
llava-calm2-siglipは、サイバーエージェントが開発した日本語対応のVLM(視覚言語モデル)です。
画像の内容をもとにテキストを生成することができ、特に日本語を得意としています。
この記事では、llava-calm2-siglipの使い方を分かりやすく解説します。

llava-calm2-siglipとは

llava-calm2-siglipは、サイバーエージェントが開発した日本語対応のVLM(視覚言語モデル)です。
このモデルは、画像とテキストの両方を処理でき、特に日本語の理解と生成に強みを持っています。
- 画像の説明:画像を入力として受け取り、その内容を日本語で説明することができます。
- 画像を元にした対話:画像を基にした対話をサポートし、質問に対して適切な回答を生成します。

llava-calm2-siglipのモデル

llava-calm2-siglipは、75億パラメータをもつVLMのモデルになります。
llava-calm2-siglipは、LLaVA 1.5アーキテクチャに基づいており、cyberagent/calm2-7b-chatを言語モデルとして使用し、画像の処理にはgoogle/siglip-so400m-patch14-384という画像エンコーダーを使用しています。
| モデルID | パラメータサイズ | 量子化 | GPUメモリ | 公開 |
|---|---|---|---|---|
| cyberagent/llava-calm2-siglip | 75億パラメータ | なし | 17GB | HuggingFace |
llava-calm2-siglipの性能

llava-calm2-siglipの性能は、VLM(視覚言語モデル)の性能を評価するために設計されたベンチマークのにおいて、結果が公表されています。
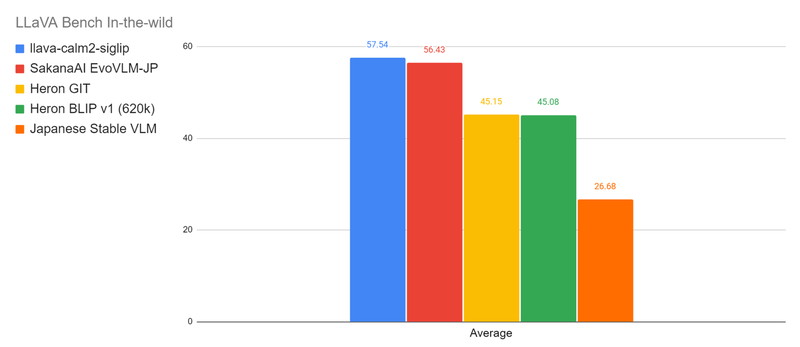
以下の図は、LLaVA-Bench-In-The-Wildにおけるベンチマーク結果を示しており、各タスクの平均スコアをモデルごとに比較したグラフです。
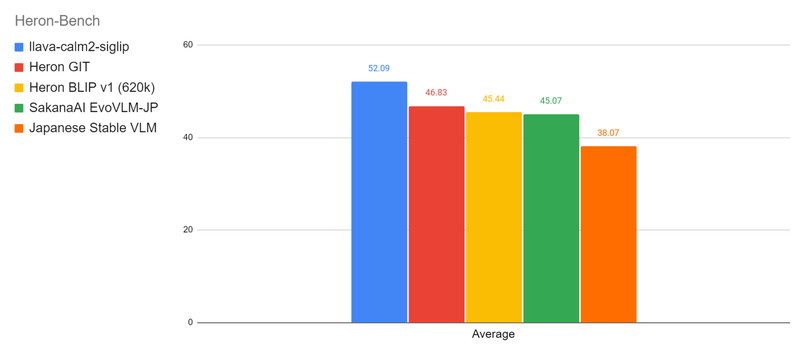
以下の図は、Heron-Benchにおけるベンチマーク結果を示しており、各タスクの平均スコアをモデルごとに比較したグラフです。
LLaVA-Bench-In-The-Wild
LLaVA-Bench-In-The-Wildは、さまざまなドメインから取得した画像とそれに対応する質問のペアで構成されています。データセットには、ミームや芸術作品、屋内外の風景などが含まれ、モデルの汎用性をテストします。
会話能力(Conversation)、詳細な説明能力(Detail)、複雑な推論能力(Complex)という3つの能力を評価します。
https://huggingface.co/datasets/liuhaotian/llava-bench-in-the-wild
Heron-Bench
Heron-Benchは、日本特有の画像21枚と、それに対する102の質問から構成されています。画像はアニメ、アート、文化、フード、景色、ランドマーク、交通の7つのサブカテゴリーに分類されています。
LLaVA-Bench-In-The-Wildと同様に、会話能力(Conversation)、詳細な説明能力(Detail)、複雑な推論能力(Complex)を評価しますが、日本の文化や知識に特化した質問が含まれています。
https://huggingface.co/datasets/turing-motors/Japanese-Heron-Bench
llava-calm2-siglipの商用利用・ライセンス

