
LangChainでは、RAGを使って回答を生成するチャットボットを構築できます。
この記事では、会話履歴を考慮したRAGチャットボットの実装について紹介します。
ざっくり言うと
- LangChainを使って会話履歴を考慮したRAGチャットボットを構築する
- 日本語のローカルLLM「Llama-3-ELYZA-JP-8B」を使用

LangChainでRAGチャットボットを構築する

この記事では、LangChainを使って会話履歴を考慮したRAGチャットボットを構築します。
プロセスは、質問を再構成するRetriever Chainと、回答を生成するChainの2つの主要なステップに分かれています。
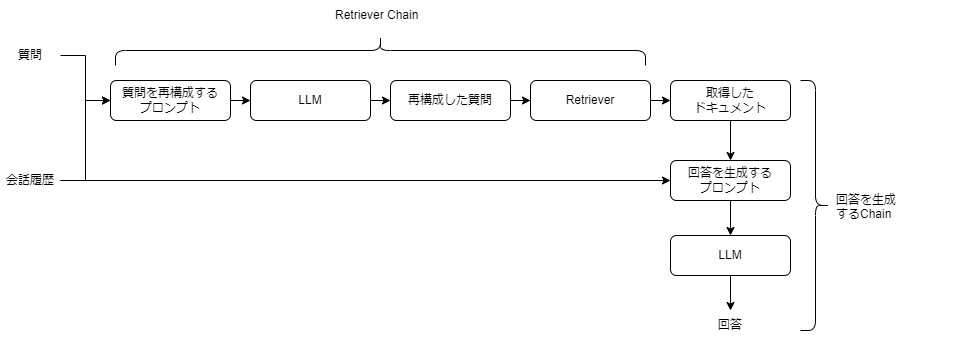
- 質問を再構成するRetriever Chain
- 質問と会話履歴をもとに、質問を再構成するプロンプトを作る
- プロンプトをもとにLLMで再構成した質問を生成する
- 再構成した質問をもとにベクトルストアから関連するドキュメントを取得する
- 回答を生成するChain
- 取得したドキュメントと、質問、会話履歴をもとに回答を生成するプロンプトを作る
- プロンプトをもとにLLMで回答を生成する

LangChain RAGの実行環境

この記事で用意した実行環境は以下のとおりです。
- GPU:NVIDIA A100 80GB
- GPUメモリ(VRAM):80GB
- OS :Ubuntu 22.04
- Docker
Dockerで環境構築
Dockerを使用してLangChainの環境構築をします
Dockerの使い方は以下の記事をご覧ください。

