
Sarashinaは、ソフトバンクの子会社のSB Intuitionsが開発した日本語に強いLLMです。
70億・130億・650億パラメータの複数モデルを公開し、いずれも無料で商用利用可能です。
この記事では、Sarashinaの性能から使い方まで紹介します。

Sarashinaとは

Sarashina(サラシナ)は、ソフトバンクの子会社のSB Intuitionsが開発した日本語に強いLLMです。
Sarashinaは、日本語データを1兆トークンも学習しており、これはMetaが開発したLlama2の日本語学習量の数百倍に相当します。
ざっくり言うと
- 日本語に強いLLM
- 70億・130億・650億パラメータの複数モデルを公開
- 無料で商用利用も可能

Sarashinaのモデル

Sarashinaのモデルには複数の種類があり、「モデルのバージョン」と「パラメータサイズ」で分けられます。
| モデルID | モデルのバージョン | パラメータサイズ |
| sbintuitions/sarashina1-7b | Sarashina1 | 70億パラメータ |
| sbintuitions/sarashina1-13b | Sarashina1 | 130億パラメータ |
| sbintuitions/sarashina1-65b | Sarashina1 | 650億パラメータ |
| sbintuitions/sarashina2-7b | Sarashina2 | 70億パラメータ |
| sbintuitions/sarashina2-13b | Sarashina2 | 130億パラメータ |
Sarashina1は日本語のみを学習していますが、Sarashina2は日本語に加えて英語とプログラミングコードも学習しています。
Sarashina1
学習データ: 日本語
学習トークン数: 1兆トークン
語彙サイズ: 51,200
アーキテクチャ: GPT-NeoX
Sarashina2
学習データ: 日本語、英語、プログラミングコード(日本語5:英語4:コード1の割合)
学習トークン数: 2.1兆トークン
語彙サイズ: 102,400
アーキテクチャ: Llama2
Sarashinaの性能

日本語評価において標準的な5つの評価セットを使って、モデルの性能を比較しています。
Sarashina2は同程度のパラメータ数のモデルと比較して、高い性能を出しています。
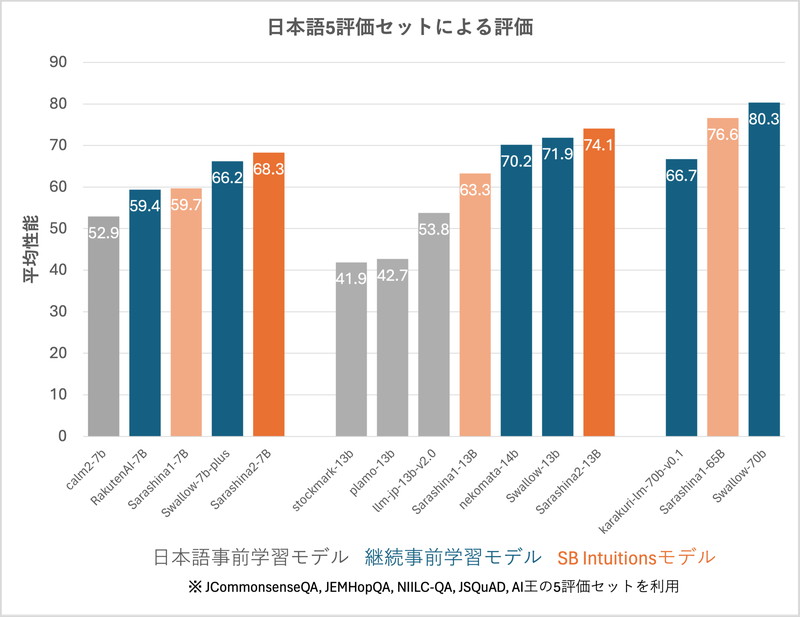
JCommonsenseQA(多肢選択式質問応答)
JEMHopQA(自由記述式質問応答)
NIILC-QA(自由記述式質問応答)
JSQuAD(機械読解)
AI王(自由記述式質問応答)
Sarashinaの商用利用・ライセンス

