
Tanuki-8x8Bは、東京大学松尾・岩澤研究室が開発した日本語特化のLLMです。
日本語での共感的かつ自然な対話や文章生成に優れ、GPT-3.5 Turboと同等の性能を誇ります。
この記事では、Tanuki-8x8Bの性能から使い方まで紹介します。

Tanuki-8x8Bとは

Tanuki-8x8Bは、東京大学松尾・岩澤研究室が開発した日本語特化のLLMです。
日本語での共感的かつ自然な対話と文章生成に優れ、GPT-3.5 Turboと同等の性能を誇ります。
このモデルはHugging Faceで無料で公開されており、研究用途および商業利用が可能です。

Tanuki-8x8Bのモデル

Tanukiシリーズには、8億パラメータのDense構造を持つTanuki-8B-dpo-v1.0と、
47億パラメータのMixture of Experts (MoE)構造を採用したTanuki-8x8B-dpo-v1.0の2つのモデルがあります。
どちらのモデルもHuggingFaceで公開されています。
| モデルID | パラメータサイズ | アーキテクチャ | 公開 |
|---|---|---|---|
| weblab-GENIAC/Tanuki-8B-dpo-v1.0 | 8億パラメータ | Dense | HuggingFace |
| weblab-GENIAC/Tanuki-8x8B-dpo-v1.0 | 47億パラメータ | Mixture of Experts (MoE) | HuggingFace |
Dense構造
全てのパラメータを常に活用するシンプルかつ一貫したアーキテクチャで、汎用性が高い一方、計算コストも大きくなります。GPT-3やLlamaなどがDense構造を採用しています。
Mixture of Experts (MoE)構造
特定のパラメータを選択的に使用することで計算効率を大幅に向上させ、非常に大規模なモデルでも効率的に動作するように設計されたアーキテクチャです。GPT-4やMistralがMoE構造を採用しています。
Tanuki-8x8Bの性能

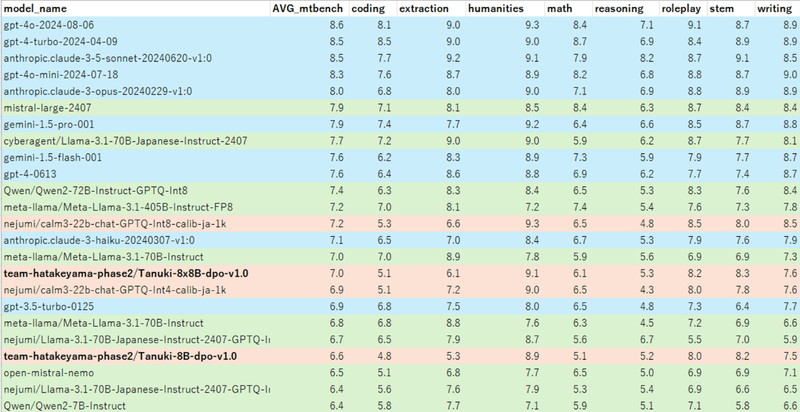
日本語性能を評価するベンチマークのJapanese MT-Benchでは、Tanuki-8x8Bは他の国産モデルと比較して高い評価を得ています。
特に日本語の対話や作文タスクで高いパフォーマンスを発揮し、GPT-4oやClaude 3.5などのトップモデルと比較しても遜色のない結果を示しています。
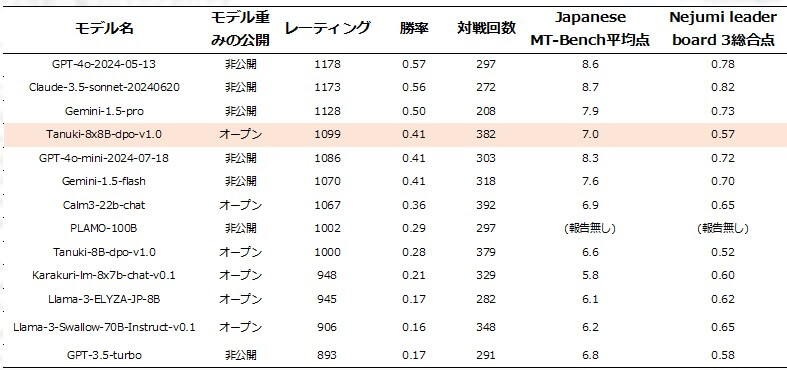
Chatbot Arenaでの評価において、Tanuki-8x8Bは国産LLMの中でトップクラスの評価を獲得しました。
Chatbot Arenaは、複数の言語モデルを対戦形式で比較し、人間のフィードバックを基に各モデルの性能をランク付けすることで、実際の使いやすさや応答の質を評価できるシステムです。
Tanuki-8x8Bの商用利用・ライセンス