Ubuntuのコマンドラインで、Dockerfileを作成します。
mkdir rag_chat
cd rag_chat
nano DockerfileDockerfileに以下の記述を貼り付けます。
# ベースイメージ(CUDA)の指定
FROM nvidia/cuda:12.1.0-cudnn8-devel-ubuntu22.04
# 必要なパッケージをインストール
RUN apt-get update && apt-get install -y python3-pip python3-venv git nano curl
RUN curl -fsSL https://ollama.com/install.sh | sh
# 作業ディレクトリを設定
WORKDIR /app
# アプリケーションコードをコピー
COPY . /app
# Python仮想環境の作成
RUN python3 -m venv /app/.venv
# 仮想環境をアクティベートするコマンドを.bashrcに追加
RUN echo "source /app/.venv/bin/activate" >> /root/.bashrc
# JupyterLabのインストール
RUN /app/.venv/bin/pip install Jupyter jupyterlab
# LangChain関連のインストール
RUN /app/.venv/bin/pip install ollama langchain-ollama langchain langsmith langchain-chroma faiss-gpu langchain-community langchain_huggingface langchain_core tiktoken
# コンテナの起動時にbashを実行
CMD ["/bin/bash"]FROM nvidia/cuda:12.1.0-cudnn8-devel-ubuntu22.04
CUDA12.1のベースイメージを指定しています。
RUN apt-get update && apt-get install -y python3-pip python3-venv git nano curl
必要なパッケージをインストールしています。
RUN curl -fsSL https://ollama.com/install.sh | sh
Linux版のOllamaをインストールしています。PythonでOllamaを動かす際にもLinux版Ollamaのインストールが必要になりますのでご注意ください。
RUN /app/.venv/bin/pip install Jupyter jupyterlab
JupyterLabをインストールしています。
RUN /app/.venv/bin/pip install ollama langchain-ollama langchain langsmith langchain-chroma faiss-gpu langchain-community langchain_huggingface langchain_core tiktoken
LangChainとOllama関連のパッケージをインストールしています。
LLMはOllamaのライブラリを使って動かしますので、PyTorchやTransformerは別途インストール不要です。
docker-compose.ymlでDockerコンテナの設定をします。
docker-compose.ymlのYAMLファイルを作成して開きます。
nano docker-compose.yml以下のコードをコピーして、YAMLファイルに貼り付けます。
services:
rag_chat:
build:
context: .
dockerfile: Dockerfile
image: rag_chat
runtime: nvidia
container_name: rag_chat
ports:
- "8888:8888"
volumes:
- .:/app/rag_chat
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: 1
capabilities: [gpu]
command: >
bash -c '/usr/local/bin/ollama serve & /app/.venv/bin/jupyter lab --ip="*" --port=8888 --NotebookApp.token="" --NotebookApp.password="" --no-browser --allow-root'bash -c ‘/usr/local/bin/ollama serve & /app/.venv/bin/jupyter lab –ip=”*” –port=8888 –NotebookApp.token=”” –NotebookApp.password=”” –no-browser –allow-root’
bash -c '/usr/local/bin/ollama serve
Ollama Serverを起動しています。PythonのOllamaを使用する際に、Ollama Serverを起動しておく必要がありますので、ご注意ください。
& /app/.venv/bin/jupyter lab --ip="*" --port=8888 --NotebookApp.token="" --NotebookApp.password="" --no-browser --allow-root'
JupyterLabを8888番ポートで起動しています。
Dockerfileからビルドしてコンテナを起動します。
docker compose up
Dockerの起動後にブラウザの検索窓に”localhost:8888″を入力すると、Jupyter Labをブラウザで表示できます。
localhost:8888RAGチャットボットの実装

Dockerコンテナで起動したJupyter Lab上でRAGチャットボットの実装をします。
LangChainに関する環境変数を設定します。
import os
from uuid import uuid4
unique_id = uuid4().hex[0:8]
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_PROJECT"] = f"langchainchat - {unique_id}"
os.environ["LANGCHAIN_ENDPOINT"] = "https://api.smith.langchain.com"
os.environ["LANGCHAIN_API_KEY"] = "***************"unique_id = uuid4().hex[0:8]
8桁のランダムな一意の識別子unique_idを生成しています。
os.environ[“LANGCHAIN_TRACING_V2”] = “true”
この設定により、LangChainのトレースが可能になります。
os.environ[“LANGCHAIN_PROJECT”] = f”langchainchat – {unique_id}”
LangChainプロジェクトの名前を設定しています。ここでは、生成したunique_idを使用してプロジェクト名を「langchainchat – {unique_id}」の形式で一意にしています。
os.environ[“LANGCHAIN_ENDPOINT”] = “https://api.smith.langchain.com”
LangChainのAPIエンドポイントを指定しています。
os.environ[“LANGCHAIN_API_KEY”] = “***************”
LangChain APIを利用するためのAPIキーを設定しています。
日本語LLMモデル「Llama-3-ELYZA-JP-8B-q4_k_m.gguf」をダウンロードします。
!curl -L -o Llama-3-ELYZA-JP-8B-q4_k_m.gguf "https://huggingface.co/elyza/Llama-3-ELYZA-JP-8B-GGUF/resolve/main/Llama-3-ELYZA-JP-8B-q4_k_m.gguf?download=true"Llama-3-ELYZA-JPについては、別記事で詳しく解説しています。

