
CyberAgentLM3は、サイバーエージェントが開発した225億パラメータの日本語に特化したLLMです。
日本語のLLMにおいてトップクラスの性能を持ち、商用利用が可能です。
この記事では、CyberAgentLM3の性能から商用利用、使い方までを紹介します。

CyberAgentLM3とは

CyberAgentLM3は、サイバーエージェントが開発した225億パラメータの日本語に特化したLLMです。
2024年7月時点で、日本語のLLMにおいてトップクラスの性能を持ち、Meta社の「Meta-Llama-3-70B-Instruct」と同等の性能を示しています。
CyberAgentLM3は商用利用が可能で、Apache License 2.0で提供されています。
ざっくり言うと
- CyberAgentLM3は、サイバーエージェントが開発した日本語LLM
- 日本語LLMでトップクラスで、Meta社の「Meta-Llama-3-70B-Instruct」と同等の性能
- 商用利用が可能でApache License 2.0で提供

CyberAgentLM3のモデル

CyberAgentLM3は、225億パラメータをもつモデルになります。
既に指示チューニングが施されているモデルになるため、人間による指示に対してChatGPTのような応答が可能です。
| モデルID | パラメータサイズ | 指示チューニング | 公開 |
|---|---|---|---|
| cyberagent/calm3-22b-chat | 225億パラメータ | 済み | HuggingFace |
CyberAgentLM3の性能

CyberAgentLM3の性能は、日本語能力を評価する「Nejumi LLM リーダーボード3」においてベンチマーク結果が公表されています。
以下の図は、Nejumi リーダーボード3におけるベンチマーク結果を示しており、各タスクの平均スコアをモデルごとに比較したグラフです。
CyberAgentLM3(calm3-22b-chat)は、700億パラメータを持つMeta社の「Meta-Llama-3-70B-Instruct」と同等の性能を示していることが分かります。
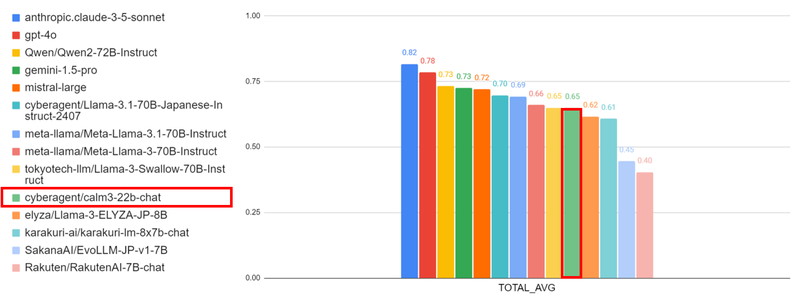
Nejumi リーダーボード3
Nejumi リーダーボードは、LLMの日本語能力を評価するために、言語理解能力、応用能力、アライメントといった複数の観点からモデルを評価します。
翻訳、要約、情報抽出、推論、知識・質問応答、倫理、バイアス、真実性などの様々なタスクに対する能力が測定されます
CyberAgentLM3の商用利用・ライセンス

CyberAgentLM3は商用利用が可能で、Apache License 2.0で提供されています。
Hugging Face上でモデルが公開されており、誰でもアクセスして利用することができます。
商用利用:ソフトウェアやコードを商用利用することが許可されています。
改変:ソフトウェアやコードを自由に修正したり改変したりすることができます。
配布:修正したり変更したりしたソフトウェアを自由に配布することができます。
著作権表示:元の著作権表示とライセンス条項を含める必要があります。
特許利用:利用者に特許使用権が付与されています。
詳細は「Apache License」のページをご確認ください。
CyberAgentLM3(calm3-22b-chat)の使い方

ここからCyberAgentLM3(calm3-22b-chat)の使い方について解説していきます。
実行環境
この記事で用意した実行環境は以下のとおりです。
- GPU:NVIDIA A100 80GB
- GPUメモリ(VRAM):80GB
- OS :Ubuntu 22.04
- Docker
Dockerで環境構築
Dockerを使用してCyberAgentLM3の環境構築をします
Dockerの使い方は以下の記事をご覧ください。