Tanuki-8x8Bは商用利用が可能で、Apache License 2.0で提供されています。
HuggingFace上でモデルが公開されており、誰でもアクセスして利用することができます。
商用利用:ソフトウェアやコードを商用利用することが許可されています。
改変:ソフトウェアやコードを自由に修正したり改変したりすることができます。
配布:修正したり変更したりしたソフトウェアを自由に配布することができます。
著作権表示:元の著作権表示とライセンス条項を含める必要があります。
特許利用:利用者に特許使用権が付与されています。
詳細は「Apache License」のページをご確認ください。
Tanuki-8x8Bの使い方

ここからTanuki-8x8Bを使ったテキスト生成について解説していきます。
実行環境
この記事で用意した実行環境は以下のとおりです。
- GPU:NVIDIA A100 80GB
- GPUメモリ(VRAM):80GB
- OS :Ubuntu 22.04
- Docker
Dockerで環境構築
Dockerを使用してTanuki-8x8Bの環境構築をします
Dockerの使い方は以下の記事をご覧ください。

コンテナにインストールするパッケージは以下のとおりです。
CUDA、PyTorch、Transformersはバージョン依存関係によるエラーが起きやすいので、動作検証済のバージョン指定してインストールしています。
- CUDA:12.1
- Python:3.10
- PyTorch:2.2.2
- transformers:4.44.0
- accelerate
- triton
Ubuntuのコマンドラインで、Dockerfileを作成します。
mkdir tanuki_8x8
cd tanuki_8x8
nano DockerfileDockerfileに以下の記述を貼り付けます。
# ベースイメージ(CUDA)の指定
FROM nvidia/cuda:12.1.0-cudnn8-devel-ubuntu22.04
# 必要なパッケージをインストール
RUN apt-get update && apt-get install -y python3-pip python3-venv git nano
# 作業ディレクトリを設定
WORKDIR /app
# アプリケーションコードをコピー
COPY . /app
# Python仮想環境の作成
RUN python3 -m venv /app/.venv
# 仮想環境をアクティベートするコマンドを.bashrcに追加
RUN echo "source /app/.venv/bin/activate" >> /root/.bashrc
# JupyterLabのインストール
RUN /app/.venv/bin/pip install Jupyter jupyterlab
# PyTorchのインストール
RUN /app/.venv/bin/pip install torch==2.2.2 torchvision==0.17.2 torchaudio==2.2.2 --index-url https://download.pytorch.org/whl/cu121
# Transformer関連のインストール
RUN /app/.venv/bin/pip install transformers==4.44.0 accelerate bitsandbytes wheel
# Flash attentionをインストール
RUN /app/.venv/bin/pip install flash-attn --no-build-isolation
# コンテナの起動時にbashを実行
CMD ["/bin/bash"]docker-compose.ymlでDockerコンテナの設定をします。
docker-compose.ymlのYAMLファイルを作成して開きます。
nano docker-compose.yml以下のコードをコピーして、YAMLファイルに貼り付けます。
services:
tanuki_8x8:
build:
context: .
dockerfile: Dockerfile
image: tanuki_8x8
runtime: nvidia
container_name: tanuki_8x8
ports:
- "8888:8888"
volumes:
- .:/app/tanuki_8x8
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: 1
capabilities: [gpu]
command: >
bash -c '/app/.venv/bin/jupyter lab --ip="*" --port=8888 --NotebookApp.token="" --NotebookApp.password="" --no-browser --allow-root'Dockerfileからビルドしてコンテナを起動します。
docker compose up
Dockerの起動後にブラウザの検索窓に”localhost:8888″を入力すると、Jupyter Labをブラウザで表示できます。
localhost:8888Tanuki-8x8Bの実装

Dockerコンテナで起動したJupyter Lab上でTanuki-8x8Bの実装をします。
Jupyter Labのコードセルに次のコマンドを実行して、ライブラリをインポートします。
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer,BitsAndBytesConfigTanuki-8x8Bのモデルとトークナイザーを読み込みます。
model_id = "weblab-GENIAC/Tanuki-8x8B-dpo-v1.0"
model = AutoModelForCausalLM.from_pretrained(
model_id,
device_map="auto",
torch_dtype="auto",
quantization_config=BitsAndBytesConfig(load_in_4bit=True),
trust_remote_code=True
)
tokenizer = AutoTokenizer.from_pretrained(model_id)model_id = “weblab-GENIAC/Tanuki-8x8B-dpo-v1.0” : モデルのタイプを指定しています。
AutoModelForCausalLM.from_pretrained():モデルを読み込みます。
device_map="auto": 使用するデバイスを自動選択します。この場合、GPUが優先されます。
torch_dtype="auto":使用するデータ型を自動選択します。
quantization_config=BitsAndBytesConfig(load_in_4bit=True),:4bit量子化の指定をしています。
AutoTokenizer.from_pretrained():トークナイザーを読み込みます。
| モデルID | パラメータサイズ | GPUメモリ |
|---|---|---|
| weblab-GENIAC/Tanuki-8x8B-dpo-v1.0 | 47億パラメータ | 27GB |
- モデルを読み込む際にGPUメモリを消費するため、余裕を持ったGPUメモリをご用意ください。
- この記事では、BF16の数値表現と4bit量子化した場合のGPUメモリ使用量を記載しています。
Tanuki-8x8Bでテキスト生成

