
この記事では、Unslothを使ったLlama3のファインチューニング(QLoRA)を紹介します。
UnslothによりGPUメモリの使用量を大幅に削減して、高速にファインチューニングができるようになります。

UnslothでLlama3のファインチューニング(QLoRA)

Unslothとは
この記事では、Unslothを使って、Llama3のモデルにQLoRAファインチューニングをします。
Unslothは、GPUメモリの使用量を大幅に削減して、高速にファインチューニングができるライブラリです。
Hugging FaceのSFTTrainerとも互換性があり、少ないコードでファインチューニングが実装できます。
QLoRA
QLoRAは、LoRAと量子化(Quantization)の2つの要素をもつファインチューニングの手法です。
LoRAは、モデルのパラメータを低ランク行列で近似することで、更新するパラメータ数を大幅に減らし計算量を削減しています。
量子化とは、モデルの精度を下げる代わりに、GPUメモリを大幅に節約する技術になります。
Llama3の使い方や性能・商用利用については、別記事で解説してます。

HuggigngFaceのSFTTrainerを使ったファインチューニングは、別記事で解説しています。

PyTorchのTorchtuneを使ったファインチューニングは、別記事で解説しています。

使用するデータセット
モデルの学習にはデータセット「bbz662bbz/databricks-dolly-15k-ja-gozarinnemon」を使用します。
15,000以上の指示と応答で構成された日本語データセットです。
応答が「我、りんえもんは思う。…知らんけど。」の口調になっていることが特徴です。


事前準備

必要なスペック・実行環境
Llama3のQLoRAファインチューニングでは、大容量のGPUメモリを必要とします。
この記事では、GPUメモリ80GBを搭載したNVIDIA A100 80GBのインスタンスを使用しています。
実行環境の詳細は以下のとおりです。
- GPU:NVIDIA A100 80GB
- GPUメモリ(VRAM):80GB
- OS:Ubuntu22.04
- Docker
Llama3のモデル利用申請
Llama3のモデルを使うにあたって、利用申請が必要になります。
以下の記事で利用申請の方法を紹介しています。
Dockerで環境構築

Dockerを使用してLlama3の環境構築をしていきます。
Dockerの使い方は以下の記事をご覧ください。

Dockerfileにインストールするパッケージを記述します。
- CUDA:12.1
- Python:3.10
- PyTorch:2.2.0
- Unsloth[cu121-ampere-torch220]
- Triton
- Wheel
- Jupyter Lab
- wandb
特にUnslothには、細かいバージョンの組み合わせがありますので、詳細はGithubをご参照ください。
Ubuntuのコマンドラインから、Dockerfileを作成します。
mkdir llama3_unsloth
cd llama3_unsloth
nano Dockerfile次の記述をコピーしてDockerfileに貼り付けます。
# ベースイメージ(CUDA)の指定
FROM nvidia/cuda:12.1.0-cudnn8-devel-ubuntu22.04
# 必要なパッケージをインストール
RUN apt-get update && apt-get install -y python3-pip python3-venv git nano
# 作業ディレクトリを設定
WORKDIR /app
# アプリケーションコードをコピー
COPY . /app
# Python仮想環境の作成
RUN python3 -m venv /app/.venv
# 仮想環境をアクティベートするコマンドを.bashrcに追加
RUN echo "source /app/.venv/bin/activate" >> /root/.bashrc
# JupyterLab,HuggingFaceHub,WandBのインストール
RUN /app/.venv/bin/pip install Jupyter \
jupyterlab \
huggingface_hub[cli] \
wandb
# PyTorch,Tritonのインストール
RUN /app/.venv/bin/pip install torch==2.2.0 torchvision==0.17.0 torchaudio==2.2.0 triton --index-url https://download.pytorch.org/whl/cu121
# Wheelのインストール
RUN /app/.venv/bin/pip install wheel
#Unslothをインストール
RUN /app/.venv/bin/pip install "unsloth[cu121-ampere-torch220] @ git+https://github.com/unslothai/unsloth.git"
# コンテナの起動時にbashを実行
CMD ["/bin/bash"]docker-compose.ymlファイルを使ってDockerコンテナの設定をします。
docker-compose.ymlファイルを作成します。
nano docker-compose.yml次の記述をコピーしてdocker-compose.ymlに貼り付けます。
services:
llama3_unsloth:
build:
context: .
dockerfile: Dockerfile
image: llama3_unsloth
runtime: nvidia
container_name: llama3_unsloth
ports:
- "8888:8888"
volumes:
- .:/app/unsloth
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: 1
capabilities: [gpu]
command: >
bash -c '/app/.venv/bin/jupyter lab --ip="*" --port=8888 --NotebookApp.token="" --NotebookApp.password="" --no-browser --allow-root'Dockerfileからビルドしてコンテナを起動します。
docker compose upDockerの起動後にブラウザの検索窓に”localhost:8888″を入力すると、Jupyter Labをブラウザで表示できます。
localhost:8888Llama3ファインチューニングの実装