LLMの実行にはOllamaを使用します。
LLMのモデルがOllama使えるようにプロンプトテンプレートを指定して、モデルを作成します。
import ollama
from langchain_ollama.chat_models import ChatOllama
modelfile='''
FROM ./Llama-3-ELYZA-JP-8B-q4_k_m.gguf
TEMPLATE """{{ if .System }}<|start_header_id|>system<|end_header_id|>
{{ .System }}<|eot_id|>{{ end }}{{ if .Prompt }}<|start_header_id|>user<|end_header_id|>
{{ .Prompt }}<|eot_id|>{{ end }}<|start_header_id|>assistant<|end_header_id|>
{{ .Response }}<|eot_id|>"""
PARAMETER stop "<|start_header_id|>"
PARAMETER stop "<|end_header_id|>"
PARAMETER stop "<|eot_id|>"
PARAMETER stop "<|reserved_special_token"
'''
ollama.create(model='elyza8b', modelfile=modelfile)
llm = ChatOllama(model="elyza8b", temperature=0)
llm.invoke(("human","弱虫ペダルを知っていますか?")).contentFROM ./Llama-3-ELYZA-JP-8B-q4_k_m.gguf
ダウンロードしたモデルのパスが入ります。
TEMPLATE “””{{ if .System }}<|start_header_id|>system<|end_header_id|>…
モデルで使用するプロンプトテンプレートが入ります。
ollama.create(model=’elyza8b’, modelfile=modelfile)
モデルとプロンプトテンプレートを使ってOllama用のモデルを作成します。modelにはOllamaで呼び出す際に使用する名前をつけられます。
ChatOllama(model=”elyza8b”, temperature=0)
ChatOllamaをインスタンス化してLLMモデルを実行できる状態にしています。
確認のため、LLMからテキストを生成しています。
'弱虫ペダルは、人気の日本の漫画作品です。2008年から連載が始まり、2013年にTVアニメ化もされました。\n\nストーリーは、自転車競技に打ち込む高校生たちの青春物語で、主人公の小野田坂道が、インターハイ出場を目指して努力し成長する姿を描いています。タイトルの「弱虫ペダル」は、主人公の自転車競技に対する初心者ぶりや臆病な性格を表しています。\n\n作品の特徴として、自転車競技の世界を舞台にしたことで、実際の自転車レースの描写や用語が多く登場し、ファンからも好評です。また、キャラクターの個性や友情、ライバル関係などが丁寧に描かれ、読者・視聴者の心を掴んでいます。'ollama.createのエラー「invalid digest format」の解消方法