Sarashinaは、Hugging FaceにおいてMITライセンスをもとに提供されており、無料で商用利用できます。
MITライセンスは、ソフトウェアの配布に使用される非常に寛容なオープンソースライセンスです。
商用利用:ソフトウェアやコードを商用利用することが完全に許可されています。
改変:ソフトウェアを自由に修正したり改変したりすることができます。
配布:修正したり変更したりしたソフトウェアを自由に配布することができます。
著作権の表示:再配布時にオリジナルの著作権表示とライセンス条項を含める必要があります。
特許利用:特許利用に関する明示的な規定はありません。
Sarashinaの使い方

ここからSarashinaを使ったテキスト生成(推論)について解説していきます。
Sarashinaのファインチューニングの方法については、別の記事で解説しています。

実行環境
この記事で用意した実行環境は以下のとおりです。
- GPU:NVIDIA A100 80GB
- GPUメモリ(VRAM):80GB
- OS :Ubuntu 22.04
- Docker
Dockerで環境構築
Dockerを使用してSarashinaの環境構築をします。
Dockerの使い方は以下の記事をご覧ください。

コンテナにインストールするパッケージは以下のとおりです。
CUDA、PyTorch、Transformersはバージョン依存関係によるエラーが起きやすいので、動作検証済のバージョン指定してインストールしています。
- CUDA:12.1
- Python:3.10
- PyTorch:2.2.2
- transformers:4.41.2
- accelerate
- triton
- sentencepiece
Ubuntuのコマンドラインで、Dockerfileを作成します。
mkdir sarashina_inference
cd sarashina_inference
nano DockerfileDockerfileに以下の記述を貼り付けます。
# ベースイメージ(CUDA)の指定
FROM nvidia/cuda:12.1.0-cudnn8-devel-ubuntu22.04
# 必要なパッケージをインストール
RUN apt-get update && apt-get install -y python3-pip python3-venv git nano
# 作業ディレクトリを設定
WORKDIR /app
# アプリケーションコードをコピー
COPY . /app
# Python仮想環境の作成
RUN python3 -m venv /app/.venv
# 仮想環境をアクティベートするコマンドを.bashrcに追加
RUN echo "source /app/.venv/bin/activate" >> /root/.bashrc
# JupyterLabのインストール
RUN /app/.venv/bin/pip install Jupyter jupyterlab
# PyTorchのインストール
RUN /app/.venv/bin/pip install torch==2.2.2 torchvision==0.17.2 torchaudio==2.2.2 triton --index-url https://download.pytorch.org/whl/cu121
# Transformer関連のインストール
RUN /app/.venv/bin/pip install transformers==4.41.2 accelerate sentencepiece protobuf
# コンテナの起動時にbashを実行
CMD ["/bin/bash"]docker-compose.ymlでDockerコンテナの設定をします。
docker-compose.ymlのYAMLファイルを作成して開きます。
nano docker-compose.yml以下のコードをコピーして、YAMLファイルに貼り付けます。
services:
sarashina_inference:
build:
context: .
dockerfile: Dockerfile
image: sarashina_inference
runtime: nvidia
container_name: sarashina_inference
ports:
- "8888:8888"
volumes:
- .:/app/sarashina_inference
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: 1
capabilities: [gpu]
command: >
bash -c '/app/.venv/bin/jupyter lab --ip="*" --port=8888 --NotebookApp.token="" --NotebookApp.password="" --no-browser --allow-root'Dockerfileからビルドしてコンテナを起動します。
docker compose up
Dockerの起動後にブラウザの検索窓に”localhost:8888″を入力すると、Jupyter Labをブラウザで表示できます。
localhost:8888Sarashinaの実装
Dockerコンテナで起動したJupyter Lab上でSarashinaの実装をします。
Jupyter Labのコードセルに次のコマンドを実行して、ライブラリをインポートします。
import torch
import transformers
from transformers import AutoModelForCausalLM, AutoTokenizer, pipelineSarashinaのモデルとトークナイザーを読み込みます。
model_id = "sbintuitions/sarashina2-13b"
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(
model_id
)
pipeline = transformers.pipeline(
"text-generation",
model=model,
tokenizer=tokenizer
)“sbintuitions/sarashina2-13b”
Sarashinaのモデルタイプを指定します。
AutoModelForCausalLM.from_pretrained()
モデルを読み込みます。
AutoTokenizer.from_pretrained()
トークナイザーを読み込みます。
transformers.pipeline()
テキスト生成のためのパイプラインの設定をします。
| モデルID | モデルのバージョン | パラメータサイズ | GPUメモリ使用量 |
| sbintuitions/sarashina1-7b | Sarashina1 | 70億パラメータ | 16GB |
| sbintuitions/sarashina1-13b | Sarashina1 | 130億パラメータ | 29B |
| sbintuitions/sarashina1-65b | Sarashina1 | 650億パラメータ | 130GB |
| sbintuitions/sarashina2-7b | Sarashina2 | 70億パラメータ | 16GB |
| sbintuitions/sarashina2-13b | Sarashina2 | 130億パラメータ | 29GB |
Sarashinaでテキスト生成

