
Black Forest Labsは、2024年8月に画像生成AIモデルの最新バージョンである「FLUX.1」をリリースしました。
Flux(フラックス)とは、Stable Diffusionや ComfyUIなどで利用できる画像生成AIのベースモデルです。
この記事では、「FLUX.1」ローカル環境の使い方を初心者向けに詳しく解説します。

FLUX.1とは?

FLUX.1は、Stable Diffusion 3 のリリース後に離れたチーム「Black Forest Labs」によって開発された、テキストや画像を生成することができるAIサービスです。
その性能は、Stable Diffusion 3 を凌駕しMidjourneyに匹敵するクオリティです。
FLUX.1の大きな特徴は、下記の3つです。
- Stable Diffusion をベースとした生成能力とパフォーマンスのバランスがいい!
- オープンソースとして利用が可能で、デベロッパーやコミュニティが豊富!
- 120億ものパラメータを誇り、高画質+高品質で業界水準が高い!
Stable Diffusion をベースとした生成能力とパフォーマンスのバランスがいい!
FLUX.1は、Stable Diffusionの開発者が設立した「Black Forest Labs」が提供している生成モデルです。
Stable Diffusionの最新ベースモデルとして扱われる「FLUX.1」は、Stable Diffusion 3の経験を踏まえた最新バージョンにあたります。
Stable Diffusionと同様の使い方で、より詳細な描写と高速な処理が可能となっています。
オープンソースとして利用が可能で、デベロッパーやコミュニティが豊富!
FLUX.1は、従来のStable Diffusionと同じくオープンソースであり、実用性が高いローカル利用が可能な設計です。
FLUX.1は、Schnell[軽量版]からProまで異なる特性を持つ3つのバージョンが提供されています。
それぞれのモデルの概要は以下の通りです。
| モデル | 商用利用 | 提供プラットフォーム |
|---|---|---|
| FLUX.1 Schnell | 可 | Hugging Face、GitHub、Replicate、fal.ai、mystic、deepinfra |
| FLUX.1 Dev | 要問合せ | Hugging Face、Replicate、fal.ai、mystic、deepinfra |
| FLUX.1 Pro | 可 | Replicate、fal.ai、mystic |
120億のパラメータを誇り、高画質+高品質で業界水準が高い!
FLUX.1は、従来の画像生成AIで見かける不自然な表現が大幅に抑制され、品質が大きく向上しています。
品質面で遅れていたStable Diffusion 3は、FLUX.1の登場によりMidjourneyなどの他の画像生成AIサービスに大きく差をつけられたと評価されています。

