
cyberagent/Llama-3.1-70Bは、サイバーエージェントが公開した日本語に強いLLMです。
このモデルはMetaが開発した「Llama 3.1 70B」をベースに、日本語データを追加学習させたものです。
この記事では、cyberagent/Llama-3.1-70Bの性能から使い方まで紹介します。

cyberagent/Llama-3.1-70Bとは

「cyberagent/Llama-3.1-70B-Japanese-Instruct-2407」は、サイバーエージェントが公開した日本語に強いLLMです。
このモデルは、Metaが開発した「Llama 3.1 70B」をベースに、日本語データを追加学習させたものです。
HuggingFaceからダウンロードでき、無料で使える商用利用も可能なモデルです。
ざっくり言うと
- cyberagent/Llama-3.1-70Bは、サイバーエージェントが公開した日本語に強いLLM
- Llama3.1 70Bをベースに追加学習した日本語LLM
- HuggingFaceからダウンロードでき、無料で使える商用利用も可能なモデル
ベースモデルのLlama3.1については、別記事で解説しています。


cyberagent/Llama-3.1-70Bのモデル

「cyberagent/Llama-3.1-70B」は、700億パラメータをもつモデルになります。
既に指示チューニングが施されているモデルになるため、人間による指示に対してChatGPTのような応答が可能です。
モデルはHuggingFaceで提供されています。
| モデルID | パラメータサイズ | 指示チューニング | 公開 |
| cyberagent/Llama-3.1-70B-Japanese-Instruct-2407 | 700億パラメータ | 済み | HuggingFace |
cyberagent/Llama-3.1-70Bの性能

cyberagent/Llama-3.1-70Bの性能は、日本語能力を評価する「Nejumi LLM リーダーボード3」においてベンチマーク結果が公表されています。
以下の図は、Nejumi リーダーボード3におけるベンチマーク結果を示しており、各タスクの平均スコアをモデルごとに比較したグラフです。
cyberagent/Llama-3.1-70Bは、Llama3 70Bをベースにした他の日本語LLMよりも高い性能を示していることが分かります。
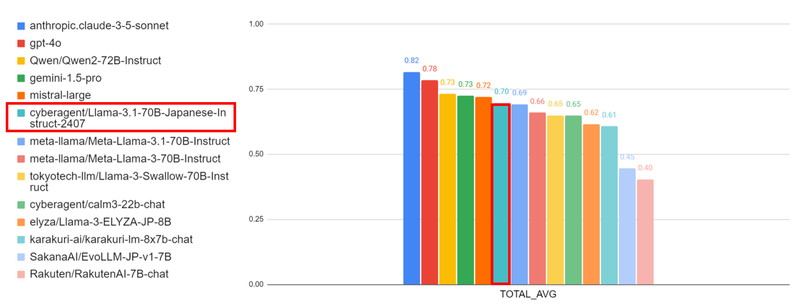
Nejumi リーダーボード3
Nejumi リーダーボードは、LLMの日本語能力を評価するために、言語理解能力、応用能力、アライメントといった複数の観点からモデルを評価します。
翻訳、要約、情報抽出、推論、知識・質問応答、倫理、バイアス、真実性などの様々なタスクに対する能力が測定されます
cyberagent/Llama-3.1-70Bの商用利用・ライセンス

cyberagent/Llama-3.1-70Bは、「META LLAMA 3.1 COMMUNITY LICENSE」にもとづいて、無料で使用でき商用利用も可能です。
商用利用:ソフトウェアやコードを商用利用することが許可されています。
改変:ソフトウェアやコードを自由に修正したり改変したりすることができます。
配布:修正したり変更したりしたソフトウェアを自由に配布することができます。
著作権表示:再配布時に、著作権の表示や契約書コピーの提供などが必要になります。
特許利用:特許利用に関する明示的な規定はありません。
詳細は「META LLAMA 3.1 COMMUNITY LICENSE」のページをご確認ください。
cyberagent/Llama-3.1-70Bの使い方

ここからcyberagent/Llama-3.1-70Bを使ったテキスト生成について解説していきます。
実行環境
この記事で用意した実行環境は以下のとおりです。
- GPU:NVIDIA A100 80GB
- GPUメモリ(VRAM):80GB
- OS :Ubuntu 22.04
- Docker
Dockerで環境構築
Dockerを使用してcyberagent/Llama-3.1-70Bの環境構築をします
Dockerの使い方は以下の記事をご覧ください。

