
この記事では、Sarashina(サラシナ)のファインチューニングを紹介します。
Sarashinaはソフトバンクの子会社のSB Intuitionsが開発した日本語に強いLLMです。
Sarashinaの事前学習モデルに指示チューニングを施すことで、チャット形式の応答ができるようになります。

Sarashinaのファインチューニング

Sarashinaとは
Sarashina(サラシナ)は、ソフトバンクの子会社のSB Intuitionsが開発した日本語に強いLLMです。
Sarashinaは、日本語データを1兆トークンも学習しており、これはMetaが開発したLlama2の日本語学習量の数百倍に相当します。
Sarashinaについて詳しく知りたい方は、以下の記事をご覧ください。

指示チューニングとは
Sarashinaの事前学習モデルでは、チャット形式の応答ができないため、別途指示チューニングが必要になります。
指示チューニング(Instruction Tuning)とは、モデルを指示に応じた応答ができるように学習させ、適応させることです。
この記事では、HuggingFaceのSFTTrainerを使って、Sarashinaの事前学習モデルに対してフルパラメータのファインチューニングをします。
SFTTrainer
SFTTrainerは、教師ありファインチューニング(Supervised Fine-tuning)で学習するためのライブラリです。
Transformersライブラリに統合されており、少ないコードでファインチューニングの実装ができます。
使用するデータセット
モデルの学習にはデータセット「kunishou/databricks-dolly-15k-ja」を使用します。
15,000以上の指示と応答で構成された日本語データセットです。
英語のデータセットを日本語に自動翻訳して作成されたため、翻訳調な日本語になっています。


事前準備

必要なスペック・実行環境
Sarashinaのファインチューニングでは、大容量のGPUメモリを必要とします。
この記事では、GPUメモリ80GBを搭載したNVIDIA A100 80GBのインスタンスを使用しています。
実行環境の詳細は以下のとおりです。
- GPU:NVIDIA A100 80GB
- GPUメモリ(VRAM):80GB
- OS:Ubuntu22.04
- Docker
Dockerで環境構築

Dockerを使用してSarashinaの環境構築をしていきます。
Dockerの使い方は以下の記事をご覧ください。

Dockerfileにインストールするパッケージを記述します。
- CUDA:12.1
- Python:3.10
- PyTorch:2.2.2
- transformers:4.41.2
- bitsandbytes
- ninja
- packaging
- accelerate
- datasets
- bitsandbytes
- evaluate
- trl
- peft
- wheel
- sentencepiece
- flash-attn
- JupyterLab
- huggingface_hub[cli]
- wandb
Ubuntuのコマンドラインから、Dockerfileを作成します。
mkdir sarashina_instruct
cd sarashina_instruct
nano Dockerfile次の記述をコピーしてDockerfileに貼り付けます。
# ベースイメージ(CUDA)の指定
FROM nvidia/cuda:12.1.0-cudnn8-devel-ubuntu22.04
# 必要なパッケージをインストール
RUN apt-get update && apt-get install -y python3-pip python3-venv git nano
# 作業ディレクトリを設定
WORKDIR /app
# アプリケーションコードをコピー
COPY . /app
# Python仮想環境の作成
RUN python3 -m venv /app/.venv
# 仮想環境をアクティベートするコマンドを.bashrcに追加
RUN echo "source /app/.venv/bin/activate" >> /root/.bashrc
# JupyterLab,HuggingFaceHub,WandBのインストール
RUN /app/.venv/bin/pip install Jupyter \
jupyterlab \
huggingface_hub[cli] \
wandb
# PyTorchのインストール
RUN /app/.venv/bin/pip install torch==2.2.2 torchvision==0.17.2 torchaudio==2.2.2 --index-url https://download.pytorch.org/whl/cu121
# Transformer関連のインストール
RUN /app/.venv/bin/pip install \
transformers==4.41.2 \
ninja \
packaging \
accelerate \
datasets \
bitsandbytes \
evaluate \
trl \
peft \
wheel \
sentencepiece
# Flash attentionをインストール
RUN /app/.venv/bin/pip install flash-attn --no-build-isolation
# コンテナの起動時にbashを実行
CMD ["/bin/bash"]docker-compose.ymlファイルを使ってDockerコンテナの設定をします。
docker-compose.ymlファイルを作成します。
nano docker-compose.yml次の記述をコピーしてdocker-compose.ymlに貼り付けます。
services:
sarashina_instruct:
build:
context: .
dockerfile: Dockerfile
image: sarashina_instruct
runtime: nvidia
container_name: sarashina_instruct
ports:
- "8888:8888"
volumes:
- .:/app/sarashina_instruct
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: 1
capabilities: [gpu]
command: >
bash -c '/app/.venv/bin/jupyter lab --ip="*" --port=8888 --NotebookApp.token="" --NotebookApp.password="" --no-browser --allow-root'Dockerfileからビルドしてコンテナを起動します。
docker compose upDockerの起動後にブラウザの検索窓に”localhost:8888″を入力すると、Jupyter Labをブラウザで表示できます。
localhost:8888Sarashinaファインチューニングの実装

