
Llama-3-EvoVLM-JP-v2は、Sakana AIが開発した日本語VLM(視覚言語モデル)です。
進化的モデルマージを用いて、複数画像のVLM、説明力の高いVLM、日本語のLLMの長所を組み合わせたモデルです。
この記事では、Llama-3-EvoVLM-JP-v2の使い方を分かりやすく解説します。

SakanaAI/Llama-3-EvoVLM-JP-v2とは

Llama-3-EvoVLM-JP-v2は、Sakana AIが開発した日本語VLM(視覚言語モデル)です。
進化的モデルマージを用いて、複数画像のVLM、説明力の高いVLM、日本語のLLMの長所を組み合わせたモデルです。
- 複数画像の説明:複数の画像を入力として受け取り、その内容を日本語で説明することができます。
- 画像を元にした対話:画像を基にした対話をサポートし、質問に対して適切な回答を生成します。

進化的モデルマージとは?

Sakana AIは2023年に設立されたAIスタートアップで、設立からわずか1年で評価額11億ドルを超えるユニコーン企業です。
元Google AIの研究者で「Transformer」技術を提唱したライオン・ジョーンズ氏らが手掛けるこの企業は、革新的な「進化的モデルマージ」技術を開発しました。
- 進化的アルゴリズムは、異なる特性を持つ複数のモデルを融合し、新たな高性能モデルを構築できます。
- モデルの再トレーニングを行わずに、既存モデルの長所を活かした新しいモデルが短期間で作成可能です。
- 比較的小規模なGPUでモデルを構築できるため、コスト効率も非常に高いです。
SakanaAI/Llama-3-EvoVLM-JP-v2のモデル

Llama-3-EvoVLM-JP-v2は、80億パラメータをもつVLMのモデルです。
進化的モデルマージ技術により以下の3つのモデルの長所を組み合わせて、視覚と言語の両方の能力を高めています。
複数画像の視覚言語モデル(VLM): 複数の画像を扱える英語ベースの視覚言語モデル。具体的には、「Mantis-8B-siglip-llama3」が使用されています。このモデルは、画像に基づく質疑応答や説明が得意です。
説明力の高い視覚言語モデル(VLM): 単一の画像に対する描写や説明能力に優れたモデル。「Bunny-v1.1-Llama-3-8B-V」が使用されており、画像内容の詳細な描写が可能です。
日本語の大規模言語モデル(LLM): 日本語での応答や生成に特化した大規模言語モデル。「Meta-Llama-3-8B-Instruct」がベースとなっています。このモデルにより、日本語での自然な言語生成が可能になります。
| モデルID | パラメータサイズ | GPUメモリ | 公開 |
|---|---|---|---|
| SakanaAI/Llama-3-EvoVLM-JP-v2 | 80億パラメータ | 21GB | HuggingFace |
SakanaAI/Llama-3-EvoVLM-JP-v2の性能

