
Gemma 2は、Googleが開発した軽量かつ高性能なオープンソースLLMです。
20億、90億、270億パラメータのモデルが公開され、Gemma2 27Bはパラメータが2倍以上の他モデルに匹敵する性能があります。
この記事では、Gemma2 の性能から商用利用、使い方までを紹介します。

Gemma2とは

Gemma 2は、Googleが開発した軽量かつ高性能なオープンソースLLMです。
20億、90億、270億パラメータのモデルが公開され、Gemma2 27Bはパラメータが2倍以上の他モデルに匹敵する性能があります。
Gemma2はApache License 2.0のもと無料で利用でき商用利用が可能です。
ざっくり言うと
- Gemma 2は、Googleが開発した軽量かつ高性能なLLM
- Gemma2 27Bはパラメータサイズが2倍以上の他モデルに匹敵
- 商用利用が可能でApache License 2.0で提供

Gemma2のモデル

Gemma2は、20億・90億・270億パラメータのモデルをHuggingFaceで公開しています。
既に指示チューニングが施されているモデルになるため、人間による指示に対してChatGPTのような応答が可能です。
| モデルID | パラメータサイズ | 事前学習/指示学習 |
|---|---|---|
| google/gemma-2-2b | 20億パラメータ | 事前学習モデル |
| google/gemma-2-2b-it | 20億パラメータ | 指示学習モデル |
| google/gemma-2-9b | 90億パラメータ | 事前学習モデル |
| google/gemma-2-9b-it | 90億パラメータ | 指示学習モデル |
| google/gemma-2-27b | 270億パラメータ | 事前学習モデル |
| google/gemma-2-27b-it | 270億パラメータ | 指示学習モデル |
事前学習モデル
基礎的なデータが学習されたモデルです。基礎的な知識はありますが、人間の指示に応じた回答ができません。
指示学習モデル
事前学習モデルを特定のタスクや指示にもとづいて調整したモデルです。ChatGPTのように人間の指示に応じた回答が可能です。
Gemma2の性能

Gemma 2は主要なベンチマークで高い性能を発揮しています。
- Gemma2 27Bはパラメータが2倍以上のモデルに匹敵する結果を出しています。
- Gemma2 9BはLlama3 8Bを上回る結果を示しています。
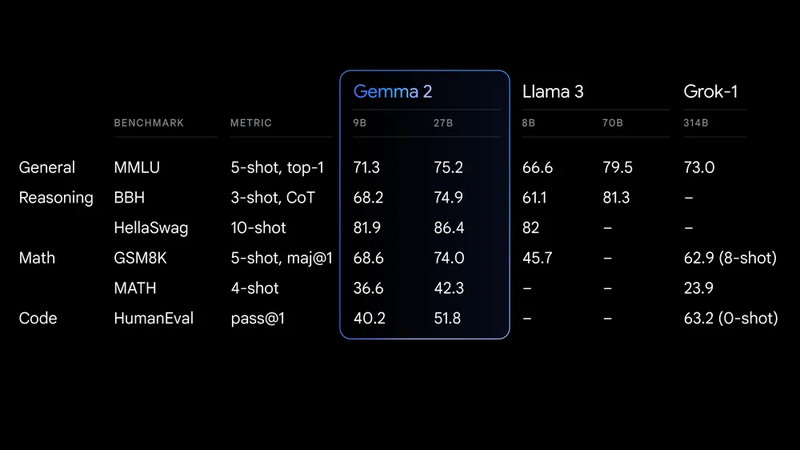
一般タスク (MMLU): 多岐にわたる学問的なタスクに対する理解力を測定
推論タスク (BBH, HellaSwag): 複雑な推論や文脈予測能力を評価
数学タスク (GSM8K, MATH): 数学的推論や問題解決能力をテスト
コード生成タスク (HumanEval): プログラムコードの生成能力を評価
Gemma2の商用利用・ライセンス

Gemma2は商用利用が可能で、Gemmaライセンス(Apache License 2.0)で提供されています。
Hugging Face上でモデルが公開されており、誰でもアクセスして利用することができます。
商用利用:ソフトウェアやコードを商用利用することが許可されています。
改変:ソフトウェアやコードを自由に修正したり改変したりすることができます。
配布:修正したり変更したりしたソフトウェアを自由に配布することができます。
著作権表示:元の著作権表示とライセンス条項を含める必要があります。
特許利用:利用者に特許使用権が付与されています。
詳細はGemmaライセンスのページをご確認ください。
Gemma2の使い方

ここからGemma2の使い方について解説していきます。
実行環境
この記事で用意した実行環境は以下のとおりです。
- GPU:NVIDIA A100 80GB
- GPUメモリ(VRAM):80GB
- OS :Ubuntu 22.04
- Docker
Dockerで環境構築
Dockerを使用してGemma2の環境構築をします
Dockerの使い方は以下の記事をご覧ください。

