
Llama 3.1 Swallowは、MetaのLlama 3.1をベースに、東工大・産総研が日本語能力を強化したLLMです。
オープンな日本語LLMの中で、日本語の言語理解・生成タスクにおいてトップクラスの性能があります。
この記事では、Llama 3.1 Swallowの性能、商用利用、使い方について紹介します。
ざっくり言うと
- Llama 3.1をベースに東工大・産総研が日本語能力を強化したLLM
- オープンな日本語LLMの中で、トップクラスの性能
- Llama 3.1の性能、ライセンス、使い方まで解説

Llama 3.1 Swallowとは

Llama 3.1 Swallowは、MetaのLlama 3.1をベースに日本語能力を強化したLLMです。
東工大・産総研の研究チームによって開発され、オープンな日本語LLMの中で、トップクラスの性能があります。
このモデルはMeta Llama 3.1のライセンスに基づき、無料で利用でき商用利用が可能です。
Llama 3.1に関する記事は別の記事で解説してます。


Llama 3.1 Swallowのモデル

Llama 3.1 Swallowのモデルには複数の種類があり、「パラメータサイズ」と「事前学習/指示学習」で分けられます。
モデルはHuggingFaceで公開されており、無料でダウンロードできます。
| モデルID | パラメータサイズ | 事前学習/指示学習 | 公開 |
|---|---|---|---|
| tokyotech-llm/Llama-3.1-Swallow-8B-v0.1 | 80億パラメータ | 事前学習モデル | HuggingFace |
| tokyotech-llm/Llama-3.1-Swallow-8B-Instruct-v0.1 | 80億パラメータ | 指示学習モデル | HuggingFace |
| tokyotech-llm/Llama-3.1-Swallow-70B-v0.1 | 700億パラメータ | 事前学習モデル | HuggingFace |
| tokyotech-llm/Llama-3.1-Swallow-70B-Instruct-v0.1 | 700億パラメータ | 指示学習モデル | HuggingFace |
事前学習モデル
基礎的なデータが学習されたモデルです。基礎的な知識はありますが、人間の指示に応じた回答ができません。
指示学習モデル
事前学習モデルを特定のタスクや指示にもとづいて調整したモデルです。ChatGPTのように人間の指示に応じた回答が可能です。
Llama 3.1 Swallowの性能

