja.wikipedia.org/wiki/%E5%91%AA%E8%A1%93%E5%BB%BB%E6%88%A6",
]
docs = [WebBaseLoader(url).load() for url in urls]
docs_list = [item for sublist in docs for item in sublist]WebBaseLoader(url).load()
指定したWebページのHTMLコンテンツを取得し、HTMLコンテンツを解析し、使いやすいデータ構造に変換し、そのデータを読み込みます。
読み込んだデータをチャンクに分割します。
データベースの検索精度の向上や効率的な処理のためにチャンク分割が必要になります。
from langchain.text_splitter import CharacterTextSplitter
text_splitter = CharacterTextSplitter.from_tiktoken_encoder(
separator = "\n",
chunk_size= 1000,
chunk_overlap=100,
)
doc_splits = text_splitter.split_documents(docs_list)
doc_splits[12:15]CharacterTextSplitter.from_tiktoken_encoder…
テキストを指定された条件でチャンクに分割しています。
separator = “\n”
チャンクを分割する際の区切り文字を「\n」として指定します。
chunk_size= 1000
各チャンクが1000文字を超えないように分割されます。
chunk_overlap=100
各チャンクが100文字分重複するように設定しています。
確認のため、分割したチャンクを3つ表示しています。
[Document(metadata={'source': 'https://ja.wikipedia.org/wiki/%E5%91%AA%E8%A1%93%E5%BB%BB%E6%88%A6', 'title': '呪術廻戦 - Wikipedia', 'language': 'ja'}, page_content='玉折(ぎょくせつ)編(9巻76話 - 79話)\n2007年、呪術高専3年生の五条と夏油は特級呪術師になっていた。五条は「最強」として、その実力をさらに伸ばし続けていた。一方夏油は、星漿体護衛の一件から、それまで掲げていた「呪術は非術師を守るためにある」という信念が揺らぎ始めていた。そんな中、夏油は8月に高専に訪れた特級呪術師の九十九由基と言葉を交わし、その結果「非術師を皆殺しにすれば良い」という考えが生まれ始める。\nその後も夏油は後輩・灰原雄の死、さらには9月に任務で訪れた田舎で、住人達に虐待されていた呪術師の少女の惨状を目の当たりにする。遂に夏油は、「猿(非術師)は嫌い」という本音を選び、村の非術師達を虐殺して呪詛師に堕ちた。事件後、夏油は五条に「非術師を抹殺し、呪術師の世界を創る」と宣言し、呪術高専から離反する。\nその後、夏油は盤星教を乗っ取り、術師の仲間と共にその活動を始める。一方五条は自身を悔い改め、強い仲間を作ることを決意する。こうして2人の親友は、互いに異なる道を歩む。\n宵祭り(よいまつり)編(9巻79話 - 10巻82話)\n過去編が終わり、舞台は現在に戻る。\n2018年10月19日、呪術高専京都校の2年生・与幸吉が、夏油達の内通者をしていたことが判明する。与は先天的な身体の欠損・不自由の持ち主であり、夏油達に協力する際、「対価として真人の呪術で肉体を治す」という契約を結んでいた。'),
Document(metadata={'source': 'https://ja.wikipedia.org/wiki/%E5%91%AA%E8%A1%93%E5%BB%BB%E6%88%A6', 'title': '呪術廻戦 - Wikipedia', 'language': 'ja'}, page_content='与は同日、夏油達に内通者を辞退することを告げ、真人に肉体を治させる。その直後に自作の巨大ロボットの装甲傀儡を起動し真人と交戦するが、最終的に敗北して死亡した。\n渋谷事変(しぶやじへん)編 (10巻83話 - 16巻136話)\n2018年10月31日、渋谷駅周辺に特殊な帳が張られ、一般人が閉じ込められる。\nこれに対し、高専は五条悟単独での渋谷平定を決定し、同時に4人の一級呪術師の七海、冥冥、禪院直毘人、日下部篤也が、それぞれ昇級査定中の伏黒、釘崎、真希、パンダ、虎杖と共に渋谷に派遣される。\n渋谷駅の地下5階に潜入した五条は、漏瑚ら呪霊たちと対峙する。両者は一般人の群衆の中で戦いを始め、最終的に五条は生きた結界・獄門疆によって封印される。また、今まで呪霊と暗躍していた人物は、夏油傑の肉体を奪った何者か(以下、「偽夏油」)であることが判明した。五条の抵抗によって獄門疆を動かせない中、偽夏油一派の中で虎杖の扱いについて意見が分かれ、虎杖をめぐる競争を始める。\nそんな中、生前の与が残した傀儡が起動する。傀儡は虎杖達に五条の封印と偽夏油達の存在を伝え、虎杖達は五条奪還に向けて渋谷駅の地下5階を目指す。壊相と血塗の兄・脹相や真人などとの戦いから生還した虎杖であったが、偽夏油の尻尾を掴むことはできず、獄門疆を持った偽夏油は呪術界に目まぐるしい変革が起こることを予言しつつ去った。\n渋谷事変 その後(16巻137話 - 18巻159話)'),