Tanuki-8x8Bを使って、日本語での質問応答を試してみます。
日本語での質問応答
「掃除が面倒ですが、どのようなモチベーションで臨めばよいですか。」という質問をしてみます。
messages = [
{"role": "system", "content": "以下は、タスクを説明する指示です。要求を適切に満たす応答を書きなさい。"},
{"role": "user", "content": "掃除が面倒ですが、どのようなモチベーションで臨めばよいですか。"}
]
input_ids = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
)
token_ids = tokenizer.encode(
input_ids,
add_special_tokens=False,
return_tensors="pt"
)
with torch.no_grad():
output_ids = model.generate(
token_ids.to(model.device),
max_new_tokens=256,
do_sample=True,
temperature=0.5
)
output = tokenizer.decode(
output_ids.tolist()[0][token_ids.size(1):],
skip_special_tokens=True
)
print(output)掃除が面倒ですが、どのようなモチベーションで臨めばよいですか。
掃除を面倒に感じるのは自然なことです。しかし、モチベーションを見つけることで、そのプロセスが少し楽になるかもしれません。以下にいくつかの方法を提案します。
1.目標設定:
– 短期的な目標と長期的な目標を設定しましょう。例えば、「今日はリビングのテーブルを片付ける」や「毎週末にキッチンを掃除する」といった具体的な目標を立てると、達成感を得やすくなります。
2.環境の改善:
– 掃除をすることで部屋がきれいになり、快適な空間が生まれます。これにより、リラックスしたり集中力を高めたりすることができ、結果的に生活の質が向上します。
3.健康面でのメリット:
– 清潔な環境はアレルギーや感染症の予防につながります。また、整理整頓された空間はストレスを軽減し、精神的な安定をもたらします。
4.時間管理のスキル向上:
– 掃除を習慣化することで、効率的な時間管理のスキルが身につきます。これは他のタスクにも
日本語での質問応答(2)
「人生最後の日に何をしたいですか。」という質問をしてみます。
messages = [
{"role": "system", "content": "以下は、タスクを説明する指示です。要求を適切に満たす応答を書きなさい。"},
{"role": "user", "content": "人生最後の日に何をしたいですか。"}
]
input_ids = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
)
token_ids = tokenizer.encode(
input_ids,
add_special_tokens=False,
return_tensors="pt"
)
with torch.no_grad():
output_ids = model.generate(
token_ids.to(model.device),
max_new_tokens=256,
do_sample=True,
temperature=0.5
)
output = tokenizer.decode(
output_ids.tolist()[0][token_ids.size(1):],
skip_special_tokens=True
)
print(output)人生最後の日に何をしたいですか。
人生最後の日に何をしたいかを考えることは、非常に個人的で深いテーマです。この問いに対する答えは、個々人の価値観、目標、経験、そして感情によって大きく異なります。以下は、いくつかの一般的な視点や要素を考慮した応答です。
1. 家族や友人との時間
– 大切な人たちと過ごす: 愛する人々と一緒に過ごし、感謝の気持ちを伝える。
– 思い出を共有する: 過去の思い出を振り返り、笑い合ったり、涙を流したりして絆を深める。
2. 自己実現と成長
– 未完のプロジェクトに取り組む: やり残したことや、達成したかったことに最後の時間を捧げる。
– 学び続ける: 知識を深めたり、新しいスキルを身につけたりするために、何かを学ぶ。
3. 自然との触れ合い
– 美しい場所を訪れる: お気に入りの場所や、まだ訪れていない場所でリラックスする。
– 自然の中で瞑想する:
生成AI・LLMのコストでお困りなら
GPUのスペック不足で生成AIの開発が思うように進まないことはありませんか?
そんなときには、高性能なGPUをリーズナブルな価格で使えるGPUクラウドサービスがおすすめです!

GPUSOROBANは、生成AI・LLM向けの高速GPUを業界最安級の料金で使用することができます。
インターネット環境さえあれば、クラウド環境のGPUサーバーをすぐに利用可能です。
大規模な設備投資の必要がなく、煩雑なサーバー管理からも解放されます。