Dockerコンテナ上で起動したJupyter Labを使って、Llama3のファインチューニングを実装していきます。
Jupyter Labのコードセルで以下のコマンドを実行していきます。
必要なライブラリをインポートします。
from unsloth import FastLanguageModel, is_bfloat16_supported
from unsloth.chat_templates import get_chat_template
import torch
from datasets import load_dataset
from trl import SFTTrainer
from transformers import TrainingArguments, AutoTokenizer
from peft import AutoPeftModelForCausalLM
from huggingface_hub import login
import wandbモデルをダウンロードするために、HuggingFaceにログインします。
token = "*************"
login(token)HuggingFaceでアクセストークンを発行する方法は以下の記事で解説しています。

学習ログの管理をするために、WandBにログインします。(WandBを使用しない場合は省略してください。)
API_KEY = "*************"
wandb.login(key=API_KEY)WandbでAPIキーを発行する方法を以下の記事で解説しています。

モデルとトークナイザーのダウンロードをして読み込みます。
max_seq_length = 2048
dtype = torch.bfloat16
load_in_4bit = True
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "unsloth/llama-3-70b-bnb-4bit",
max_seq_length = max_seq_length,
dtype = dtype,
load_in_4bit = load_in_4bit,
)max_seq_length
モデルに供給する入力テキストの最大トークン数を指定します。
torch.bfloat16
Bfloat16は、FP32と同じ数値範囲を持ちながら、GPUメモリを節約でき、計算速度も向上します。
load_in_4bit
4bit量子化の指定をしています。モデルの精度を下げて、GPUメモリの節約ができます。
FastLanguageModel.from_pretrained
モデルとトークナイザーを読み込む設定をしています。
unsloth/llama-3-70b-bnb-4bit
llama3 70Bの4bit量子化モデルを指定しています。
ファインチューニングをする前のモデルでテキスト生成のテストをしてみます。
alpaca_prompt = """
### Instruction:
{}
### Response:
{}"""
FastLanguageModel.for_inference(model)
inputs = tokenizer(
[
alpaca_prompt.format(
"観葉植物の効果とは?",
"",
)
], return_tensors = "pt").to("cuda")
terminators = [
tokenizer.eos_token_id,
tokenizer.convert_tokens_to_ids("<|eot_id|>")
]
outputs = model.generate(
**inputs,
max_new_tokens = 128,
use_cache = True,
eos_token_id=terminators,
temperature=0.6,
top_p=0.9
)
decoded_outputs = tokenizer.batch_decode(outputs,skip_special_tokens=True)
print(decoded_outputs[0])### Instruction:
観葉植物の効果とは?
### Response:
観葉植物の効果とは、緑色の植物を置いておくことによって、空間をより綺麗に感じることができることです。
モデルの学習に使用するデータセット「bbz662bbz/databricks-dolly-15k-ja-gozarinnemon」を読み込みます。
dataset = load_dataset("bbz662bbz/databricks-dolly-15k-ja-gozarinnemon", split="train")データセットから「instruction(指示)」と「output(応答)」を抽出して、チャットテンプレートに変換して、データセットを更新します。
EOS_TOKEN = tokenizer.eos_token
def formatting_prompts_func(examples):
instructions = examples["instruction"]
outputs = examples["output"]
texts = []
for instruction, output in zip(instructions, outputs):
text = alpaca_prompt.format(instruction, output) + EOS_TOKEN
texts.append(text)
return { "text" : texts, }
pass
dataset = dataset.map(formatting_prompts_func, batched = True,)