Document(metadata={'source': 'https://ja.wikipedia.org/wiki/%E5%91%AA%E8%A1%93%E5%BB%BB%E6%88%A6', 'title': '呪術廻戦 - Wikipedia', 'language': 'ja'}, page_content='渋谷事変 その後(16巻137話 - 18巻159話)\n葦を啣む編以前(16巻137話 - 17巻147話)\n渋谷事変の混乱に乗じて東京都立呪術高専の学長である夜蛾正道が濡れ衣をかぶせられる形で処刑され、虎杖の死刑の猶予も取り消しとなる。虎杖の死刑執行人に乙骨が指名されたが、乙骨はこの命に背き虎杖を殺害しなかった。その後伏黒と合流した際、虎杖は死滅回游の開始を知る。\n偽夏油への敵愾心から呪術師と行動を共にすることに決めた脹相の協力もあり天元のもとへ至った虎杖らは、夏油の肉体を乗っ取った呪詛師・羂索と死滅回游の顛末を天元から聞かされ、また死滅回游の泳者(プレイヤー)・来栖華の術式を用いることで獄門疆を解除できる可能性があることを知る。\n葦を啣む(あしをふくむ)編(17巻148話 - 152話)\n禪院家に呪具を獲得すべく赴いた真希は、妹の真依共々父・扇に攻撃される。一時は呪霊が跋扈する部屋に投げ込まれ敗死を覚悟した真希だったが、真依の全身全霊の構築術式によって生成された呪具の刀を得て力を取り戻し、扇を含めた禪院家のほぼ全員を殺害し積年の恨みを晴らした。\n葦を啣む編以後(18巻153話 - 159話)')]テキストをベクトル表現に変換する埋め込みモデルを読み込みます。
日本語性能が高く、無料で使える埋め込みモデル「intfloat/multilingual-e5-large」を指定しています。
from langchain_huggingface import HuggingFaceEmbeddings
embedding = HuggingFaceEmbeddings(model_name="intfloat/multilingual-e5-large")Retrieverとは、クエリをもとにベクトルデータベースから関連情報を検索・取得する機能です。
Retrieverの実装には、GPUを活用した高速ベクトル検索が可能な「FAISS」ライブラリを使用しています。
from langchain.vectorstores import FAISS
vectorstore = FAISS.from_documents(doc_splits, embedding)
retriever = vectorstore.as_retriever(search_type="similarity", search_kwargs={"k": 3})
question = "領域展開とは"
retriever.invoke(question)FAISS.from_documents(splits, embedding)
ベクトル検索用のインデックスを作成しています。インデックスはDBのテーブルのような概念です。
vector.as_retriever()
インデックスからRetriverを作成しています。
search_type=”similarity”
質問の類似度にもとづいて検索する指定です。
search_kwargs={“k”: 3}
検索結果として上位3件の類似ドキュメントを返す設定です。
retriever.invoke()
クエリをRetrieverに渡し、類似したドキュメントを検索します。
「領域展開とは」というクエリに対して、Retrieverが返した結果
[Document(metadata={'source': 'https://ja.wikipedia.org/wiki/%E5%91%AA%E8%A1%93%E5%BB%BB%E6%88%A6', 'title': '呪術廻戦 - Wikipedia', 'language': 'ja'}, page_content='また、呪力や言霊を他者に託すタイプの帳は嘱託式と呼ばれており、呪符が巻かれた杭を基として用いる。基に呪力を込めて発動するため、基を壊されると帳が解除される。\n領域展開(りょういきてんかい)\n人間や呪霊が持つ心の中「生得領域」を、術式を付与して呪力で外部に構築した結界。「呪術の極致」と呼ばれ、これを習得している者は非常に限られている。「閉じこめる」ことに特化した結界で、「領域」とも呼ばれる。