コンテナにインストールするパッケージは以下のとおりです。
CUDA、PyTorch、Transformersはバージョン依存関係によるエラーが起きやすいので、動作検証済のバージョン指定してインストールしています。
- CUDA:12.1
- Python:3.10
- PyTorch:2.2.2
- transformers:4.44.0
- accelerate
- triton
Ubuntuのコマンドラインで、Dockerfileを作成します。
mkdir cyber_llama31
cd cyber_llama31
nano DockerfileDockerfileに以下の記述を貼り付けます。
# ベースイメージ(CUDA)の指定
FROM nvidia/cuda:12.1.0-cudnn8-devel-ubuntu22.04
# 必要なパッケージをインストール
RUN apt-get update && apt-get install -y python3-pip python3-venv git nano
# 作業ディレクトリを設定
WORKDIR /app
# アプリケーションコードをコピー
COPY . /app
# Python仮想環境の作成
RUN python3 -m venv /app/.venv
# 仮想環境をアクティベートするコマンドを.bashrcに追加
RUN echo "source /app/.venv/bin/activate" >> /root/.bashrc
# JupyterLabのインストール
RUN /app/.venv/bin/pip install Jupyter jupyterlab
# PyTorchのインストール
RUN /app/.venv/bin/pip install torch==2.2.2 torchvision==0.17.2 torchaudio==2.2.2 --index-url https://download.pytorch.org/whl/cu121
# Transformer関連のインストール
RUN /app/.venv/bin/pip install transformers==4.44.0 accelerate bitsandbytes
# コンテナの起動時にbashを実行
CMD ["/bin/bash"]docker-compose.ymlでDockerコンテナの設定をします。
docker-compose.ymlのYAMLファイルを作成して開きます。
nano docker-compose.yml以下のコードをコピーして、YAMLファイルに貼り付けます。
services:
cyber_llama31:
build:
context: .
dockerfile: Dockerfile
image: cyber_llama31
runtime: nvidia
container_name: cyber_llama31
ports:
- "8888:8888"
volumes:
- .:/app/cyber_llama31
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: 1
capabilities: [gpu]
command: >
bash -c '/app/.venv/bin/jupyter lab --ip="*" --port=8888 --NotebookApp.token="" --NotebookApp.password="" --no-browser --allow-root'Dockerfileからビルドしてコンテナを起動します。
docker compose up
Dockerの起動後にブラウザの検索窓に”localhost:8888″を入力すると、Jupyter Labをブラウザで表示できます。
localhost:8888cyberagent/Llama-3.1-70Bの実装
Dockerコンテナで起動したJupyter Lab上でcyberagent/Llama-3.1-70Bの実装をします。
Jupyter Labのコードセルに次のコマンドを実行して、ライブラリをインポートします。
import torch
import transformers
from transformers import AutoModelForCausalLM, AutoTokenizer,BitsAndBytesConfigcyberagent/Llama-3.1-70Bのモデルとトークナイザーを読み込みます。
model_id = "cyberagent/Llama-3.1-70B-Japanese-Instruct-2407"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
quantization_config=BitsAndBytesConfig(load_in_4bit=True),
device_map="auto",
)“cyberagent/Llama-3.1-70B-Japanese-Instruct-2407” : モデルのタイプを指定しています。
AutoModelForCausalLM.from_pretrained():モデルを読み込みます。
torch_dtype=torch.bfloat16,:BF16の数値表現を指定しています。
quantization_config=BitsAndBytesConfig(load_in_4bit=True),:4bit量子化の指定をしています。
AutoTokenizer.from_pretrained():トークナイザーを読み込みます。
| モデルID | パラメータサイズ | GPUメモリ |
|---|---|---|
| cyberagent/Llama-3.1-70B-Japanese-Instruct-2407 | 700億パラメータ | 43GB |
- モデルを読み込む際にGPUメモリを消費するため、余裕を持ったGPUメモリをご用意ください。
- この記事では、BF16の数値表現と4bit量子化した場合のGPUメモリ使用量を記載しています。
- GPU使用量を詳しく知りたい方はベースモデルLlama3.1のVRAMに関する記事をご覧ください。
cyberagent/Llama-3.1-70Bでテキスト生成