Llama-3-EvoVLM-JP-v2の性能は、VLM(視覚言語モデル)の性能を評価するために設計されたベンチマークのにおいて、結果が公表されています。
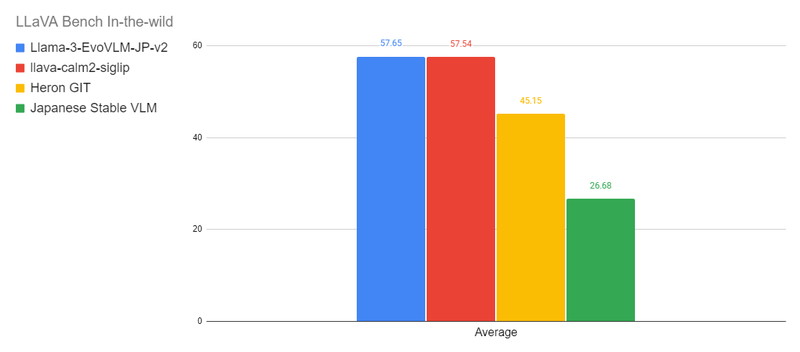
以下の図は、LLaVA-Bench-In-The-Wildにおけるベンチマーク結果を示しており、各タスクの平均スコアをモデルごとに比較したグラフです。
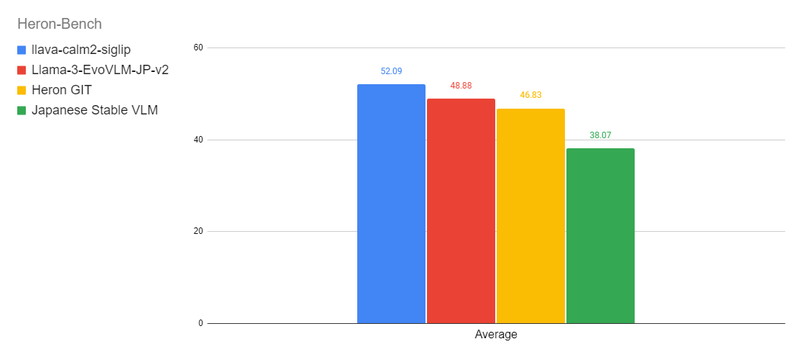
以下の図は、Heron-Benchにおけるベンチマーク結果を示しており、各タスクの平均スコアをモデルごとに比較したグラフです。
LLaVA-Bench-In-The-Wild
LLaVA-Bench-In-The-Wildは、さまざまなドメインから取得した画像とそれに対応する質問のペアで構成されています。データセットには、ミームや芸術作品、屋内外の風景などが含まれ、モデルの汎用性をテストします。
会話能力(Conversation)、詳細な説明能力(Detail)、複雑な推論能力(Complex)という3つの能力を評価します。
https://huggingface.co/datasets/liuhaotian/llava-bench-in-the-wild
Heron-Bench
Heron-Benchは、日本特有の画像21枚と、それに対する102の質問から構成されています。画像はアニメ、アート、文化、フード、景色、ランドマーク、交通の7つのサブカテゴリーに分類されています。
LLaVA-Bench-In-The-Wildと同様に、会話能力(Conversation)、詳細な説明能力(Detail)、複雑な推論能力(Complex)を評価しますが、日本の文化や知識に特化した質問が含まれています。
https://huggingface.co/datasets/turing-motors/Japan!ese-Heron-Bench
llava-calm2-siglipについては別の記事で解説しています

SakanaAI/Llama-3-EvoVLM-JP-v2の商用利用・ライセンス

Llama-3-EvoVLM-JP-v2は「META LLAMA 3 COMMUNITY LICENSE」のもとで提供されています。
商用利用:ソフトウェアやコードを商用利用することが許可されています。
改変:ソフトウェアやコードを自由に修正したり改変したりすることができます。
配布:修正したり変更したりしたソフトウェアを自由に配布することができます。
著作権表示:再配布時に、著作権の表示や契約書コピーの提供などが必要になります。
特許利用:特許利用に関する明示的な規定はありません。
詳細は「META LLAMA 3 COMMUNITY LICENSE」のページをご確認ください。
SakanaAI/Llama-3-EvoVLM-JP-v2の使い方

Llama-3-EvoVLM-JP-v2を使ったテキスト生成について解説していきます。
実行環境
この記事で用意した実行環境は以下のとおりです。
- GPU:NVIDIA A100 80GB
- GPUメモリ(VRAM):80GB
- OS :Ubuntu 22.04
- Docker
Dockerで環境構築
Dockerを使用してLlama-3-EvoVLM-JP-v2の環境構築をします
Dockerの使い方は以下の記事をご覧ください。