print(dataset[246]["text"])- EOS_TOKENを指定しないとエンドレスがトークンが生成されるので、ご注意ください。
- モデルの学習前に、データセットをチャットテンプレートに変換しておく必要があります。
###Instruction:
マインドフルネスを実践する際に、なぜ呼吸に集中することが有効なのでしょうか?
###Response:
我、りんえもんは思う。 瞑想は、マインドフルネスの実践の別名であり、現在に存在することがすべてでござる。 つまり、今この瞬間に起きていることを意識することでござる。 そのためには、絶えず生み出されるランダムな思考をすべて消し去り、瞬間に伝わるシグナルに五感を集中させる必要がありますでござる。 信号とは、今この瞬間に感じたり聞いたりしている感覚や感情、音などのことでござる。 そのために、呼吸は今この瞬間のアンカーとして機能する。 呼吸を意識することで、我たちは今この瞬間にとどまることができるのでござる。 やがて心が迷ったとき、呼吸は今この瞬間に戻るための合図となる。 呼吸は常に我たちのそばにあり、瞬時に見つけることができるのでござる。知らんけど。<|end_of_text|>
LoRAのパラメータ設定をします。
model = FastLanguageModel.get_peft_model(
model,
target_modules = ["q_proj", "k_proj", "v_proj", "o_proj","gate_proj", "up_proj", "down_proj",],
r = 8,
lora_alpha = 16,
lora_dropout = 0,
bias = "none",
use_gradient_checkpointing = "unsloth",
random_state = 3407,
max_seq_length = max_seq_length,
use_rslora = False,
loftq_config = None,
)target_modules = [“q_proj”,…
LoRAを適用する対象のトランスフォーマの層(Target modules)を指定します。
すべての線形層にLoRAを対象にすることでモデルの適応品質が向上すると言われています。
r=8
rはファインチューニングの過程で学習される低ランク行列のサイズを表します。
rを大きくするとモデルの適応品質が向上する傾向がありますが、必ずしも直線的な関係ではありません。
rが大きくなると更新されるパラメータが増えるため、メモリ使用量が増加します。
lora_alpha:16
LoRaスケーリングのAlphaパラメータは、学習した重みをスケーリングします。
多くの文献では、Alphaを調整可能なパラメータとして扱っておらず、Alphaを16に固定してます。
学習パラメータを設定しています。
training_arguments = TrainingArguments(
bf16 = True,
group_by_length=True,
per_device_train_batch_size = 16,
gradient_accumulation_steps = 4,
num_train_epochs=3,
warmup_steps = 100,
max_steps = 50,
learning_rate = 2e-4,
logging_steps = 1,
output_dir = "outputs",
optim = "adamw_8bit",
report_to="wandb"
)group_by_length=True
同じ長さのシーケンスをまとめてバッチ化して、メモリを節約しています。
per_device_train_batch_size
一度に処理するバッチのサイズを指定します。GPUメモリが不足する場合は、値を小さくします。
gradient_accumulation_steps
勾配累積。この値を大きくすることで、擬似的にミニバッチのサイズを大きくすることができます。
report_to=”wandb”
WandBにログを主力します。WandBを使用しない場合は、コメントアウトしてください。
SFTTrainerを使って教師ありファインチューニング(Supervised Fine-tuning)を実行します。
trainer = SFTTrainer(
model = model,
train_dataset = dataset,
dataset_text_field = "text",
max_seq_length = max_seq_length,
tokenizer = tokenizer,
args = training_arguments,
)
wandb.init(project="llama3_unsloth")
trainer.train()
model.save_pretrained("llama3_unsloth/new_model")
tokenizer.save_pretrained("llama3_unsloth/new_model")SFTTrainer(…
事前に設定したモデルやトークナイザー、データセット、LoRAパラメータ、学習パラメータ等をSFTTrainerに渡しています。
wandb.init(…
WandBの記録を開始します。WandBと連携しない場合はコメントアウトしてください。
WandBに保存したファインチューニング実行中のメトリクスを確認します。
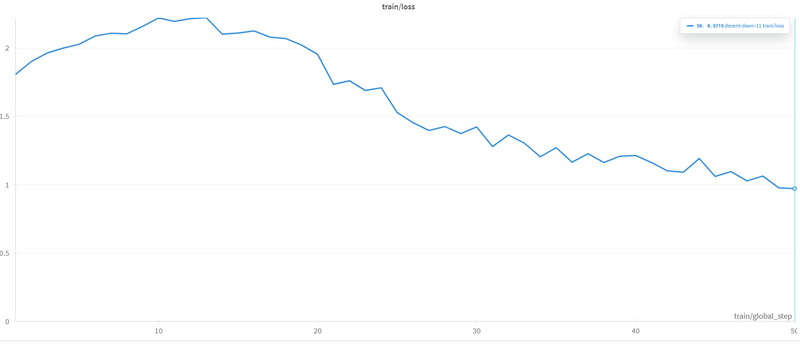
Loss(損失)は最初の60ステップで急速に減少し、その後は緩やかに小さくなり収束しています。
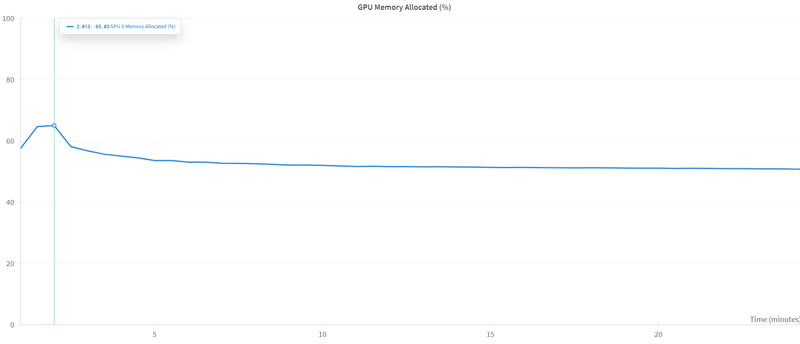
GPUメモリは、50%~70%(40GB~56GB)を使用しています。
ファインチューニング後のモデルでテキスト生成