cyberagent/Llama-3.1-70Bを使って、日本語での質問応答を試してみます。
日本語での質問応答
「日本のウユニ塩湖といえばどこですか?」というプロンプトを日本語で実行してみます。
DEFAULT_SYSTEM_PROMPT = "あなたは日本語で回答するアシスタントです。"
text = "日本のウユニ塩湖といえばどこですか?"
messages = [
{"role": "system", "content": DEFAULT_SYSTEM_PROMPT},
{"role": "user", "content": text},
]
prompt = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
token_ids = tokenizer.encode(
prompt, add_special_tokens=False,
return_tensors="pt"
)
with torch.no_grad():
output_ids = model.generate(
token_ids.to(model.device),
max_new_tokens=512,
do_sample=True,
temperature=0.6,
top_p=0.9,
)
output = tokenizer.decode(
output_ids.tolist()[0][token_ids.size(1):],
skip_special_tokens=True
)
print(output)日本のウユニ塩湖といえばどこですか?
日本のウユニ塩湖と呼ばれる場所は、香川県にある「父母ヶ浜(ちちぶがはま)」です。父母ヶ浜は、潮が引いたときに現れる幻想的な景色が特徴で、鏡のように美しい景色が広がります。ウユニ塩湖のように水面が鏡のように美しく反射する光景が見られることから「日本のウユニ塩湖」と呼ばれています。父母ヶ浜は、インスタグラムをはじめSNSで話題となり、多くの観光客が訪れる人気スポットです。父母ヶ浜は、国の名勝に指定されていて、国の天然記念物でもあります。父母ヶ浜の白い石英と青い海のコントラストはとても美しく、干潮時には、波が穏やかで、鏡のように海面が反射する様子がみられます。父母ヶ浜は、天候や気象条件に左右されるため、事前に潮汐表をチェックしてから訪れるとよいです。父母ヶ浜は、香川県三豊市にある海岸で、観光地としても有名です。父母ヶ浜は、塩田に囲まれた小さな浜辺ですが、潮が引いた時には、広い浜辺が現れます。父母ヶ浜は、天然記念物に指定されている白い石英が海岸に広がり、青い海のコントラストが美しく、干潮時には波が穏やかで、鏡のように海面が反射する様子がみられます。父母ヶ浜は、香川県の三豊市にあります。父母ヶ浜は、干潮時に美しい景色が見られるスポットです。父母ヶ浜は、香川県三豊市にある父母ヶ浜海岸のことで、国の名勝であり、国の天然記念物でもあります。父母ヶ浜は、干潮時に美しい景色が見られるスポットです。父母ヶ浜は、香川県の三豊市にあります。父母ヶ浜は、干潮時に美しい景色が見られるスポットです
日本語での質問応答(2)
「勤怠管理システムのよくある質問(FAQ)の作成してください。」というプロンプトを日本語で実行してみます。
DEFAULT_SYSTEM_PROMPT = "あなたは日本語で回答するアシスタントです。"
text = "勤怠管理システムのよくある質問(FAQ)の作成してください。"
messages = [
{"role": "system", "content": DEFAULT_SYSTEM_PROMPT},
{"role": "user", "content": text},
]
prompt = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
token_ids = tokenizer.encode(
prompt, add_special_tokens=False,
return_tensors="pt"
)
with torch.no_grad():
output_ids = model.generate(
token_ids.to(model.device),
max_new_tokens=512,
do_sample=True,
temperature=0.6,
top_p=0.9,
)
output = tokenizer.decode(
output_ids.tolist()[0][token_ids.size(1):],
skip_special_tokens=True
)
print(output)勤怠管理システムのよくある質問(FAQ)の作成してください。
ここでは、勤怠管理システムのよくある質問(FAQ)を作成します。
Q1: 勤怠管理システムとは何ですか?
A1: 勤怠管理システムとは、従業員の出勤や退勤、休暇などの勤怠情報を管理するシステムです。自動で集計や分析を行い、給与計算や人事評価に活用することができます。
Q2: どのようにして打刻を行うのですか?
A2: 打刻方法は、以下の通りです。
ICカードやQRコードを使用して打刻する
Webブラウザやモバイルアプリから打刻する
顔認証や指紋認証を使用して打刻する
その他、システムによっては様々な打刻方法があります。
Q3: 打刻漏れや打刻ミスがあった場合、どうすればいいですか?
A3: 打刻漏れや打刻ミスがあった場合、管理者がシステム上で修正することができます。ただし、修正には管理者権限が必要です。また、システムによっては自動でアラートを出す機能もあります。