領域は内からの耐性を上げているため、逆に外からの力に弱く、侵入することが容易い。\n領域展開は「環境要因による術師のステータス上昇」や「結界に付与した必殺の術式を必中必殺に昇華」「引き入れた相手の術式の中和」といった大きなメリットがある。中和効果によって、領域内では「無下限呪術」の使い手・五条悟にも攻撃が当たる。ただし、領域を広げる際は呪力の消費が膨大で、領域を延々と展開するのは不可能。また、使用後は術式が焼き切れて一時的に使用困難になる欠点(使用できないわけではない)もある。\n外観や効果は生得術式によって異なり、術式効果によっては、引き入れた時点で使い手の勝利がほぼ確定する必殺の領域もある。\n特に領域の結界は、体内条件、体外条件、体積、構築速度など各々の術師が結界を成立させられる要件が決まっており、領域展開の都度それらは変更出来るようなものではない。'),
Document(metadata={'source': 'https://ja.wikipedia.org/wiki/%E5%91%AA%E8%A1%93%E5%BB%BB%E6%88%A6', 'title': '呪術廻戦 - Wikipedia', 'language': 'ja'}, page_content='未熟な術師などが構築する術式が付与されていない領域もあり、それらは「未完成の領域」と呼ばれる。また、結界を閉じずに領域を展開する技術もあり、これはキャンバスを用いずに空に絵を描く神業とされ、使い手は宿儺と羂索しかいない。\n領域への対策としては、相手の呪術を呪術で受けるか、最も有効な手段は対抗する領域の展開である。同時に領域が展開された時はより洗練された術がその場を制する(相性や呪力量も関係する)。領域同士がぶつかった場合、結界を押し合い、互いの必中効果を打ち消し合う。また、大抵は無理だが、領域外に逃げるという方法もある。\nかつてはもっとスタンダードな技術だったが、術式を必中させるだけでなく、必殺させることにも拘った結果難易度が上昇して使い手が減少した。\n領域展延(りょういきてんえん)\n領域の内、自分だけを包む液体のような領域をさす。簡易領域をさらに練り上げた技術。展開した領域にあえて術式を付与しない事で空きを作り、触れた相手の術式をそこに流し込ませて中和することができる。相手の術式だけでなく領域展開の必中効果も中和できることや、自由に動けるというメリットがある一方、自身の領域に空きを作るために生得術式との併用はできないというデメリットがある。また、出力の高い術式効果は中和しきれないことがある。\nシン・陰流(シン・かげりゅう)「簡易領域(かんいりょういき)」'),以下省略プロンプトに使用する構文(プロンプトテンプレート)を設定しています。
from langchain_core.prompts import PromptTemplate
prompt = PromptTemplate(
template="""<|begin_of_text|><|start_header_id|>system<|end_header_id|>
与えられた参考情報をもとに質問に回答してください。
<|eot_id|><|start_header_id|>user<|end_header_id|>
質問: {question}
参考情報: {context}
回答: <|eot_id|><|start_header_id|>assistant<|end_header_id|>""",
input_variables=["question", "context"],
)PromptTemplate()
プロンプトのテンプレートを定義するために使用されるクラスです。テンプレート内で、指定された変数に動的に値を埋め込み、LLMに指示を与えるプロンプトを生成します。
template には、LLMに対してどのような指示を与えるかを記述します。
<|begin_of_text|><|start_header_id|>system<|end_header_id|> ...<|eot_id|>には、システムプロンプトが入ります。
<|start_header_id|>user<|end_header_id|>...<|eot_id|>には、ユーザーの質問が入ります。
<|start_header_id|>assistant<|end_header_id|>...には、LLMの回答が入ります。
input_variables では、テンプレート内で動的に置き換えられる変数名をリストで指定します。
この場合、questionと contextの2つの変数が指定されています。
ユーザーからの質問とRetrieverからの取得情報をもとにプロンプトを作成し、モデルに渡すRAGチェーンを構築します。
from langchain_core.runnables import RunnablePassthrough