Ollamaの詳しい使い方は、別の記事で解説しています。

Wikipediaからテキストデータを抽出して、読み込みます。
Wikipediaの『弱虫ペダル』のページからテキストを抽出しています。
from langchain_community.document_loaders import WebBaseLoader
urls = [
"https://ja.wikipedia.org/wiki/%E5%BC%B1%E8%99%AB%E3%83%9A%E3%83%80%E3%83%AB",
]
docs = [WebBaseLoader(url).load() for url in urls]
docs_list = [item for sublist in docs for item in sublist]WebBaseLoader(url).load()
指定したWebページのHTMLコンテンツを取得し、HTMLコンテンツを解析し、使いやすいデータ構造に変換し、そのデータを読み込みます。
読み込んだデータをチャンクに分割します。
データベースの検索精度の向上や効率的な処理のためにチャンク分割が必要になります。
from langchain.text_splitter import CharacterTextSplitter
text_splitter = CharacterTextSplitter.from_tiktoken_encoder(
separator = "\n",
chunk_size= 500,
chunk_overlap=50,
)
doc_splits = text_splitter.split_documents(docs_list)
doc_splits[10:13]CharacterTextSplitter.from_tiktoken_encoder…
テキストを指定された条件でチャンクに分割しています。
separator = “\n”
チャンクを分割する際の区切り文字を「\n」として指定します。
chunk_size= 500
各チャンクが500文字を超えないように分割されます。
chunk_overlap=50
各チャンクが50文字分重複するように設定しています。
確認のため、分割したチャンクを3つ表示しています。
[Document(metadata={'source': 'https://ja.wikipedia.org/wiki/%E5%BC%B1%E8%99%AB%E3%83%9A%E3%83%80%E3%83%AB', 'title': '弱虫ペダル - Wikipedia', 'language': 'ja'}, page_content='本作のほかに、小野田が1年次の3年生に焦点を当てた『弱虫ペダル SPARE BIKE』が『週刊少年チャンピオン』の2012年38号から2013年6号まで連載されたのち、『別冊少年チャンピオン』(同社刊)に移籍し2014年9月号から連載中。『SPARE BIKE』は4コマ漫画のような軽いノリで連載する予定がだんだん本気になってしまったことを明かしている[注釈 2]。\n2012年に舞台化、2013年にはテレビアニメが放送、2015年には劇場版アニメが公開されたほか、2016年にはテレビドラマが放送、2020年には実写映画化されるなど、様々なメディアミックス展開が行われている。'),
Document(metadata={'source': 'https://ja.wikipedia.org/wiki/%E5%BC%B1%E8%99%AB%E3%83%9A%E3%83%80%E3%83%AB', 'title': '弱虫ペダル - Wikipedia', 'language': 'ja'}, page_content='2015年第39回講談社漫画賞・少年部門受賞。『週刊少年チャンピオン』連載の作品のみならず、秋田書店の作品が同賞を受賞するのは第1回(1977年)に受賞した『ブラック・ジャック』以来39年ぶりとなる[注釈 3]。\nあらすじ\nこの節にあるあらすじは作品内容に比して不十分です。 あらすじの書き方を参考にして、物語全体の流れが理解できるように(ネタバレも含めて)、著作権を侵害しないようご自身の言葉で加筆を行なってください。(2013年8月)(使い方)'),
Document(metadata={'source': 'https://ja.wikipedia.org/wiki/%E5%BC%B1%E8%99%AB%E3%83%9A%E3%83%80%E3%83%AB', 'title': '弱虫ペダル - Wikipedia', 'language': 'ja'}, page_content='千葉県立総北高等学校の新入生小野田坂道はアニメやゲーム、漫画や秋葉原を愛するオタク少年。中学時代にオタクの友達ができなかった彼は、高校こそは友達を作るためアニメ・漫画研究部に入ろうとするが、部員が足りず、活動休止中であると知り、活動再開に必要な部員数を集めようと思い立つものの、部員は集まらなかった[5]。')]テキストをベクトル表現に変換する埋め込みモデルを読み込みます。
日本語性能が高く、無料で使える埋め込みモデル「intfloat/multilingual-e5-large」を指定しています。
from langchain_huggingface import HuggingFaceEmbeddings
embedding = HuggingFaceEmbeddings(model_name="intfloat/multilingual-e5-large")Retrieverは、クエリをもとにベクトルデータベースから関連情報を検索・取得する機能です。
Retrieverの実装には、GPUを活用した高速ベクトル検索が可能な「FAISS」ライブラリを使用しています。
from langchain.vectorstores import FAISS
vectorstore = FAISS.from_documents(doc_splits, embedding)
retriever = vectorstore.as_retriever(search_type="similarity", search_kwargs={"k": 5})
question = "坂道とは?"
retriever.invoke(question)FAISS.from_documents(splits, embedding)
ベクトル検索用のインデックスを作成しています。インデックスはDBのテーブルのような概念です。
vector.as_retriever()
インデックスからRetriverを作成しています。
search_type=”similarity”
質問の類似度にもとづいて検索する指定です。
search_kwargs={“k”: 5}
検索結果として上位5件の類似ドキュメントを返す設定です。
retriever.invoke()
クエリをRetrieverに渡し、類似したドキュメントを検索します。
「坂道とは?」というクエリに対して、Retrieverが返した結果
[Document(metadata={'source': 'https://ja.wikipedia.org/wiki/%E5%BC%B1%E8%99%AB%E3%83%9A%E3%83%80%E3%83%AB', 'title': '弱虫ペダル - Wikipedia', 'language': 'ja'}, page_content='2人との出会いで今まで経験したことのなかった“自転車で速く走る楽しみ”を見出した坂道は、アニ研の部員集めを諦め、自転車競技部に入部する。小学生のときから自転車で秋葉原に通い続けていた坂道は、知らず知らずのうちにクライマーとしての基礎能力が鍛えられており、その資質を見出されたことから、先輩部員でクライマーの巻島裕介の指導を受けることになり、才能を開花させていく。\n登場人物\n車両メーカーの名称は劇場版を含むアニメ版では変更されているためその都度併記する。ただし一度併記したメーカーは以降は省略する。同じ人物が原作版とアニメ版でメーカーが異なる車両に乗っていたり、アニメ版のみしか車両の名称が記載されていない場合は本来のメーカー名で記載する。'),
Document(metadata={'source': 'https://ja.wikipedia.org/wiki/%E5%BC%B1%E8%99%AB%E3%83%9A%E3%83%80%E3%83%AB', 'title': '弱虫ペダル - Wikipedia', 'language': 'ja'}, page_content='坂道達が2年生に進級時の箱根学園のインタビューの段階で登場はしていたが、その時はキャラクターもののお面をつけていて、その正体は2回目のインターハイが始まるまで明かされないままであった[注釈 45]。兄と同じく厚い唇とタレ目が特徴。補給食をよく口にしている点も同じである。本人曰く、少女願望があるらしいがその発言の真相は不明。「頂上のスズメ蜂(ピーク・ホーネット)」のあだ名を持ち、「答えはYesですか?」が口癖。\n入部当初は「新開(隼人)の弟」と言われることにコンプレックスを持ち部に馴染めなったが、葦木場との勝負に負けてからは葦木場を慕い部に馴染むようになった。'),
Document(metadata={'source': 'https://ja.wikipedia.org/wiki/%E5%BC%B1%E8%99%AB%E3%83%9A%E3%83%80%E3%83%AB', 'title': '弱虫ペダル - Wikipedia', 'language': 'ja'}, page_content='そんなとき坂道は、同級生の今泉俊輔から自転車レースを挑まれる。中学時代に自転車競技で活躍していた今泉にとって、学校裏の斜度20%以上の激坂をママチャリで、歌いながら登坂する坂道は“信じがたい光景”であった。「坂道が勝てばアニ研に入っても良い」と今泉に言われ、勝負を受けた坂道だが、あと一歩のところで惜敗する。それから数日後、坂道は関西から引っ越してきたばかりの少年鳴子章吉と友人になる。鳴子は中学時代に自転車競技で活躍しており、ひょんなことから坂道はその実力を知ることになる。'),以下省略会話履歴を考慮して回答を生成するRAG Chainの構築