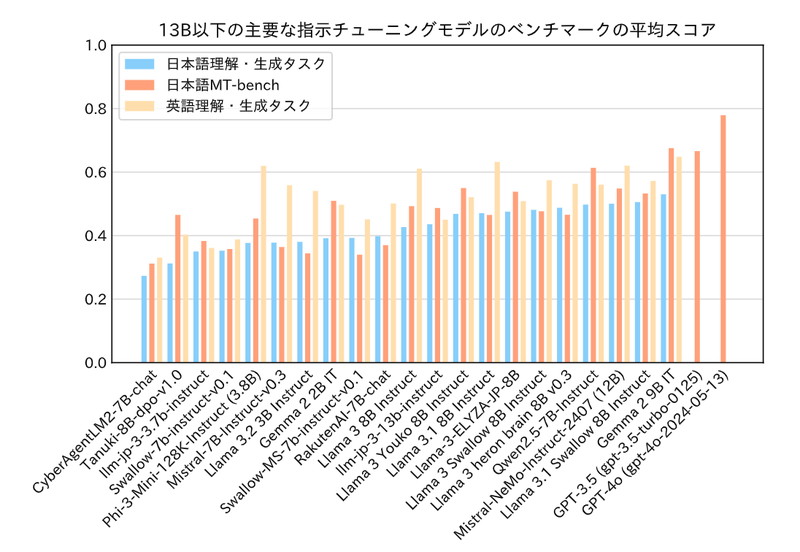
Llama 3.1 Swallow 8Bのベンチマーク
パラメータ数が130億以下のモデルを対象に、日本語理解・生成タスク、日本語MT-bench、英語理解・生成タスクのベンチマークを行い、Llama 3.1 Swallow 8Bは、オープンな8B以下のモデルの中で最も高いスコアを記録しています。
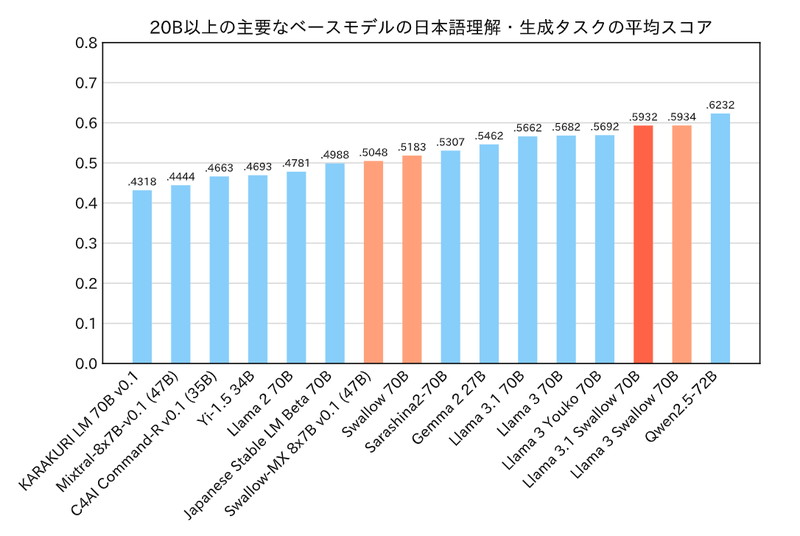
Llama 3.1 Swallow 70Bのベンチマーク
パラメータ数が200億以上のモデルを対象に、日本語理解・生成タスク、日本語MT-bench、英語理解・生成タスクのベンチマークを行った結果、Llama 3.1 Swallow 70B Instructは、MetaのLlama 3.1 70B Instructにわずかに劣るスコアとなりました。
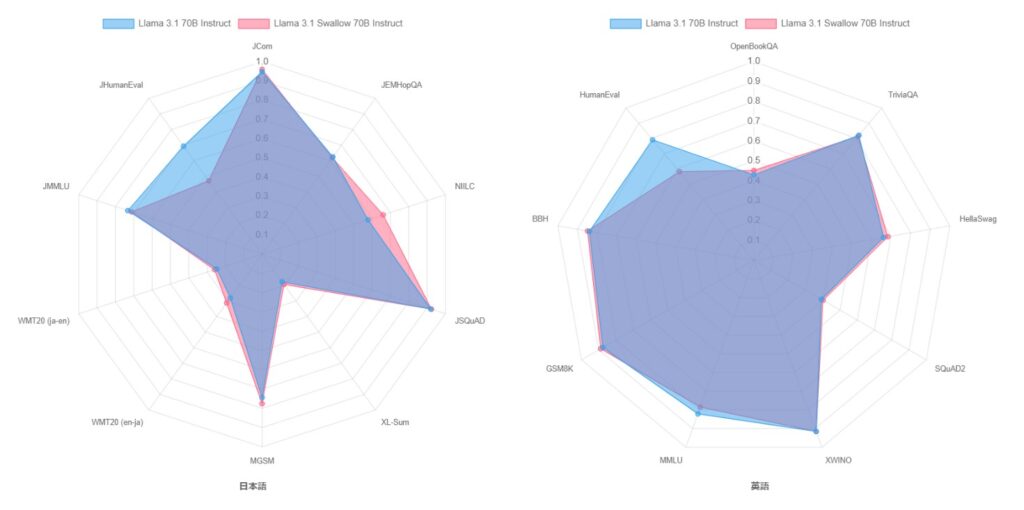
内訳を確認すると、Llama 3.1 Swallow 70B Instructはコード生成タスク(HumanEvalとJHumanEval)では劣後する一方で、日本語の質問応答タスク(NIILC)では若干優れる結果が得られています。
Llama 3.1 Swallowの商用利用・ライセンス

Llama 3.1 Swallowは、「META LLAMA 3.1 COMMUNITY LICENSE」に基づいて、無料で使用でき商用利用も可能です。
商用利用:ソフトウェアやコードを商用利用することが許可されています。
改変:ソフトウェアやコードを自由に修正したり改変したりすることができます。
配布:修正したり変更したりしたソフトウェアを自由に配布することができます。
著作権表示:再配布時に、著作権の表示や契約書コピーの提供などが必要になります。
特許利用:特許利用に関する明示的な規定はありません。
詳細は「META LLAMA 3.1 COMMUNITY LICENSE」のページをご確認ください。
Llama 3.1 Swallowの使い方