コンテナにインストールするパッケージは以下のとおりです。
CUDA、PyTorch、Transformersはバージョン依存関係によるエラーが起きやすいので、動作検証済のバージョン指定してインストールしています。
- CUDA:12.1
- Python:3.10
- PyTorch:2.2.2
- transformers:4.41.2
- packaging
- accelerate
- Pillow
- Requests
- wheel
- flash-attn
Ubuntuのコマンドラインで、Dockerfileを作成します。
mkdir sakana_vlm
cd sakana_vlm
nano DockerfileDockerfileに以下の記述を貼り付けます。
# ベースイメージ(CUDA)の指定
FROM nvidia/cuda:12.1.0-cudnn8-devel-ubuntu22.04
# 必要なパッケージをインストール
RUN apt-get update && apt-get install -y python3-pip python3-venv git nano
# 作業ディレクトリを設定
WORKDIR /app
# アプリケーションコードをコピー
COPY . /app
# Python仮想環境の作成
RUN python3 -m venv /app/.venv
# 仮想環境をアクティベートするコマンドを.bashrcに追加
RUN echo "source /app/.venv/bin/activate" >> /root/.bashrc
# JupyterLabのインストール
RUN /app/.venv/bin/pip install Jupyter jupyterlab
# PyTorchのインストール
RUN /app/.venv/bin/pip install torch==2.2.2 torchvision==0.17.2 torchaudio==2.2.2 --index-url https://download.pytorch.org/whl/cu121
# Transformer関連のインストール
RUN /app/.venv/bin/pip install transformers==4.41.2 \
sentencepiece \
accelerate \
Pillow \
Requests
# Mantisのインストール
RUN /app/.venv/bin/pip install git+https://github.com/TIGER-AI-Lab/Mantis.git
# コンテナの起動時にbashを実行
CMD ["/bin/bash"]docker-compose.ymlでDockerコンテナの設定をします。
docker-compose.ymlのYAMLファイルを作成して開きます。
nano docker-compose.yml以下のコードをコピーして、YAMLファイルに貼り付けます。
services:
sakana_vlm:
build:
context: .
dockerfile: Dockerfile
image: sakana_vlm
runtime: nvidia
container_name: sakana_vlm
ports:
- "8888:8888"
volumes:
- .:/app/sakana_vlm
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: 1
capabilities: [gpu]
command: >
bash -c '/app/.venv/bin/jupyter lab --ip="*" --port=8888 --NotebookApp.token="" --NotebookApp.password="" --no-browser --allow-root'Dockerfileからビルドしてコンテナを起動します。
docker compose up
Dockerの起動後にブラウザの検索窓に”localhost:8888″を入力すると、Jupyter Labをブラウザで表示できます。
localhost:8888SakanaAI/Llama-3-EvoVLM-JP-v2の実装