コンテナにインストールするパッケージは以下のとおりです。
CUDA、PyTorch、Transformersはバージョン依存関係によるエラーが起きやすいので、動作検証済のバージョン指定してインストールしています。
- CUDA:12.1
- Python:3.10
- PyTorch:2.2.2
- transformers:4.44.0
- accelerate
Ubuntuのコマンドラインで、Dockerfileを作成します。
mkdir gemma2_inference
cd gemma2_inference
nano DockerfileDockerfileに以下の記述を貼り付けます。
# ベースイメージ(CUDA)の指定
FROM nvidia/cuda:12.1.0-cudnn8-devel-ubuntu22.04
# 必要なパッケージをインストール
RUN apt-get update && apt-get install -y python3-pip python3-venv git nano
# 作業ディレクトリを設定
WORKDIR /app
# アプリケーションコードをコピー
COPY . /app
# Python仮想環境の作成
RUN python3 -m venv /app/.venv
# 仮想環境をアクティベートするコマンドを.bashrcに追加
RUN echo "source /app/.venv/bin/activate" >> /root/.bashrc
# JupyterLabのインストール
RUN /app/.venv/bin/pip install Jupyter jupyterlab
# PyTorchのインストール
RUN /app/.venv/bin/pip install torch==2.2.2 torchvision==0.17.2 torchaudio==2.2.2 --index-url https://download.pytorch.org/whl/cu121
# Transformer関連のインストール
RUN /app/.venv/bin/pip install transformers==4.44.0 accelerate bitsandbytes
# コンテナの起動時にbashを実行
CMD ["/bin/bash"]docker-compose.ymlでDockerコンテナの設定をします。
docker-compose.ymlのYAMLファイルを作成して開きます。
nano docker-compose.yml以下のコードをコピーして、YAMLファイルに貼り付けます。
services:
gemma2_inference:
build:
context: .
dockerfile: Dockerfile
image: gemma2_inference
runtime: nvidia
container_name: gemma2_inference
ports:
- "8888:8888"
volumes:
- .:/app/gemma2_inference
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: 1
capabilities: [gpu]
command: >
bash -c '/app/.venv/bin/jupyter lab --ip="*" --port=8888 --NotebookApp.token="" --NotebookApp.password="" --no-browser --allow-root'Dockerfileからビルドしてコンテナを起動します。
docker compose up
Dockerの起動後にブラウザの検索窓に”localhost:8888″を入力すると、Jupyter Labをブラウザで表示できます。
localhost:8888Gemma2の実装
Dockerコンテナで起動したJupyter Lab上でGemma2の実装をします。
Jupyter Labのコードセルに次のコマンドを実行して、ライブラリをインポートします。
import torch
import transformers
from transformers import AutoModelForCausalLM, AutoTokenizer,BitsAndBytesConfigGemma2のモデルとトークナイザーを読み込みます。
model_id = "google/gemma-2-27b-it"
token = "******************************"
model = AutoModelForCausalLM.from_pretrained(
model_id,
token=token,
device_map="auto",
torch_dtype=torch.bfloat16,
)
tokenizer = AutoTokenizer.from_pretrained(
model_id,
token=token
)“google/gemma-2-27b-it”
モデルのタイプを指定しています。
token = “****************************”
HuggingFaceのトークンIDが入ります。
AutoModelForCausalLM.from_pretrained()
モデルを読み込みます。
torch_dtype=torch.bfloat16,:BF16の数値表現を指定しています。
量子化をする場合はquantization_config=BitsAndBytesConfig(load_in_4bit=True),を引数に追加してください。
AutoTokenizer.from_pretrained()
トークナイザーを読み込みます。

| モデルID | パラメータサイズ | GPUメモリ使用量 |
|---|---|---|
| google/gemma-2-2b-it | 20億パラメータ | 5GB(BF16,量子化なし) |
| google/gemma-2-9b-it | 90億パラメータ | 19GB(BF16,量子化なし) |
| google/gemma-2-27b-it | 270億パラメータ | 53GB(BF16,量子化なし) |
Gemma2でテキスト生成