スポンサーリンク
FLUX.1 Stable Diffusion WebUI Forgeでの始め方・使い方

現在、FLUX.1は「Stable Diffusion WebUI Forge」、「ComfyUI」などの環境で利用が可能です。
ここからは、「Stable Diffusion WebUI Forge」上でのFLUX.1の始め方から使い方まで紹介します。
FLUX.1は、従来のモデルよりも多くの容量が必要になりますので、余裕をもって準備をしておきましょう。
まずは「Stable Diffusion WebUI Forge」を起動します。
FLUX.1が搭載された学習モデルのデータをHugging Faceからダウンロードしてセットします。
今回の生成に使用するファイルは下記の4つです。
- ①モデル: flux1-dev.safetensors (23.8GB)
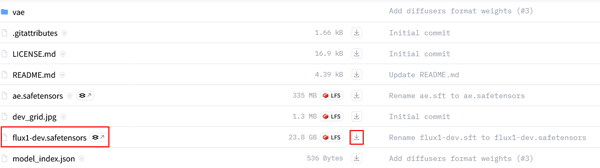
- ②テキストエンコーダー: t5xxl_fp16.safetensors (9.79GB)
- ③クリップ: clip_l.safetensors
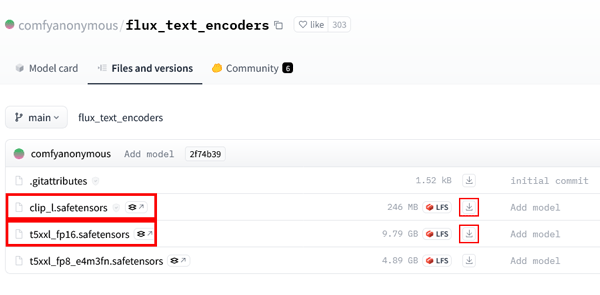
- ④VAE: ae.safetensors
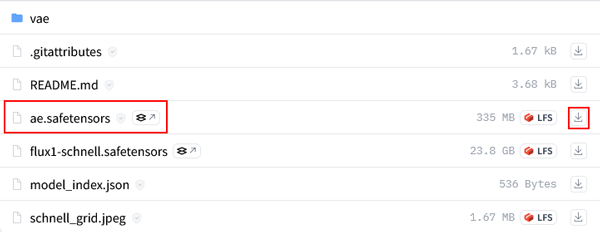
ダウンロードしたデータをフォルダにセットします。
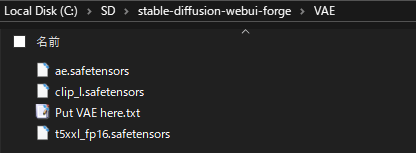
Stable Diffusion WebUI Forgeを「📁models」>「📁Stable Diffusion」の順で開き、先ほどダウンロードした「①flux1-dev.safetensors」を配置します。
続いて「②t5xxl_fp16.safetensors」「③clip_l.safetensors」「④ae.safetensors」 を「📁models」>「📁VAE」の順で開き、それぞれ配置します。
データのセットが完了したらStable Diffusion WebUI Forgeを開いてFLUX.をセットします。
トップ画面左上のUIにfluxに切り替えるボタンがあるので、fluxを選択します。
続いてcheckpointを「flux1-dev.safetensors」、VAEに「t5xxl_fp16.safetensors」「clip_l.safetensors」「ae.safetensors」の3つを選択します。

2024年9月1日現在、Stable Diffusion WebUI Forgeで利用する「FLUX」は、ネガティブプロンプトが入力できないようになっています。
無理に入力することもできますが、生成結果はノイズとなってしまいます。
今回は、プロンプトだけを入力して画像を生成します。
(masterpiece),((ultra-detailed)), (highly detailed CG illustration), (best quality:1.2), fringe, (lady:1.1), (reflection:1), (silhouette:1), One girl, alone, In a messy room,8K quality, watercolor painting, stylish design, (((The strongest beautiful girl of all time))), (((Japanese))),Idol,clear, Stylish sunglasses, Fashionable hats, (((highest quality))), bob hair, Place your hands on the wall, HDR, ((Detailed details)), stylish fashion, detailed clothing texture, (((graffiti art))), colorful hair, ((Super detailed)),(((colorful flowers)))
FLUX.1(Stable Diffusion WebUI Forge)で生成した画像