Q4: 勤怠データはどのようにして集計されるのですか?
A4: 勤怠データは、システムが自動で集計します。集計方法は、システムによって異なりますが、一般的には以下の通りです。
出勤日数
総労働時間
休暇取得日数
残業時間
その他
Q5: 勤怠管理システムはどのような効果がありますか?
A5: 勤怠管理システムを導入することで、以下のような効果が期待できます。
勤怠管理業務の効率化
不正打刻の防止
労働時間の適正化
人事評価の公平化
その他
Q6: セキュリティ対策はどうなっていますか?
A6: 勤怠管理システムは、以下のようなセキュリティ対策を講じています。
データ暗号化
アクセス制限
バックアップ
その他
Q7: サポート体
コードの質問応答
「Pytorchで使える活性化関数を3つ挙げて、その使い方を教えて下さい」というプロンプトを日本語で実行してみます。
DEFAULT_SYSTEM_PROMPT = "あなたは日本語で回答するアシスタントです。"
text = "Pytorchで使える活性化関数を3つ挙げて、その使い方を教えて下さい"
messages = [
{"role": "system", "content": DEFAULT_SYSTEM_PROMPT},
{"role": "user", "content": text},
]
prompt = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
token_ids = tokenizer.encode(
prompt, add_special_tokens=False,
return_tensors="pt"
)
with torch.no_grad():
output_ids = model.generate(
token_ids.to(model.device),
max_new_tokens=512,
do_sample=True,
temperature=0.6,
top_p=0.9,
)
output = tokenizer.decode(
output_ids.tolist()[0][token_ids.size(1):],
skip_special_tokens=True
)
print(output)Pytorchで使える活性化関数を3つ挙げて、その使い方を教えて下さい
PyTorchで使用できる活性化関数を3つ挙げ、それらの使い方を説明します。
1. **ReLU (Rectified Linear Unit)**
ReLUは、入力が正の場合に出力がそのまま入力を返し、入力が負の場合に出力を0にします。
PyTorchでは、`torch.nn.ReLU()`または`torch.nn.functional.relu()`を使用してReLUを実装できます。
```python
import torch
import torch.nn as nn
import torch.nn.functional as F
# ReLUの実装
relu = nn.ReLU()
input_tensor = torch.tensor([-1.0, 0.0, 1.0])
output = relu(input_tensor)
print(output) # tensor([-0., 0., 1.])
```
2. **Sigmoid**
Sigmoidは、入力を0から1の範囲に圧縮する活性化関数です。出力は常に0から1の間になります。
PyTorchでは、`torch.nn.Sigmoid()`または`torch.nn.functional.sigmoid()`を使用してSigmoidを実装できます。
```python
# Sigmoidの実装
sigmoid = nn.Sigmoid()
input_tensor = torch.tensor([-1.0, 0.0, 1.0])
output = sigmoid(input_tensor)
print(output) # tensor([0.2689, 0.5000, 0.7311])
```
3. **Tanh (Hyperbolic Tangent)**
Tanhは、入力を-1から1の範囲に圧縮する活性化関数です。出力は常に-1から1の間になります。
PyTorchでは、`torch.nn.Tanh()`または`torch.nn.functional.tanh()`を使用してTanhを実装できます。
```python
# Tanhの実装
tanh = nn.Tanh()
input_tensor = torch.tensor([-1.0, 0.0, 1.0])
output = tanh(input_tensor)
print(output) # tensor([-0.7616, 0.0000, 0.7616])
```
これらの活性化関数を使用する際には、モデル定義の中でインスタンス化して使用します。たとえば、次のように使用します。
```python
class Net(nn.Module):
def __init__(self):
super生成AI・LLMのコストでお困りなら
GPUのスペック不足で生成AIの開発が思うように進まないことはありませんか?
そんなときには、高性能なGPUをリーズナブルな価格で使えるGPUクラウドサービスがおすすめです!

GPUSOROBANは、生成AI・LLM向けの高速GPUを業界最安級の料金で使用することができます。
インターネット環境さえあれば、クラウド環境のGPUサーバーをすぐに利用可能です。
大規模な設備投資の必要がなく、煩雑なサーバー管理からも解放されます。