Dokcerコンテナ上で起動したJupyter Labを使って、Sarashinaのファインチューニングを実装していきます。
Jupyter Labのコードセルで以下のコマンドを実行します。
必要なライブラリをインポートします。
import torch
import transformers
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline, logging
from datasets import load_dataset
from trl import SFTTrainer, SFTConfig
import wandb学習ログの管理をするために、WandBにログインします。(WandBを使用しない場合は省略してください。)
API_KEY = "*************"
wandb.login(key=API_KEY)WandbでAPIキーを発行する方法を以下の記事で解説しています。

モデルとトークナイザーのダウンロードをして読み込みます。
model_id = "sbintuitions/sarashina2-7b"
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
device_map="auto",
attn_implementation="flash_attention_2"
)
tokenizer = AutoTokenizer.from_pretrained(
model_id,
padding_side="right",
add_eos_token=True
)sbintuitions/sarashina2-7b
Sarashina 7Bの事前学習モデルを指定しています。
AutoModelForCausalLM.from_pretrained
モデルの読み込む設定をしています。
torch.bfloat16
Bfloat16は、FP32と同じ数値範囲を持ちながら、GPUメモリを節約でき、計算速度も向上します。
attn_implementation=”flash_attention_2″
Transformerの処理を効率化して学習を高速するライブラリを指定しています。
AutoTokenizer.from_pretrained
トークナイザーの読み込み設定をしています。
ファインチューニング前のモデルを使って、テキスト生成のテストをしてみます。
prompt = "香川県のご当地グルメを教えて下さい"
pipeline = transformers.pipeline(
"text-generation",
model=model,
tokenizer=tokenizer
)
output = pipeline(
prompt,
max_length=256,
truncation=True,
do_sample=True,
pad_token_id=tokenizer.pad_token_id,
num_return_sequences=3,
)
print(output[0]['generated_text'])香川県のご当地グルメを教えて下さい。
香川県のご当地グルメを教えて下さい。よろしくお願い致します。 香川県の名物料理 こんばんは、私は香川県に住んでいるのですが、香川県の有名な料理って何でしょうか? ご存知の方は教えて下さい。 よろしくお願いします。 香川県の名物 こんにちは、香川県の名物って何がありますか? 回答をよろしくお願いします。 香川県のおススメグルメを教えてください! 4月中旬に香川県に行くことになり、ご当地グルメを食べることを楽しみにしております。 香川県はうどん以外にも、骨付き鳥やオリーブ牛、あんもち雑煮など、たくさんのグルメがあると聞いたのですが、この中から私が食べたことがあるものは、骨付き鳥と、あんもち雑煮、あと水ようかんです。 この中で、私が食べたことがないご当地グルメのオススメがありましたら、ぜひ教えてください! 香川グルメ 香川の名物グルメといえばうどんが筆頭にあがりますが, それ以外で,香川のおいしいものといえば何でしょう? 讃岐牛,骨付き鳥,しょうゆ豆,あん餅雑煮(これは岡山の郷土料理?),栗林のアイスクリン,一鶴のとりめしぐらいしか知らないのです。 何かおいしいものありませんか? 香川県の名物 骨付鳥・あんもち雑煮 について質問 香川県で有名な 骨付鳥 あんもち雑煮 の店で お勧めのとこがあったら教えて下さい。 香川の名物といえば・・・ 香川の名物といえば、なんといっても讃岐うどん!ですよね。でも讃岐うどんしか
Sarashinaの事前学習モデルでは、チャット形式の応答ができていないことが分かります。
事前学習モデルは人間の意図に沿った応答ができないため、指示チューニングが必要です。
モデルの学習に使用するデータセット「kunishou/databricks-dolly-15k-ja」を読み込みます。
dataset = load_dataset("kunishou/databricks-dolly-15k-ja", split="train")データセットから「instruction(指示)」と「output(応答)」を抽出して、チャットテンプレートに変換して、データセットを更新します。
template = "{% for message in messages %}{{'<|im_start|>' + message['role'] + '\n' + message['content'] + '<|im_end|>' + '\n'}}{% endfor %}"
tokenizer.chat_template = template
def formatting_func(example):
messages = [
{'role': "system", 'content': "あなたは日本語で回答するアシスタントです。"},
{'role': "user", 'content': example["instruction"]},