ここからLlama 3.1 Swallowの使い方ついて解説していきます。
実行環境
この記事で用意した実行環境は以下のとおりです。
- GPU:NVIDIA A100 80GB
- GPUメモリ(VRAM):80GB
- OS :Ubuntu 22.04
- Docker
Dockerで環境構築
Dockerを使用してLlama 3.1 Swallowの環境構築をします
Dockerの使い方は以下の記事をご覧ください。

コンテナにインストールするパッケージは以下のとおりです。
CUDA、PyTorch、Transformersはバージョン依存関係によるエラーが起きやすいので、動作検証済のバージョン指定してインストールしています。
- CUDA:12.1
- Python:3.10
- PyTorch:2.2.2
- transformers:4.44.0
- accelerate
- bitsandbytes
Ubuntuのコマンドラインで、Dockerfileを作成します。
mkdir swallow3_1
cd swallow3_1
nano DockerfileDockerfileに以下の記述を貼り付けます。
# ベースイメージ(CUDA)の指定
FROM nvidia/cuda:12.1.0-cudnn8-devel-ubuntu22.04
# 必要なパッケージをインストール
RUN apt-get update && apt-get install -y python3-pip python3-venv git nano
# 作業ディレクトリを設定
WORKDIR /app
# アプリケーションコードをコピー
COPY . /app
# Python仮想環境の作成
RUN python3 -m venv /app/.venv
# 仮想環境をアクティベートするコマンドを.bashrcに追加
RUN echo "source /app/.venv/bin/activate" >> /root/.bashrc
# JupyterLabのインストール
RUN /app/.venv/bin/pip install Jupyter jupyterlab
# PyTorchのインストール
RUN /app/.venv/bin/pip install torch==2.2.2 torchvision==0.17.2 torchaudio==2.2.2 --index-url https://download.pytorch.org/whl/cu121
# Transformer関連のインストール
RUN /app/.venv/bin/pip install transformers==4.44.0 accelerate bitsandbytes
# コンテナの起動時にbashを実行
CMD ["/bin/bash"]docker-compose.ymlでDockerコンテナの設定をします。
docker-compose.ymlのYAMLファイルを作成して開きます。
nano docker-compose.yml以下のコードをコピーして、YAMLファイルに貼り付けます。
services:
swallow3_1:
build:
context: .
dockerfile: Dockerfile
image: swallow3_1
runtime: nvidia
container_name: swallow3_1
ports:
- "8888:8888"
volumes:
- .:/app/swallow3_1
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: 1
capabilities: [gpu]
command: >
bash -c '/app/.venv/bin/jupyter lab --ip="*" --port=8888 --NotebookApp.token="" --NotebookApp.password="" --no-browser --allow-root'Dockerfileからビルドしてコンテナを起動します。
docker compose up
Dockerの起動後にブラウザの検索窓に”localhost:8888″を入力すると、Jupyter Labをブラウザで表示できます。
localhost:8888Llama 3.1 Swallowの実装
Dockerコンテナで起動したJupyter Lab上でLlama 3.1 Swallowの実装をします。
Jupyter Labのコードセルに次のコマンドを実行して、ライブラリをインポートします。
import torch
import transformers
from transformers import AutoModelForCausalLM, AutoTokenizer,BitsAndBytesConfigLlama 3.1 Swallowのモデルとトークナイザーを読み込みます。
model_id = "tokyotech-llm/Llama-3.1-Swallow-8B-Instruct-v0.1"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
device_map="auto",
)“tokyotech-llm/Llama-3.1-Swallow-8B-Instruct-v0.1”
モデルのタイプを指定しています。
AutoModelForCausalLM.from_pretrained()
モデルを読み込みます。
torch_dtype=torch.bfloat16,:BF16の数値表現を指定しています。
量子化をする場合はquantization_config=BitsAndBytesConfig(load_in_4bit=True),を引数に追加してください。
AutoTokenizer.from_pretrained()
トークナイザーを読み込みます。
| モデルID | パラメータサイズ | GPUメモリ使用量 |
|---|---|---|
| tokyotech-llm/Llama-3.1-Swallow-8B-Instruct-v0.1 | 80億パラメータ | 17GB(BF16,量子化なし) |
| tokyotech-llm/Llama-3.1-Swallow-70B-Instruct-v0.1 | 700億パラメータ | 43GB(BF16,量子化あり) |
モデルを量子化して読み込みます。
量子化によりモデルの精度が低下しますが、GPUメモリを節約することができます。
model_id = "tokyotech-llm/Llama-3.1-Swallow-8B-Instruct-v0.1"
tokenizer = AutoTokenizer.from_pretrained(model_id)
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16
)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
quantization_config=bnb_config,
device_map="auto",
)
bnb_config = BitsAndBytesConfig(…
load_in_4bit=True:モデルのパラメータを4ビット量子化してロードすることを指定します。
bnb_4bit_quant_type="nf4":4ビット量子化の手法としてnf4を使用することを指定します。
bnb_4bit_compute_dtype=torch.bfloat16:計算時のデータ型をbfloat16に指定します。
Llama 3.1 Swallowのでテキスト生成