FLUX.1のおすすめモデルは次の記事で紹介しておりますので、よろしければご覧ください。

FLUX.1 ComfyUIでの始め方・使い方

ここでは、「ComfyUI」上でのFLUX.1の始め方から使い方まで紹介します。
FLUX.1は、従来のモデルよりも多くの容量が必要になりますので、余裕をもって準備をしておきましょう。
まずは「ComfyUI」を起動します。
FLUX.1が搭載された学習モデルのデータをHugging Faceからダウンロードしてセットします。
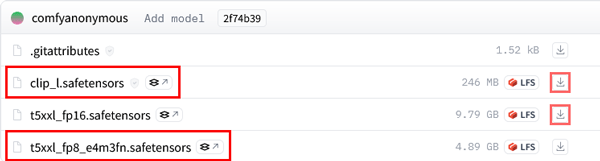
「ComfyUI」での生成に使用するファイルは下記の4つです。
- モデル: ①flux1-schnell.safetensors (23.8GB)
- ④VAE: ae.safetensors
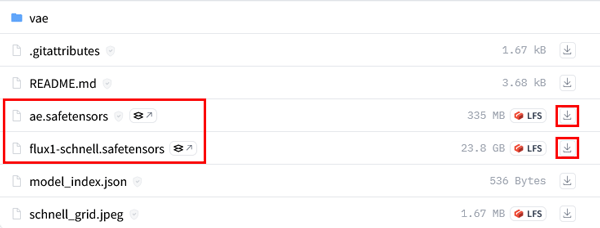
- テキストエンコーダー: ②t5xxl_fp8_e4m3fn.safetensors (4.89GB)
- クリップ:③ clip_l.safetensors
ダウンロードしたデータをフォルダにセットします。
Stable Diffusion WebUI とは一部セットするフォルダが異なりますので注意しましょう。
ComfyUIを「📁models」>「📁unet」の順で開き、先ほどダウンロードした「flux1-schnell.safetensors」を配置します。
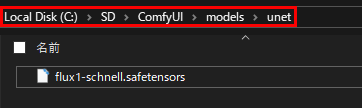
続いて「📁models」>「📁clip」の順で開き、先ほどダウンロードした「t5xxl_fp8_e4m3fn.safetensors 」、「clip_l.safetensors」を配置します。
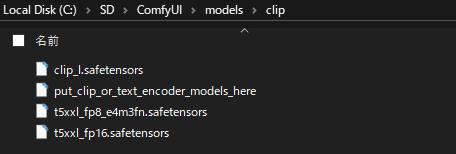
続いて「ae.safetensors」 を「📁models」>「📁vae」の順で開き配置します。
データのセットが完了したらComfyUIを起動してFLUX用のワークフローをセットします。
ワークフローをコピーするために公式サイトからデモ画像をダウンロードします。
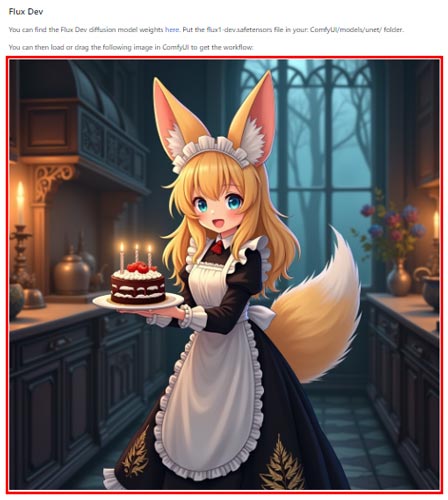
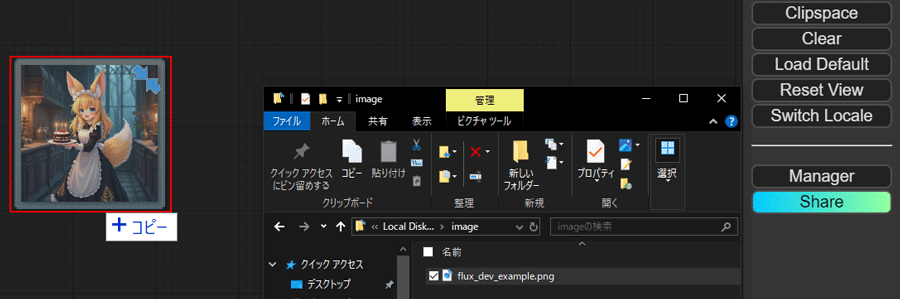
ダウンロードした画像をComfyUIの画面にドラッグ&ドロップで画像を読み込むと埋め込まれているワークフローデータを表示することができます。
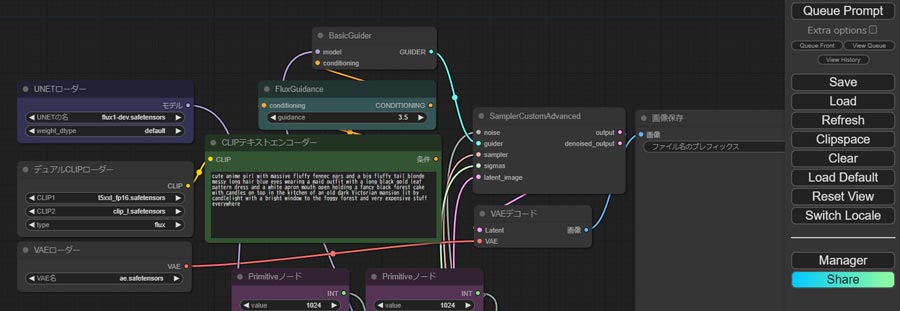
ComfyUIの生成開始画面で、各種パラメータを変更していきます。
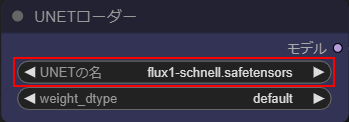
UNETローダー
・UNETの名にflux1-schnell.safetensorsを選択します
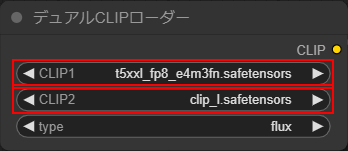
デュアルCLIPローダー
・CLIP1に「t5xxl_fp8_e4m3fn.safetensors」を選択します
・CLIP2に「clip_l.safetensors」を選択します
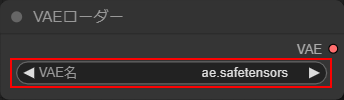
VAEローダー
・VAE名に「ae.safetensors」を選択します。
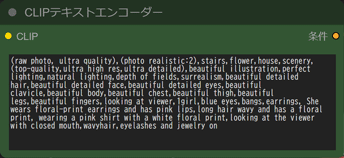
CLIPテキストエンコーダー
・プロンプトを入力します。
※ネガティブプロンプトは入力しません。
画像サイズはデフォルトの1024×1024、その他のパラメータはデフォルトのまま生成を開始します。
生成は右上の「Queue Prompt」ボタンをクリックします。
(raw photo, ultra quality),(photo realistic:2),stairs,flower,house,scenery,(top-quality,ultra high res,ultra detailed),beautiful illustration,perfect lighting,natural lighting,depth of fields,surrealism,beautiful detailed hair,beautiful detailed face,beautiful detailed eyes,beautiful clavicle,beautiful body,beautiful chest,beautiful thigh,beautiful legs,beautiful fingers,looking at viewer,1girl,blue eyes,bangs,earrings, She wears floral-print earrings and has pink lips,long hair wavy and has a floral print, wearing a pink shirt with a white floral print,looking at the viewer with closed mouth,wavyhair,eyelashes and jewelry on
FLUX.1(ComfyUI)で生成した画像