{'role': "assistant", 'content': example["output"]}
]
return tokenizer.apply_chat_template(messages, tokenize=False)
def update_dataset(example):
example["text"] = formatting_func(example)
for field in ["index", "category", "instruction", "input", "output"]:
example.pop(field, None)
return example
dataset = dataset.map(update_dataset)
print(dataset[312]["text"])チャットテンプレート変換後のデータセットの例
<|im_start|>system
あなたは日本語で回答するアシスタントです。<|im_end|>
<|im_start|>user
良い写真を撮るためのポイントとは?<|im_end|>
<|im_start|>assistant
良い写真には、光、被写体、構図という3つの重要な要素があります。優れた写真は、ピントが合っていて、シャープで、露出(光)がよく、構図が決まっています。 完璧な写真を撮るためには、正しい焦点距離で撮影し、フレーム内の被写体に適した絞りを設定し、撮影するアクションに合わせてシャッタースピードを設定し(スポーツでは高いシャッタースピード、ポートレートでは低いシャッタースピード)、シャッタースピードと絞りの両方に対応するようにISOが正しく設定されていることを確認する必要があります。 ISO、絞り、シャッタースピードがどのように連動しているかを理解することが、完璧な写真を撮るための鍵となります。<|im_end|>tokenizer.chat_template = template
Tokenizerにチャットテンプレートが定義されていないため、新しくチャットテンプレートを作成しています。
def formatting_func(example):
データセットの「instruction」と「output」をチャットテンプレートに変換する関数を定義しています。
def update_dataset(example):
チャットテンプレートに変換したデータを「text」フィールドに代入し、その他の不要なフィールドを削除しています。
チャットテンプレート
チャットテンプレートの記号は以下のような意味を持っています。
<|im_start|>system...<|im_end|>:システムメッセージが入ります。
<|im_start|>user...<|im_end|>:プロンプト(指示)が入ります。
<|im_start|>assistant...<|im_end|>:レスポンス(応答)が入ります。 学習パラメータを設定しています。
sft_config = SFTConfig(
output_dir="./results",
bf16=True,
per_device_train_batch_size=4,
gradient_accumulation_steps=16,
num_train_epochs=2,
optim="adamw_torch_fused",
learning_rate=2e-4,
lr_scheduler_type="cosine",
warmup_steps=100,
weight_decay=0.01,
logging_steps=10,
save_strategy= "epoch",
group_by_length=True,
dataset_text_field="text",
max_seq_length=512,
packing=True,
report_to="wandb"
)per_device_train_batch_size
一度に処理するバッチのサイズを指定します。GPUメモリが不足する場合は、値を小さくします。
gradient_accumulation_steps
勾配累積。この値を大きくすることで、擬似的にミニバッチのサイズを大きくすることができます。
group_by_length=True
同じ長さのシーケンスをまとめてバッチ化して、メモリを節約しています。
report_to=”wandb”
WandBにログを主力します。WandBを使用しない場合は、コメントアウトしてください。
SFTTrainerを使って教師ありファインチューニング(Supervised Fine-tuning)を実行します。
new_model="sarashina2-7b-instruct"
trainer = SFTTrainer(
model=model,
tokenizer=tokenizer,
train_dataset=dataset,
args=sft_config,
)
wandb.init(project="sarashina2-7b-instruct")
trainer.train()
trainer.model.save_pretrained(new_model)SFTTrainer(…
事前に設定したモデルやトークナイザー、データセット、学習パラメータ等をSFTTrainerに渡しています。
wandb.init(…
WandBの記録を開始します。WandBと連携しない場合はコメントアウトしてください。
WandBに保存したファインチューニング実行中のメトリクスを確認します。
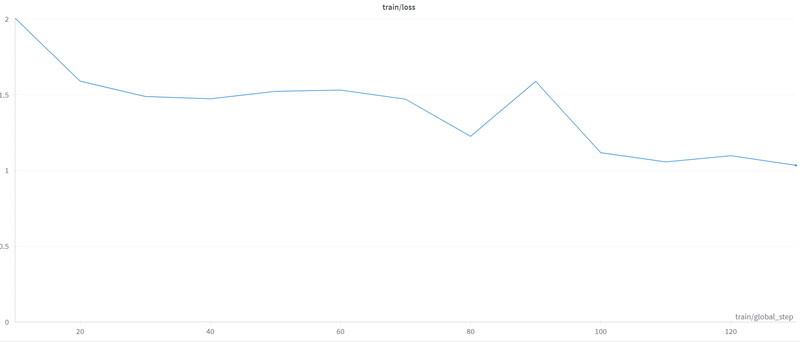
Loss(損失)は学習が進むにつれて小さくなっています。
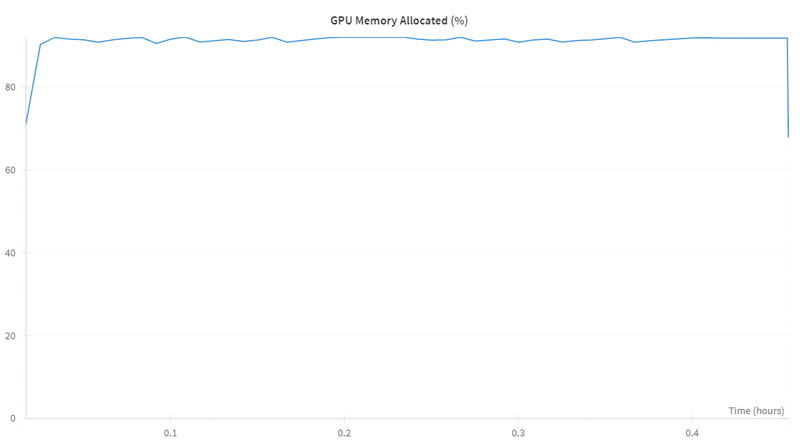
GPUメモリは、ピーク91%(72GB)を使用しています。
ファインチューニング後のモデルでテキスト生成