Llama 3.1 Swallow 8Bを使って、日本語での質問応答を試してみます。
日本語での質問応答(1)
「宮崎県のご当地グルメを教えて下さい。」というプロンプトを日本語で実行してみます。
DEFAULT_SYSTEM_PROMPT = "あなたは日本語で回答するアシスタントです。"
text = "宮崎県のご当地グルメを教えて下さい。"
messages = [
{"role": "system", "content": DEFAULT_SYSTEM_PROMPT},
{"role": "user", "content": text},
]
prompt = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
token_ids = tokenizer.encode(
prompt, add_special_tokens=False,
return_tensors="pt"
)
with torch.no_grad():
output_ids = model.generate(
token_ids.to(model.device),
max_new_tokens=512,
do_sample=True,
temperature=0.6,
top_p=0.9,
)
output = tokenizer.decode(
output_ids.tolist()[0][token_ids.size(1):],
skip_special_tokens=True
)
print(output)messages = [ {“role”: “system”, “content”: DEFAULT_SYSTEM_PROMPT}, {“role”: “user”, “content”: text},]
モデルに入力するシステムプロンプトとユーザーからのプロンプトを定義しています。
prompt = tokenizer.apply_chat_template(…
tokenizer.apply_chat_template: 与えられたmessagesを元に生成用のプロンプトを作成しています。add_generation_prompt=True: モデルが生成を開始するべき場所を明示的に指示するフラグです。
token_ids = tokenizer.encode(…
生成したプロンプトをトークンに変換しています。
return_tensors="pt" によって、PyTorchのテンソル形式に変換しています。
with torch.no_grad(…
モデルが新しいトークンを生成します。
max_new_tokens=512: 生成される新しいトークンの最大数を指定。do_sample=True: サンプリングを有効にし、確率的にトークンを選択することで多様な出力を生成。temperature=0.6: サンプリングの多様性を調整するパラメータ。低い値にするほど生成が保守的になり、高い値にするとランダム性が増します。top_p=0.9: top-pサンプリングの確率マスを指定し、選ばれたトークンの合計確率が0.9になるように上位のトークンから選択します。
output = tokenizer.decode(…
生成されたトークン列をデコードし、文字列に変換します。
skip_special_tokens=True によって、特殊トークンが除外されます。
宮崎県のご当地グルメを教えて下さい。
宮崎県のご当地グルメといえば、まず「チキン南蛮」が挙げられます。宮崎県は鶏肉の生産量が日本一であり、その鶏肉を使用した料理として有名です。揚げた鶏肉に甘酢のソースをかけたもので、ご飯のおかずやお酒のおつまみとして人気です。
また、「冷や汁」も宮崎県の代表的な料理です。冷たい味噌汁に、ご飯や野菜を入れて食べるもので、夏の暑い時期にぴったりの料理です。
さらに、「宮崎ラーメン」も有名です。豚骨ベースのスープに、細麺とチャーシュー、ネギなどをトッピングしたラーメンで、宮崎県内で多くのラーメン店が営業しています。
これらの料理は、宮崎県の食文化を代表するものであり、観光客にも人気です。
日本語での質問応答(2)
「社内チャットツールの運用ルールを作成してください。」というプロンプトを実行してみます。
DEFAULT_SYSTEM_PROMPT = "あなたは日本語で回答するアシスタントです。"
text = "社内チャットツールの運用ルールを作成してください。"
messages = [
{"role": "system", "content": DEFAULT_SYSTEM_PROMPT},
{"role": "user", "content": text},
]
prompt = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
token_ids = tokenizer.encode(
prompt, add_special_tokens=False,
return_tensors="pt"
)
with torch.no_grad():
output_ids = model.generate(
token_ids.to(model.device),
max_new_tokens=512,
do_sample=True,
temperature=0.6,
top_p=0.9,
)