コンテナにインストールするパッケージは以下のとおりです。
CUDA、PyTorch、Transformersはバージョン依存関係によるエラーが起きやすいので、動作検証済のバージョン指定してインストールしています。
- CUDA:12.1
- Python:3.10
- PyTorch:2.2.2
- transformers:4.41.2
- accelerate
Ubuntuのコマンドラインで、Dockerfileを作成します。
mkdir calm3_inference
cd calm3_inference
nano DockerfileDockerfileに以下の記述を貼り付けます。
# ベースイメージ(CUDA)の指定
FROM nvidia/cuda:12.1.0-cudnn8-devel-ubuntu22.04
# 必要なパッケージをインストール
RUN apt-get update && apt-get install -y python3-pip python3-venv git nano
# 作業ディレクトリを設定
WORKDIR /app
# アプリケーションコードをコピー
COPY . /app
# Python仮想環境の作成
RUN python3 -m venv /app/.venv
# 仮想環境をアクティベートするコマンドを.bashrcに追加
RUN echo "source /app/.venv/bin/activate" >> /root/.bashrc
# JupyterLabのインストール
RUN /app/.venv/bin/pip install Jupyter jupyterlab
# PyTorchのインストール
RUN /app/.venv/bin/pip install torch==2.2.2 torchvision==0.17.2 torchaudio==2.2.2 --index-url https://download.pytorch.org/whl/cu121
# Transformer関連のインストール
RUN /app/.venv/bin/pip install transformers==4.41.2 accelerate bitsandbytes
# コンテナの起動時にbashを実行
CMD ["/bin/bash"]docker-compose.ymlでDockerコンテナの設定をします。
docker-compose.ymlのYAMLファイルを作成して開きます。
nano docker-compose.yml以下のコードをコピーして、YAMLファイルに貼り付けます。
services:
calm3_inference:
build:
context: .
dockerfile: Dockerfile
image: calm3_inference
runtime: nvidia
container_name: calm3_inference
ports:
- "8888:8888"
volumes:
- .:/app/calm3_inference
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: 1
capabilities: [gpu]
command: >
bash -c '/app/.venv/bin/jupyter lab --ip="*" --port=8888 --NotebookApp.token="" --NotebookApp.password="" --no-browser --allow-root'Dockerfileからビルドしてコンテナを起動します。
docker compose up
Dockerの起動後にブラウザの検索窓に”localhost:8888″を入力すると、Jupyter Labをブラウザで表示できます。
localhost:8888CyberAgentLM3(calm3-22b-chat)の実装
Dockerコンテナで起動したJupyter Lab上でcalm3-22b-chatの実装をします。
Jupyter Labのコードセルに次のコマンドを実行して、ライブラリをインポートします。
import torch
import transformers
from transformers import AutoModelForCausalLM, AutoTokenizer, TextStreamercalm3-22b-chatのモデルとトークナイザーを読み込みます。
model_id = "cyberagent/calm3-22b-chat"
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype="auto",
device_map="auto",
)
tokenizer = AutoTokenizer.from_pretrained(model_id)
streamer = TextStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True)“cyberagent/calm3-22b-chat” : モデルのタイプを指定しています。
AutoModelForCausalLM.from_pretrained():モデルを読み込みます。
AutoTokenizer.from_pretrained():トークナイザーを読み込みます。
| モデルID | パラメータサイズ | 量子化 | GPUメモリ使用量 |
| cyberagent/calm3-22b-chat | 225億パラメータ | なし | 45GB |
CyberAgentLM3(calm3-22b-chat)でテキスト生成