llava-calm2-siglipは商用利用が可能で、Apache License 2.0で提供されています。
Hugging Face上でモデルが公開されており、誰でもアクセスして利用することができます。
商用利用:ソフトウェアやコードを商用利用することが許可されています。
改変:ソフトウェアやコードを自由に修正したり改変したりすることができます。
配布:修正したり変更したりしたソフトウェアを自由に配布することができます。
著作権表示:元の著作権表示とライセンス条項を含める必要があります。
特許利用:利用者に特許使用権が付与されています。
詳細は「Apache License」のページをご確認ください。
llava-calm2-siglipの使い方

llava-calm2-siglipを使ったテキスト生成について解説していきます。
実行環境
この記事で用意した実行環境は以下のとおりです。
- GPU:NVIDIA A100 80GB
- GPUメモリ(VRAM):80GB
- OS :Ubuntu 22.04
- Docker
Dockerで環境構築
Dockerを使用してllava-calm2-siglipの環境構築をします
Dockerの使い方は以下の記事をご覧ください。

コンテナにインストールするパッケージは以下のとおりです。
CUDA、PyTorch、Transformersはバージョン依存関係によるエラーが起きやすいので、動作検証済のバージョン指定してインストールしています。
- CUDA:12.1
- Python:3.10
- PyTorch:2.2.2
- transformers:4.41.2
- packaging
- accelerate
- Pillow
- Requests
- wheel
- flash-attn
Ubuntuのコマンドラインで、Dockerfileを作成します。
mkdir llava_calm2
cd llava_calm2
nano DockerfileDockerfileに以下の記述を貼り付けます。
# ベースイメージ(CUDA)の指定
FROM nvidia/cuda:12.1.0-cudnn8-devel-ubuntu22.04
# 必要なパッケージをインストール
RUN apt-get update && apt-get install -y python3-pip python3-venv git nano
# 作業ディレクトリを設定
WORKDIR /app
# アプリケーションコードをコピー
COPY . /app
# Python仮想環境の作成
RUN python3 -m venv /app/.venv
# 仮想環境をアクティベートするコマンドを.bashrcに追加
RUN echo "source /app/.venv/bin/activate" >> /root/.bashrc
# JupyterLabのインストール
RUN /app/.venv/bin/pip install Jupyter jupyterlab
# PyTorchのインストール
RUN /app/.venv/bin/pip install torch==2.2.2 torchvision==0.17.2 torchaudio==2.2.2 --index-url https://download.pytorch.org/whl/cu121
# Transformer関連のインストール
RUN /app/.venv/bin/pip install transformers==4.41.2 \
packaging \
accelerate \
Pillow \
Requests \
wheel
# Flash attentionをインストール
RUN /app/.venv/bin/pip install flash-attn --no-build-isolation
# コンテナの起動時にbashを実行
CMD ["/bin/bash"]docker-compose.ymlでDockerコンテナの設定をします。
docker-compose.ymlのYAMLファイルを作成して開きます。
nano docker-compose.yml以下のコードをコピーして、YAMLファイルに貼り付けます。
services:
llava_calm2:
build:
context: .
dockerfile: Dockerfile
image: llava_calm2
runtime: nvidia
container_name: llava_calm2
ports:
- "8888:8888"
volumes:
- .:/app/llava_calm2
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: 1
capabilities: [gpu]
command: >
bash -c '/app/.venv/bin/jupyter lab --ip="*" --port=8888 --NotebookApp.token="" --NotebookApp.password="" --no-browser --allow-root'Dockerfileからビルドしてコンテナを起動します。
docker compose up
Dockerの起動後にブラウザの検索窓に”localhost:8888″を入力すると、Jupyter Labをブラウザで表示できます。
localhost:8888llava-calm2-siglipの実装