会話履歴を考慮して回答を生成するRAG Chainを構築していきます。
会話履歴を参照して質問を再構成し、情報を検索するためのRetriever Chainを構築します。
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain.chains import create_history_aware_retriever, create_retrieval_chain
contextualize_q_system_prompt = (
"""
会話履歴と質問が与えられば場合、質問が会話履歴と関連している可能性があります。
その質問を過去の会話履歴がなくても、理解できるような独立した質問に再構成してください。
必要であれば質問を再構成して、再構成する必要がなければ、そのまま質問を返してください。
"""
)
contextualize_q_prompt = ChatPromptTemplate.from_messages(
[
("system", contextualize_q_system_prompt),
MessagesPlaceholder("chat_history"),
("human", "{input}"),
]
)
history_aware_retriever = create_history_aware_retriever(
llm, retriever, contextualize_q_prompt
)ChatPromptTemplate.from_messages
与えられたメッセージのリストをもとにチャットプロンプトを生成します。このプロンプトは、チャット履歴 "chat_history"と現在のユーザーの質問 "{input}" をシステムプロンプト contextualize_q_system_promptに従って処理し、質問を適切に再構成するために使用します。
create_history_aware_retriever
llmとretrieverを使い、チャット履歴を考慮して質問を再構成するプロンプトcontextualize_q_promptを利用して、履歴に依存しない形で質問を処理・検索するRetrieverを作成します。
取得したコンテキストにもとづいて、回答を生成するためのChainを作成しています。
from langchain.chains import create_retrieval_chain
from langchain.chains.combine_documents import create_stuff_documents_chain
system_prompt = (
"""
あなたは質問応答タスクのためのアシスタントです。
取得したコンテキストを使用して質問に答えてください。
答えがわからない場合は、わからないと伝えてください。
コンテキスト:{context}
"""
)
qa_prompt = ChatPromptTemplate.from_messages(
[
("system", system_prompt),
MessagesPlaceholder("chat_history"),
("human", "{input}"),
]
)
question_answer_chain = create_stuff_documents_chain(
llm,
qa_prompt
)system_prompt=()
システムプロンプトを作成しています。{context} はプレースホルダーで、実際のコンテキスト情報がここに挿入されます。
ChatPromptTemplate.from_messages()
システムプロンプトsystem_prompt、チャット履歴MessagesPlaceholder("chat_history")、そしてユーザーの質問{input}を組み合わせたプロンプトテンプレートを生成します。
create_stuff_documents_chain()
llm と qa_prompt を使って、質問に対する回答を生成するための処理チェーンを作成します。
質問を再構成するRetriever Chainと回答を生成するChainを組み合わせたRAG Chainを構築します。
from langchain.chains import create_retrieval_chain
rag_chain = create_retrieval_chain(
history_aware_retriever,
question_answer_chain
)create_retrieval_chain()
履歴に基づいて質問を再構成するRetrieverhistory_aware_retrieverと回答を生成するChainquestion_answer_chainを統合して、rag_chainを作成します。
セッション単位で会話履歴を参照して、回答を生成するRAG Chainを構築します。
from langchain_community.chat_message_histories import ChatMessageHistory
from langchain_core.chat_history import BaseChatMessageHistory
from langchain_core.runnables.history import RunnableWithMessageHistory
store = {}
def get_session_history(session_id: str) -> BaseChatMessageHistory:
if session_id not in store:
store[session_id] = ChatMessageHistory()
return store[session_id]
conversational_rag_chain = RunnableWithMessageHistory(
rag_chain,
get_session_history,
input_messages_key="input",
history_messages_key="chat_history",
output_messages_key="answer",
)get_session_history()
指定された session_id が store に存在しない場合、新しい ChatMessageHistory オブジェクトを作成し、それを store に追加します。既存の session_id の場合は、そのセッションに対応する履歴を返します。
RunnableWithMessageHistory()
チャット履歴を管理しながら、 rag_chainを実行するためのクラスです。
rag_chain:Retrieverと質問回答を統合するチェーンです。
get_session_history: セッションごとのチャット履歴を取得するための関数です。
input_messages_key="input": ユーザーからの質問がこのキーにもとづいて渡されます。
history_messages_key="chat_history": 過去のメッセージ履歴がこのキーを通じて渡されます。
output_messages_key="answer": 生成された回答がこのキーにもとづいて保存されます。
RAGチャットボットに『弱ペダ』について聞いてみる