ファインチューニング後のモデルでテキスト生成をしていきます。
ファインチューニング後のモデルを読み込みます。
torch.cuda.empty_cache()
ft_model = AutoModelForCausalLM.from_pretrained(
new_model,
device_map='auto',
torch_dtype=torch.bfloat16,
attn_implementation="flash_attention_2"
)
tokenizer = AutoTokenizer.from_pretrained(
model_id
)
tokenizer.chat_template = templatetorch.cuda.empty_cache()
テキスト生成を実行する前に、ファインチューニングで使用していたGPUメモリをリセットしています。
AutoModelForCausalLM.from_pretrained(new_model,…
ファインチューニング後のモデルを読み込んでいます。
「香川県のご当地グルメを教えて下さい。」というプロンプトを実行します。
messages = [
{'role': "system",'content': "あなたは日本語で回答するアシスタントです。"},
{"role": "user", "content": "香川県のご当地グルメを教えて下さい"}
]
input_ids = tokenizer.apply_chat_template(
messages,
add_generation_prompt=True,
return_tensors="pt"
).to(ft_model.device)
terminators = [
tokenizer.eos_token_id,
tokenizer.convert_tokens_to_ids("<|im_end|>")
]
outputs = ft_model.generate(
input_ids,
max_new_tokens=512,
eos_token_id=terminators,
pad_token_id=tokenizer.pad_token_id,
do_sample=True,
repetition_penalty=1.2,
temperature=0.6,
top_p=0.9,
)
response = outputs[0][input_ids.shape[-1]:]
print(tokenizer.decode(response, skip_special_tokens=True))香川県のご当地グルメを教えて下さい。
<|im_start|>assistant
香川県のローカルフードといえば、「讃岐うどん」を思い浮かべる人が多いと思います。しかし、それだけではありません。骨付き鳥やしょうゆ豆、オリーブやレモンを使った料理など、さまざまな料理があります。<|im_end|>
生成AI・LLMのコストでお困りなら
GPUのスペック不足で生成AIの開発が思うように進まないことはありませんか?
そんなときには、高性能なGPUをリーズナブルな価格で使えるGPUクラウドサービスがおすすめです!

GPUSOROBANは、高性能GPU「NVIDIA H200」を業界最安級の料金で使用することができます。
NVIDIA H200は、生成AI・LLMの計算にかかる時間を大幅に短縮することが可能です。
クラウドで使えるため、大規模な設備投資の必要がなく、煩雑なサーバー管理からも解放されます。