Dockerコンテナで起動したJupyter Lab上でLlama-3-EvoVLM-JP-v2の実装をします。
Jupyter Labのコードセルに次のコマンドを実行して、ライブラリをインポートします。
import requests
from PIL import Image
import torch
from mantis.models.conversation import Conversation, SeparatorStyle
from mantis.models.mllava import chat_mllava, LlavaForConditionalGeneration, MLlavaProcessor
from mantis.models.mllava.utils import conv_templates
from transformers import AutoTokenizerチャットテンプレートを設定します。
conv_llama_3_elyza = Conversation(
system="<|start_header_id|>system<|end_header_id|>\n\nあなたは誠実で優秀な日本人のアシスタントです。特に指示が無い場合は、常に日本語で回答してください。",
roles=("user", "assistant"),
messages=(),
offset=0,
sep_style=SeparatorStyle.LLAMA_3,
sep="<|eot_id|>",
)
conv_templates["llama_3"] = conv_llama_3_elyzaconv_llama_3_elyza = Conversation()
<|start_header_id|>system<|end_header_id|> :システムメッセージが入ります。
roles=("user", "assistant"):ユーザーとアシスタントを定義しています。
messages=():初期メッセージは空のタプルで、会話の開始時に送信されるメッセージを指定する部分です。
offset=0:メッセージのオフセットで、メッセージがどの位置から始まるかを示します。
sep_style: セパレータのスタイルをSeparatorStyle.LLAMA_3 に指定しています。
sep: メッセージの区切り文字やトークンです。ここでは "<|eot_id|>" をしています。
conv_templates[“llama_3”] = conv_llama_3_elyza
辞書にキーとして "llama_3" を指定し、その値に作成した conv_llama_3_elyza インスタンスを格納しています。
Llama-3-EvoVLM-JP-v2のモデルとプロセッサを読み込みます。
model_id = "SakanaAI/Llama-3-EvoVLM-JP-v2"
processor = MLlavaProcessor.from_pretrained("TIGER-Lab/Mantis-8B-siglip-llama3"
processor.tokenizer.pad_token = processor.tokenizer.eos_token
model = LlavaForConditionalGeneration.from_pretrained(model_id, torch_dtype=torch.float16, device_map="cuda").eval()MLlavaProcessor.from_pretrained(“TIGER-Lab/Mantis-8B-siglip-llama3”)
プロセッサをロードしています。
processor.tokenizer.pad_token = processor.tokenizer.eos_token
パディングトークンpad_tokenを終了トークンeos_tokenに設定しています。
LlavaForConditionalGeneration.from_pretrained(model_id, torch_dtype=torch.float16, device_map=”cuda”).eval()
model_id に指定されたモデルをロードしています。
torch_dtype=torch.float16 モデルをFP16でロードしています。
device_map="cuda"モデルは指定されたGPUにロードされます。
eval() モデルを評価モードに設定します。
| モデルID | パラメータサイズ | GPUメモリ | 公開 |
|---|---|---|---|
| SakanaAI/Llama-3-EvoVLM-JP-v2 | 80億パラメータ | 21GB | HuggingFace |
生成パラメータを設定しています
generation_kwargs = {
"max_new_tokens": 128,
"num_beams": 1,
"do_sample": False,
"no_repeat_ngram_size": 3,
}generation_kwargs ={}
"max_new_tokens": 128
モデルが生成する新しいトークンの最大数を128に設定しています。
"num_beams": 1
ビームサーチの幅を1に設定し、単一のシーケンスを生成する標準のグリーディサーチを行います。
"do_sample": False
サンプリングを行わないように設定しています
no_repeat_ngram_size
生成されるテキスト内で同じ3つのトークンの連続が繰り返されるのを防ぎます。
SakanaAI/Llama-3-EvoVLM-JP-v2で画像からテキストを生成

Llama-3-EvoVLM-JP-v2を使って、画像の入力からテキストを生成してみます。
画像を説明
「この画像について説明してください。」というプロンプトを英語で実行してみます。
#画像からテキスト生成
image_path = ["testimg.jpg", "testimg2.jpg"]
text = "<image><image>それぞれの画像について、違いを教えて下さい。"
response, history = chat_mllava(text, image_path, model, processor, **generation_kwargs)
print(response)#画像を縮小して表示
resized_images = [img.resize((int(img.width * 0.3), int(img.height * 0.3))) for img in image_path]
for resized_image in resized_images:
resized_image.show()text = “<image><image>それぞれの画像について、違いを教えて下さい”
<image>2枚の画像をしていするため、2つのimageタグを使用しています。
response, history = chat_mllava(text, image_path, model, processor, **generation_kwargs)
- テキストと画像を入力として受け取り、モデルとプロセッサーを使って応答を生成します。
textとimage_pathは入力として渡され、modelとprocessorは使用するモデルと画像プロセッサーを指します。generation_kwargsは、生成パラメータです。response(生成された応答)とhistory(過去の応答の履歴)が返されます。


それぞれの画像について、違いを教えて下さい
Image 1は、3匹の猫が並んで座っている様子を、Image 2は、2匹の白い小型犬が並んでいる様子が描かれています。
生成AI・LLMのコストでお困りなら
GPUのスペック不足で生成AIの開発が思うように進まないことはありませんか?
そんなときには、高性能なGPUをリーズナブルな価格で使えるGPUクラウドサービスがおすすめです!

GPUSOROBANは、高性能GPU「NVIDIA H200」を業界最安級の料金で使用することができます。
NVIDIA H200は、生成AI・LLMの計算にかかる時間を大幅に短縮することが可能です。
クラウドで使えるため、大規模な設備投資の必要がなく、煩雑なサーバー管理からも解放されます。