Gemma2を使って、日本語での質問応答を試してみます。
日本語での質問応答(1)
「20代女性向けの新しいスキンケア商品のマーケティングキャンペーンを企画してください。」というプロンプトを日本語で実行してみます。
text = "20代女性向けの新しいスキンケア商品のマーケティングキャンペーンを企画してください。"
messages = [
{"role": "user", "content": text},
]
prompt = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
token_ids = tokenizer.encode(
prompt, add_special_tokens=False,
return_tensors="pt"
)
with torch.no_grad():
output_ids = model.generate(
token_ids.to(model.device),
max_new_tokens=256,
do_sample=True,
temperature=0.6,
top_p=0.9,
)
output = tokenizer.decode(
output_ids.tolist()[0][token_ids.size(1):],
skip_special_tokens=True
)
print(output)20代女性向けの新しいスキンケア商品のマーケティングキャンペーンを企画してください。
20代女性向け 新スキンケア商品マーケティングキャンペーン企画
商品名: (商品名を入れてください)
ターゲット: 20代女性 (学生・社会人)
キャンペーン目標:
商品認知度向上
ターゲット層への購買意欲喚起
ブランドイメージ向上
キャンペーン期間: 3ヶ月
キャンペーンテーマ: 「(商品名)で、輝く自分に出会う。」
キャンペーン戦略:
1. オンラインマーケティング:
SNSマーケティング: Instagram, TikTok, YouTubeなどでインフルエンサーマーケティングを実施。
20代女性に人気の美容系インフルエンサーとタイアップし、商品レビューや使用感動画を公開。
キャンペーンハッシュタグを作成し、ユーザー投稿を促進。
ライブ配信やQ&Aセッションで、商品について詳しく紹介。
Web広告: Google広告、Facebook広告などでターゲット層にピンポイント配信。
美容系Webサイトやアプリへのバナー広告掲載。
興味関心に合わせたリターゲティング広告で、購買意欲を高める。
…
日本語での質問応答(2)
「プレゼンテーションの準備で必要なことを教えて下さい。」というプロンプトを日本語で実行してみます。
text = "プレゼンテーションの準備で必要なことを教えて下さい。"
messages = [
{"role": "user", "content": text},
]
prompt = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
token_ids = tokenizer.encode(
prompt, add_special_tokens=False,
return_tensors="pt"
)
with torch.no_grad():
output_ids = model.generate(
token_ids.to(model.device),
max_new_tokens=256,
do_sample=True,
temperature=0.6,
top_p=0.9,
)
output = tokenizer.decode(
output_ids.tolist()[0][token_ids.size(1):],
skip_special_tokens=True
)
print(output)プレゼンテーションの準備で必要なことを教えて下さい。
プレゼンテーションの準備は、成功の鍵です!
効果的なプレゼンテーションの準備には、以下のステップが重要です。
1. 目的と対象を明確にする
なぜプレゼンテーションをするのか?
(情報を共有、説得、提案など、目的を具体的に)
誰にプレゼンテーションをするのか?
(年齢、知識レベル、関心事などを考慮)
どのような反応を期待するか?
(理解、同意、行動など)
2. 内容を構成する
導入: 聴衆の関心を引き、プレゼンテーションのテーマを明確に
興味深いストーリー、質問、統計データなどを活用
本論: 論理的な流れで情報を整理
データ、事例、図表などを効果的に活用
複雑な情報は分かりやすく簡潔に
結論: まとめと今後の展望
聴衆への呼びかけ
3. ビジュアル資料を作成する
簡潔で分かりやすいデザイン
…
コードの質問応答
「PyTorchで勾配を計算せずに推論を実行する場合のコードを生成してください。」というプロンプトを日本語で実行してみます。
text = "PyTorchで勾配を計算せずに推論を実行する場合のコードを生成してください。"
messages = [
{"role": "user", "content": text},
]
prompt = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
token_ids = tokenizer.encode(
prompt, add_special_tokens=False,
return_tensors="pt"
)
with torch.no_grad():
output_ids = model.generate(
token_ids.to(model.device),
max_new_tokens=256,
do_sample=True,
temperature=0.6,
top_p=0.9,
)
output = tokenizer.decode(
output_ids.tolist()[0][token_ids.size(1):],
skip_special_tokens=True
)
print(output)PyTorchで勾配を計算せずに推論を実行する場合のコードを生成してください。
```python
import torch
# モデルの定義 (例)
class MyModel(torch.nn.Module):
def __init__(self):
super(MyModel, self).__init__()
self.linear = torch.nn.Linear(10, 1)
def forward(self, x):
return self.linear(x)
# モデルのインスタンス化
model = MyModel()
# モデルの重みをロード (必要に応じて)
# model.load_state_dict(torch.load('model_weights.pth'))
# 推論モードに設定
model.eval()
# 入力データ (例)
input_data = torch.randn(1, 10)
# 勾配計算を無効化
with torch.no_grad():
# 推論実行
output = model(input_data)
# 結果の出力
print(output)
```
**解説:**
1. **`model.eval()`**: モデルを推論モードに設定します。これにより、DropoutやBatch Normalizationなどのレイヤーが推論時の挙動に変更されます。
2. **`with torch.no_生成AI・LLMのコストでお困りなら
GPUのスペック不足で生成AIの開発が思うように進まないことはありませんか?
そんなときには、高性能なGPUをリーズナブルな価格で使えるGPUクラウドサービスがおすすめです!

GPUSOROBANは、生成AI・LLM向けの高速GPUを業界最安級の料金で使用することができます。
インターネット環境さえあれば、クラウド環境のGPUサーバーをすぐに利用可能です。
大規模な設備投資の必要がなく、煩雑なサーバー管理からも解放されます。