output = tokenizer.decode(
output_ids.tolist()[0][token_ids.size(1):],
skip_special_tokens=True
)
print(output)社内チャットツールの運用ルールを作成してください。
社内チャットツールの運用ルール
**目的**
このルールは、社内チャットツールの適切な使用を促進し、円滑なコミュニケーションを実現することを目的としています。
**基本原則**
1. **敬意と礼儀**: チャットツール上でのコミュニケーションは、常に敬意と礼儀を持って行うこと。
2. **明確な表現**: メッセージは明確かつ簡潔に表現すること。
3. **プライバシー保護**: 個人情報や機密情報は、チャットツール上で共有しないこと。
**使用方法**
1. **チャットツールの選択**: 社内チャットツールとして、指定されたツールを使用すること。
2. **アカウント管理**: チャットツールのアカウントは、会社が管理すること。
3. **ログイン情報の管理**: ログイン情報は、会社が管理すること。
4. **メッセージの送信**: チャットツール上でのメッセージ送信は、業務時間内に限ること。
**禁止事項**
1. **個人攻撃**: チャットツール上での個人攻撃は禁止すること。
2. **誹謗中傷**: チャットツール上での誹謗中傷は禁止すること。
3. **機密情報の共有**: チャットツール上での機密情報の共有は禁止すること。
4. **スパム行為**: チャットツール上でのスパム行為は禁止すること。
**トラブル対応**
1. **トラブル発生時の対応**: チャットツール上でのトラブルが発生した場合、速やかに会社に報告すること。
2. **トラブル解決**: チャットツール上でのトラブル解決は、会社が行うこと。
**変更と更新**
1. **ルールの変更**: このルールは、会社の判断により変更または更新されることがある。
2. **変更の通知**: ルールの変更または更新については、チャットツール上で通知すること。
**最終更新日**
\[日付
コード生成
「add_generation_prompt=Trueの役割を教えて下さい。」というプロンプトを実行してみます。
DEFAULT_SYSTEM_PROMPT = "あなたは日本語で回答するアシスタントです。"
text = '''以下のadd_generation_prompt=Trueの役割を教えて下さい。
prompt = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)'''
messages = [
{"role": "system", "content": DEFAULT_SYSTEM_PROMPT},
{"role": "user", "content": text},
]
prompt = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
token_ids = tokenizer.encode(
prompt, add_special_tokens=False,
return_tensors="pt"
)
with torch.no_grad():
output_ids = model.generate(
token_ids.to(model.device),
max_new_tokens=512,
do_sample=True,
temperature=0.6,
top_p=0.9,
)
output = tokenizer.decode(
output_ids.tolist()[0][token_ids.size(1):],
skip_special_tokens=True
)
print(output)add_generation_prompt=Trueの役割を教えて下さい。
モデルの応答
`add_generation_prompt=True` の役割は、会話テンプレートに生成プロンプトを追加することです。
生成プロンプトとは、モデルが生成するテキストの開始部分です。通常、会話テンプレートでは、ユーザーの入力に応じてモデルが応答を生成しますが、生成プロンプトを追加することで、モデルが生成するテキストの開始部分を指定できます。
たとえば、ユーザーが「今日の天気は?」と入力した場合、モデルは「今日の天気は」という生成プロンプトに基づいて「今日の天気は晴れです」という応答を生成します。
`add_generation_prompt=True` を指定すると、会話テンプレートに生成プロンプトが追加され、モデルが生成するテキストの開始部分が指定されます。これにより、モデルが生成するテキストの品質と一貫性が向上することが期待できます。
生成AI・LLMのコストでお困りなら
GPUのスペック不足で生成AIの開発が思うように進まないことはありませんか?
そんなときには、高性能なGPUをリーズナブルな価格で使えるGPUクラウドサービスがおすすめです!

GPUSOROBANは、生成AI・LLM向けの高速GPUを業界最安級の料金で使用することができます。
インターネット環境さえあれば、クラウド環境のGPUサーバーをすぐに利用可能です。
大規模な設備投資の必要がなく、煩雑なサーバー管理からも解放されます。