Sarashinaを使って、日本語での質問応答を試してみます。
日本語での質問応答
「香川県のご当地グルメを教えて下さい」というプロンプトを日本語で実行してみます。
prompt = "香川県のご当地グルメを教えて下さい"
output = pipeline(
prompt,
max_length=256,
truncation=True,
do_sample=True,
pad_token_id=tokenizer.pad_token_id,
num_return_sequences=3,
)
print(output[0]['generated_text'])香川県のご当地グルメを教えて下さい
香川県のご当地グルメを教えて下さい。
A うどんと骨付鳥
うどんと骨付鳥 うどん屋が1つや2つじゃないです本当に多くて迷います! 讃岐うどんなので安いのも魅力ですね。 高松は、うどんマップとか見るとうどん屋の激戦地です。
骨付鳥も、香川発祥のご当地グルメで、丸亀とかのローカルグルメかと思いきや、 今は香川の色々な場所に店が出てて、 香川の友達に、骨付鳥知らないって言ったら、『香川出身ですっけ?』って聞かれました笑
A 香川県はうどん県と言われるだけあり、うどんは有名ですが、骨付鶏肉料理も有名です。
香川県の鶏料理専門店「一鶴(いっかく)」で食べられます。
A うどんです。香川県民みんなが讃岐なのでは?と思います。
ちなみに私の知人の香川県民はさぬき市と高松市の方が多いので、他は分かりません。
A 香川と言えば、うどん以外にないでしょう。骨付き鳥もありますが、香川生まれ香川育ちの私でも食べたことありません。
A さぬきうどんです。
A やはりうどんがいちばん有名ですが、小豆島のそうめん(小豆島手延そうめん)もおすすめですよ!
A もちろん、さぬきうどんです。
「さぬきうどん」と名のつく店は全国にあります。
うどん
Sarashinaの指示チューニングの方法は、以下の記事で解説しています。
生成AI・LLMのコストでお困りなら
GPUのスペック不足で生成AIの開発が思うように進まないことはありませんか?
そんなときには、高性能なGPUをリーズナブルな価格で使えるGPUクラウドサービスがおすすめです!

GPUSOROBANは、高性能GPU「NVIDIA H200」を業界最安級の料金で使用することができます。
NVIDIA H200は、生成AI・LLMの計算にかかる時間を大幅に短縮することが可能です。
クラウドで使えるため、大規模な設備投資の必要がなく、煩雑なサーバー管理からも解放されます。