from langchain_core.output_parsers import StrOutputParser
rag_chain = {"context": retriever, "question": RunnablePassthrough()} | prompt | llm | StrOutputParser(){“context”: retriever, “question”: RunnablePassthrough()} | prompt | llm | StrOutputParser()
プロンプトの作成から、LLMによる応答の生成、文字列形式の出力までを一連の処理として組み合わせたChainを構築しています。
"context": retrieverユーザーの質問から関連する情報をRetrieverで検索・取得し、その情報を”context”としてプロンプトに渡します。
"question": RunnablePassthrough()ユーザーの質問を変換せずにそのまま”question”としてプロンプトに渡します。
| prompt
定義したテンプレートに”context”と”question”を挿入してプロンプトを作成し、LLMに渡します。
| llm
渡されたプロンプトをもとにLLMがテキストを生成します。
| StrOutputParser()
出力形式を文字列として扱うパーサーです。
LangChain RAGに『呪術廻戦』について聞いてみる

Langchain RAGを使って、モデルに学習されていない『呪術廻戦』について質問してみます。
RAGに質問する(1)
「五条悟の術式を教えて下さい」と質問してみます。
response = rag_chain.invoke("五条悟の術式を教えて下さい。")
print(response)五条悟の術式を教えて下さい。
五条悟の術式は以下の通りです。
1. 無下限呪術(むかげんじゅじゅつ):自身の周囲に術式によって現実化させた無限を作ることで攻撃を防いだり、応用して瞬間移動や空中浮遊なども可能にする。
2. 術式順転「蒼(あお)」:無下限呪術の本来の術式を強化することで収束を現実に発生させる。物体を吸い寄せる力で周囲を更地に変えることも可能だが、大きな反応を自分の近くで発生させられない弱点がある。
3. 術式反転「赫(あか)」:蒼とは逆に無限を発散させることで対象を吹き飛ばす。反転の威力は順転の二倍なので、街中などでは使用が制限される。
4. 虚式「茈(むらさき)」:五条家でも一部の人間しか知らない術。順転と反転の力を衝突させることで生成された仮想の質量を押し出す複合術式。その威力は姉妹校交流会の会場を破壊するほど。
5. 落花の情:御三家に伝わる対領域術の技。
RAGに質問する(2)
「五条悟が一人で戦うのはなぜですか」と質問してみます。
response = rag_chain.invoke("五条悟が一人で戦うのはなぜですか ")
print(response)五条悟が一人で戦うのはなぜですか
五条悟が一人で戦うのは、常に周りの人間を自身の攻撃に巻き込まないように気を配っており、必要時に巻き込む際もその被害を最小限に抑えようと心がけているからです。
RAGに質問する(3)
「ナナミンについて教えて下さい」と質問してみます。
response = rag_chain.invoke("ナナミンについて教えて下さい")
print(response)ナナミンについて教えて下さい
ナナミンは、呪術廻戦の登場人物です。薄茶色のスーツを着た、茶髪で七三分けの男性で、ツル部分の無いゴーグルのような眼鏡をしています。常に真顔で、あまり表情を崩さない冷静沈着な人物ですが、内心では情に熱く、認めた相手には敬意を示し、仲間を殺した敵には激怒します。自らの立場への責任感が強く、困難と認めた問題に対しては本気で挑みます。好物はパンで、特にカスクートを気に入っています。
RAGに質問する(4)
「リカは式神ですか?」と質問してみます。
response = rag_chain.invoke("リカは式神ですか?")
print(response)リカは式神ですか?
リカは式神のような存在で、外付けの術式及び呪力の備蓄です。乙骨が指輪を通して接続すると、5分間の制限時間内で完全顕現が可能となり、その間には乙骨への呪力供給や乙骨の術式の使用もできます。また、体内には複数の呪具が収められています。
生成AI・LLMのコストでお困りなら
GPUのスペック不足で生成AIの開発が思うように進まないことはありませんか?
そんなときには、高性能なGPUをリーズナブルな価格で使えるGPUクラウドサービスがおすすめです!

GPUSOROBANは、高性能GPU「NVIDIA H200」を業界最安級の料金で使用することができます。
NVIDIA H200は、生成AI・LLMの計算にかかる時間を大幅に短縮することが可能です。
クラウドで使えるため、大規模な設備投資の必要がなく、煩雑なサーバー管理からも解放されます。