ファインチューニング後のモデルでテキスト生成をしていきます。
ファインチューニング後のモデルを読み込みます。
torch.cuda.empty_cache()
load_model, load_tokenizer = FastLanguageModel.from_pretrained(
model_name = "llama3_unsloth/new_model",
max_seq_length = max_seq_length,
dtype = dtype,
load_in_4bit = load_in_4bit,
)
FastLanguageModel.for_inference(load_model) torch.cuda.empty_cache()
テキスト生成を実行する前に、ファインチューニングで使用していたGPUメモリをリセットしています。
FastLanguageModel.from_pretrained(…
ファインチューニング後のモデルとトークナイザーを読み込んでいます。
“観葉植物の効果とは?”というプロンプトを実行します。
inputs = load_tokenizer(
[
alpaca_prompt.format(
"観葉植物の効果とは?",
"",
)
], return_tensors = "pt").to("cuda")
outputs = load_model.generate(
**inputs,
max_new_tokens = 128,
use_cache = True,
temperature=0.6,
top_p=0.9
)
decoded_outputs = load_tokenizer.batch_decode(outputs,skip_special_tokens=True)
print(decoded_outputs[0])### Instruction:
観葉植物の効果とは?
### Response:
我、りんえもんは思う。 空気を浄化する知らんけど。
生成AI・LLMのコストでお困りなら
GPUのスペック不足で生成AIの開発が思うように進まないことはありませんか?
そんなときには、高性能なGPUをリーズナブルな価格で使えるGPUクラウドサービスがおすすめです!

GPUSOROBANは、高性能GPU「NVIDIA H200」を業界最安級の料金で使用することができます。
NVIDIA H200は、生成AI・LLMの計算にかかる時間を大幅に短縮することが可能です。
クラウドで使えるため、大規模な設備投資の必要がなく、煩雑なサーバー管理からも解放されます。