FLUX.1の料金プランと商用利用は?

FLUX.1 の料金プラン
FLUX.1 は、ローカル環境での使用範囲では無料で利用できます。
ただし、API経由での利用は、すべてのモデルが有料になります。
| モデル | 料金 | 商用利用 | 提供利用されている環境 |
|---|---|---|---|
| FLUX.1 Schnell | 無料 | 可 | API, ローカル環境 |
| FLUX.1 Dev | 無料 | モデルの商用利用は不可 | ローカル環境 |
| FLUX.1 Pro | 約0.05ドル/1枚 | 可 | API, Replicate, fal.ai |
ローカル環境で利用する場合は、「Schnell」が軽減された容量内で利用できるのでおすすめです。
API経由で利用する場合は、Black Forest Labs社が提携しているパートナーにのみ提供されているため、「Replicate「fal.ai」のサービスサイトに登録してから利用することになります。
FLUX.1の商用利用は?
FLUX.1 での商用利用は利用するモデルによって異なります。
生成された画像は、全てのモデルにおいて商用利用が可能です。
モデル自体の商用利用は、FLUX.1 Devのみ不可となっています。
スポンサーリンク
FLUX.1を使いこなして生成AIをマスターしよう!
今回は、Black Forest Labsが公開したStable Diffusionの最新モデル「FLUX.1」の使い方について紹介しました。
FLUX.1は、従来の画像生成サービスと比較して、最もクオリティが高い画像を生成することができます!
無料で利用できる動画生成AIサービスの中でトップクラスなので、このチャンスに高性能ツールで画像生成を極めてみましょう。