RAGチャットボットを使って、『弱虫ペダル』について質問してみます。
import uuid
session_id = str(uuid.uuid4())
conversational_rag_chain.invoke(
{"input": "坂道について教えて下さい。"},
config={
"configurable": {"session_id": session_id}
}, # constructs a key "abc123" in `store`.
)["answer"]坂道について教えて下さい。
‘坂道は小学生の時から自転車で秋葉原に通い続けており、知らず知らずのうちにクライマーとしての基礎能力が鍛えられていました。アニ研の部員集めを諦め、自転車競技部に入部し、先輩部員である巻島裕介の指導を受けることになります。’
str(uuid.uuid4())
uuid.uuid4() を使用して一意のセッションIDを生成し、文字列として session_id に保存しています。これにより、各セッションごとに異なるIDが付与されます。
conversational_rag_chain.invoke
質問をRAG Chainに送信しています。"input": "坂道について教えて下さい。" は、ユーザーからの質問を表しています。config パラメータ内で、session_id を指定してセッションごとのチャット履歴を管理します。これにより、このセッションに関連する履歴が保存され、次回以降のやり取りで再利用されます。最終的に、["answer"] を使って、生成された回答を取得しています。
conversational_rag_chain.invoke(
{"input": "彼の学校はどこですか?"},
config={
"configurable": {"session_id": session_id}
},
)["answer"]彼の学校はどこですか?
‘小野田坂道の学校は千葉県立総北高等学校です。’
conversational_rag_chain.invoke(
{"input": "それはどこにありますか?"},
config={
"configurable": {"session_id": session_id}
},
)["answer"]それはどこにありますか?
‘千葉県佐倉市にあります。’
生成AI・LLMのコストでお困りなら
GPUのスペック不足で生成AIの開発が思うように進まないことはありませんか?
そんなときには、高性能なGPUをリーズナブルな価格で使えるGPUクラウドサービスがおすすめです!

GPUSOROBANは、生成AI・LLM向けの高速GPUを業界最安級の料金で使用することができます。
インターネット環境さえあれば、クラウド環境のGPUサーバーをすぐに利用可能です。
大規模な設備投資の必要がなく、煩雑なサーバー管理からも解放されます。