Dockerコンテナで起動したJupyter Lab上でllava-calm2-siglipの実装をします。
Jupyter Labのコードセルに次のコマンドを実行して、ライブラリをインポートします。
from PIL import Image
import requests
from transformers import AutoProcessor, LlavaForConditionalGeneration
import torchllava-calm2-siglipのモデルとトークナイザーを読み込みます。
model_id = "cyberagent/llava-calm2-siglip"
model = LlavaForConditionalGeneration.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
device_map="cuda",
_attn_implementation='flash_attention_2'
).to(0)
processor = AutoProcessor.from_pretrained(
model_id,
)cyberagent/llava-calm2-siglip : llava-calm2-siglipのモデルタイプを指定します。
LlavaForConditionalGeneration.from_pretrained():モデルを読み込みます。
flash_attention_2:推論を高速化するFlash Attentionを指定しています。
AutoProcessor.from_pretrained():画像処理のプロセッサーとトークナイザーを読み込みます。
| モデルID | パラメータサイズ | 量子化 | GPUメモリ使用量 |
| cyberagent/llava-calm2-siglip | 75億パラメータ | なし | 17GB |
画像とテキストを入力して、テキストを生成する関数を定義します。
def textvision(prompt, path_image):
image = Image.open(path_image)
inputs = processor(prompt, image, return_tensors="pt").to("cuda:0", torch.bfloat16)
generate_ids = model.generate(
**inputs,
max_new_tokens=512,
do_sample=True,
)
response = processor.tokenizer.decode(
generate_ids[0][:-1],
skip_special_tokens=True,
clean_up_tokenization_spaces=False
)
resized_image = image.resize((int(image.width * 0.5), int(image.height * 0.5)))
resized_image.show()
print(response)Image.open()
指定されたパスをもとに画像を開きます。
processor.tokenizer.apply_chat_template()
メッセージにチャットテンプレートを適用します。
processor(prompt, [image], return_tensors=”pt”).to(“cuda:0”)
テキストと画像をテンソル変換してProcessorに渡し、GPUに転送しています。
model.generate()
入力データをもとにトークンIDを生成します。
processor.batch_decode()
モデルが生成したトークンIDをテキストに変換します。
llava-calm2-siglipで画像からテキストを生成

llava-calm2-siglipを使って、画像の入力からテキストを生成してみます。
画像を説明
「この画像について説明してください。」というプロンプトを英語で実行してみます。
prompt = """USER: <image>
この画像について説明してください。
ASSISTANT: """
path_image = "testimage1.jpg"
textvision(prompt, path_image)prompt = “””USER: <image>...ASSISTANT: “””
プロンプトを指定しています。
path_image = “testimage1.jpg”
画像を指定しています。

この画像について説明してください。
画像には、レンガ造りの線路の駅舎のホームが映し出されています。ホームの先には、赤と白のツートンカラーの列車が停車しています。列車の前には、改札口から出入りする人の姿が数名見えます。ホームの端には、茶色のタイルが敷き詰められています。ホームの真ん中あたりには、乗客が座ることを想定されたベンチが二つ置かれています。そのうちの一つには、スーツを着た猫が座っています。猫は、胸元にネクタイを締めています
画像からキャッチコピー作成(1)
「この画像からスタッフ募集のキャッチコピーを10個作成してください。」というプロンプトを日本語で実行してみます。
prompt = """USER: <image>
この画像からスタッフ募集のキャッチコピーを10個作成してください。
ASSISTANT: """
path_image = "testimage2.jpg"
textvision(prompt, path_image)
この画像からスタッフ募集のキャッチコピーを10個作成してください。
1. 建設現場で活躍する人猫を募集中!
2. 猫好きにはたまらない、建設作業員募集です!
3. 猫の手で、より良い建設現場を作る!
4. ネコの手も借りたい、そんな現場はありますか?
5. 猫の手は、繊細さと強度を兼ね備えています!
6. 猫の手は、仕事にも創造性を生む!
7. 人猫プロジェクト、始動中。ぜひご参加ください!
8. 猫の手も借りたいほど忙しくなる、それが建設現場!
9. 猫の手も借りたい、猫の手も借りたい、猫の手が足りません!
10. 猫の手も借りたいくらい、情熱的になれる仕事を見つけよう!
画像からキャッチコピー作成(2)
「この画像からスーツのキャッチコピーを10個作成してください。」というプロンプトを投げてみます。
prompt = """USER: <image>
この画像からスーツのキャッチコピーを10個作成してください。
ASSISTANT: """
path_image = "testimage3.jpg"
textvision(prompt, path_image)
この画像からスーツのキャッチコピーを10個作成してください。
1. 紳士のスーツへようこそ。
2. フォーマルな席にふさわしい装いです。
3. 紳士的な姿を演出してみませんか。
4. 特別な日に着こなしたい、高品位なスーツです。
5. クラシックなデザインと仕立てが特徴です。
6. 高級感のある生地とデザインが見事に調和しています。
7. フォーマルシーンでは欠かせない一着です。
8. フォーマルな雰囲気が欲しいときに最適です。
9. 上品でスタイリッシュ、そんな言葉がぴったりです。
10. 高級感のある雰囲気を纏いながら、快適さを追求したスーツです。
生成AI・LLMのコストでお困りなら
GPUのスペック不足で生成AIの開発が思うように進まないことはありませんか?
そんなときには、高性能なGPUをリーズナブルな価格で使えるGPUクラウドサービスがおすすめです!

GPUSOROBANは、高性能GPU「NVIDIA H200」を業界最安級の料金で使用することができます。
NVIDIA H200は、生成AI・LLMの計算にかかる時間を大幅に短縮することが可能です。
クラウドで使えるため、大規模な設備投資の必要がなく、煩雑なサーバー管理からも解放されます。