CyberAgentLM3(calm3-22b-chat)を使って、日本語での質問応答を試してみます。
日本語での質問応答(1)
「炭酸水のキャッチコピーを10個教えて下さい。」というプロンプトを日本語で実行してみます。
DEFAULT_SYSTEM_PROMPT = "あなたは日本語で回答するアシスタントです。"
text = "炭酸水のキャッチコピーを10個教えて下さい。"
messages = [
{"role": "system", "content": DEFAULT_SYSTEM_PROMPT},
{"role": "user", "content": text},
]
input_ids = tokenizer.apply_chat_template(
messages,
add_generation_prompt=True,
return_tensors="pt",
).to(model.device)
output_ids = model.generate(
input_ids,
max_new_tokens=512,
do_sample=True,
temperature=0.6,
top_p=0.9,
streamer=streamer,
)炭酸水のキャッチコピーを10個教えて下さい。
もちろんです。以下に炭酸水のキャッチコピーを10個ご紹介します。
「シュワッと爽快、一口でリフレッシュ」
「炭酸の泡で広がる、新しい爽快感」
「のどごし爽やか、フレッシュなひととき」
「毎日のリフレッシュ、炭酸水で手軽に」
「弾ける泡が、心と体をリフレッシュ」
「クリアな爽快感、炭酸水の新習慣」
「自然の恵み、爽快な炭酸水」
「一口飲めば、夏が始まる」
「炭酸の力で、元気をチャージ」
「炭酸水、飲むたびに感じる爽快感」
これらのキャッチコピーは、炭酸水の爽快さやリフレッシュ効果を強調しています。
日本語での質問応答(2)
「広告のクリエイティブにおいて要点を教えて下さい。」というプロンプトを日本語で実行してみます。
DEFAULT_SYSTEM_PROMPT = "あなたは日本語で回答するアシスタントです。"
text = "広告のクリエイティブにおいて要点を教えて下さい。"
messages = [
{"role": "system", "content": DEFAULT_SYSTEM_PROMPT},
{"role": "user", "content": text},
]
input_ids = tokenizer.apply_chat_template(
messages,
add_generation_prompt=True,
return_tensors="pt",
).to(model.device)
output_ids = model.generate(
input_ids,
max_new_tokens=512,
do_sample=True,
temperature=0.6,
top_p=0.9,
streamer=streamer,
)広告のクリエイティブにおいて要点を教えて下さい。
広告のクリエイティブにおいて重要な要点はいくつかあります。
以下に主要なポイントをまとめます。
1. ターゲットオーディエンスの理解:
– 広告は誰に向けて作られているのかを明確にすることが重要です。年齢、性別、興味、行動パターンなど、ターゲットオーディエンスの特性を深く理解することが必要です。
2. メッセージの一貫性:
– 広告が伝えたいメッセージが明確で一貫していることが重要です。主要なメッセージを一つに絞り、それを強調することで、視聴者にとって分かりやすく、記憶に残りやすくなります。
3. ビジュアルとデザイン:
– 視覚的な要素は広告の印象を大きく左右します。色彩、レイアウト、フォント、画像などの視覚的要素を効果的に使い、ブランドイメージやメッセージを強調することが求められます。
4. 感情に訴える:
– 視聴者に感情的な反応を引き起こすことが重要です。感動、喜び、驚き、共感など、視聴者が感じる感情を引き出すことが、広告の効果を高めます。
5. 簡潔さと明確さ:
– メッセージやビジュアルが簡潔で明確であることが重要です。複雑な内容や過剰な情報は避け、視聴者が一目で理解できるようにすることが求められます。
6. ブランドの一貫性:
– 広告がブランドの一貫性を保っていることが重要です。ブランドのトーン、スタイル、価値観が広告に反映されていることで、視聴者はブランドに対する信頼感を持ちやすくなります。
7. 行動喚起(Call to Action, CTA):
– 広告が視聴者に対して具体的な行動を促すものであることが重要です。購入、問い合わせ、ウェブサイトへの訪問など、具体的なアクションを明確に示すことが求められます。
8. パフォーマンスの測定と改善:
– 広告の効果を測定し、データに基づいて改善を続けることが重要です。クリック率、コンバージョン率、エンゲージメントなどのKPIを設定し、定期的に評価・改善を行います。
これらの要点を意識することで、効果的な広告クリエイティブを作成することができます。
コードの質問応答
「PyTorchでデータローダを実装する方法を教えて下さい。」というプロンプトを日本語で実行してみます。
DEFAULT_SYSTEM_PROMPT = "あなたは日本語で回答するアシスタントです。"
text = "Pytorchでデータローダを実装する方法を教えて下さい。"
messages = [
{"role": "system", "content": DEFAULT_SYSTEM_PROMPT},
{"role": "user", "content": text},
]
input_ids = tokenizer.apply_chat_template(
messages,
add_generation_prompt=True,
return_tensors="pt",
).to(model.device)
output_ids = model.generate(
input_ids,
max_new_tokens=512,
do_sample=True,
temperature=0.6,
top_p=0.9,
streamer=streamer,
)PyTorchでデータローダを実装する方法を教えて下さい。
PyTorchでデータローダを実装する方法について説明します。データローダは、データをバッチ単位で効率的に読み込むためのクラスで、`torch.utils.data.DataLoader`を使用します。以下に、基本的なデータローダの実装手順を示します。
1. データセットの準備:
まず、データセットを準備します。これは、`torch.utils.data.Dataset`クラスを継承したカスタムクラスとして定義することが一般的です。このクラスは、`__len__`メソッドと`__getitem__`メソッドを実装する必要があります。
```python
import torch
class MyDataset(torch.utils.data.Dataset):
def __init__(self, data, labels):
self.data = data
self.labels = labels
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
sample = self.data[idx]
label = self.labels[idx]
return sample, label
```
2. データとラベルの準備:
次に、データとラベルを準備します。ここでは、例としてランダムなデータとラベルを生成しますが、実際のデータセットに応じて適宜変更してください。
```python
import numpy as np
# ランダムなデータとラベルを生成
data = np.random.randn(100, 3) # 100サンプル、3次元のランダムなデータ
labels = np.random.randint(0, 2, 100) # 0または1のランダムなラベル
```
3. データローダの作成:
準備したデータセットとデータローダの引数(バッチサイズ、シャッフル、デバイスなど)を指定して、`DataLoader`を作成します。
```python
batch_size = 16
shuffle = True
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
dataset = MyDataset(data, labels)
dataloader = torch.utils.data.DataLoader(dataset, batch_size=batch_size, shuffle=shuffle, num_workers=2, pin_memory=True)
```
4. データローダの使用:
データローダを使用してデータをバッチごとに取得し、モデルに入力します。
```python
for batch_data, batch_labels in dataloader:
batch_data, batch_labels = batch_data生成AI・LLMのコストでお困りなら
GPUのスペック不足で生成AIの開発が思うように進まないことはありませんか?
そんなときには、高性能なGPUをリーズナブルな価格で使えるGPUクラウドサービスがおすすめです!

GPUSOROBANは、生成AI・LLM向けの高速GPUを業界最安級の料金で使用することができます。
インターネット環境さえあれば、クラウド環境のGPUサーバーをすぐに利用可能です。
大規模な設備投資の必要がなく、煩雑なサーバー管理からも解放されます。







