
ComfyUIは、Stable Diffusionでの画像生成以外にも動画を生成できるワークフローがあります。
画像生成同様にComfyUIを利用すれば動画生成に対しても計算資源の節約が可能です。
この記事ではComfyUIで簡単に動画生成を行う方法を解説します。

ComfyUIの基本的なワークフロー

ComfyUIで使用する基本的なワークフローを紹介します。
基本的には、Stable Diffusionと同様の機能が使えるようになっています。
ComfyUIにインストール方法は、こちらの記事で詳しく解説しています。

テキストから画像に
ComfyUIでテキストから画像を生成する方法は、Stable Diffusionと同じtxt2imgを使います。
プロンプトテキストを入力してモデルを設定し生成を開始します。
デフォルト画面のワークフローは画像生成のセットになっています。
最初に、先頭にあるノードのcheckpointを選択します。
テスト生成する場合はプリンストールされているデフォルトのモデルで大丈夫です。
次にモデルの画風に沿ったプロンプトとネガティブプロンプトを入力します。
最後に画像サイズを指定します。
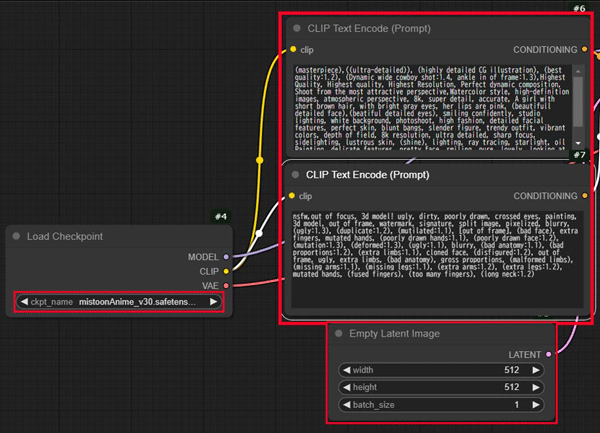
バッチ回数は生成したい画像の枚数を指します。
場面上部に▷Queueボタンの右側に数字を入力する欄あるので、そこに生成する画像の枚数を指定します。
数値を入力したらQueueボタンをクリックして画像生成を開始します。
生成された画像はSave Imageに表示されます。
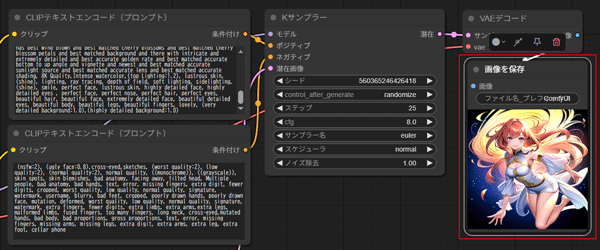
セットアップから生成までの解説はこちらの記事で詳しく紹介していいます。

画像から画像に
ComfyUIで画像から画像を生成する方法は、img2imgのワークフローを使います。
img2imgのワークフローは、デフォルトで実装されているテンプレートを読み込みます。
左側のパネルのフォルダアイコンをクリックします。
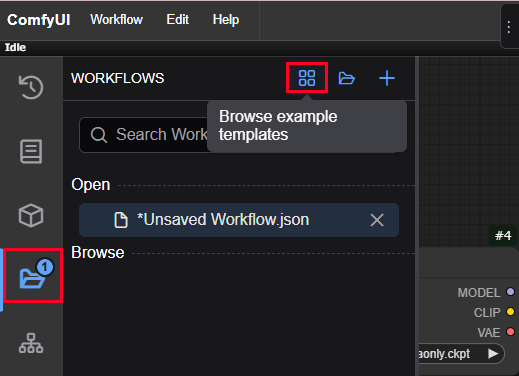
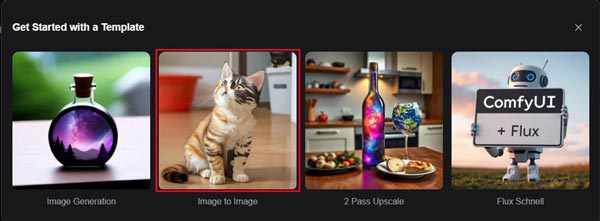
image to imageのテンプレートをクリックしてワークフローを読み込みます。
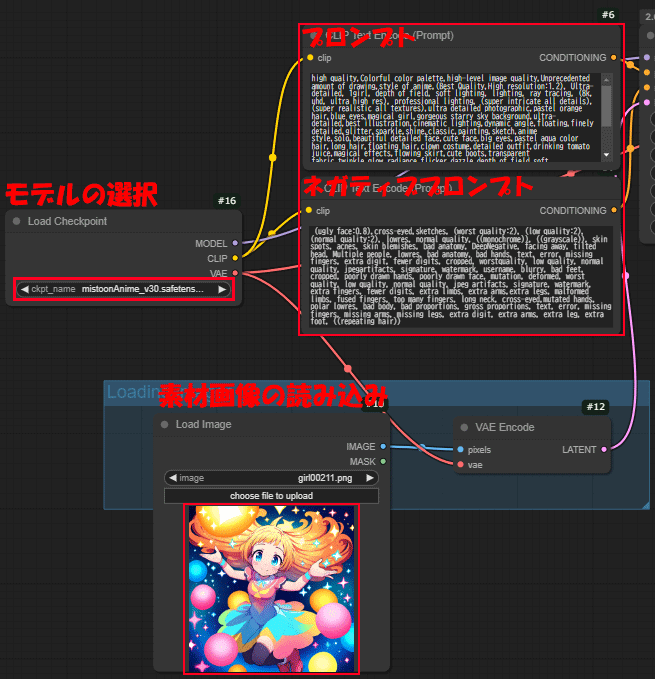
①ベース画像を使って生成したい画像のモデルを選択します。
②素材となる画像を#10 Load Image に読み込みます。
③最後にプロンプトとネガティブプロンプトを入力して完了です。
※プロンプトは、素材画像に沿った内容を簡単に入力します。
バッチ回数とは、生成したい画像の枚数を指します。
場面上部に▷Queueボタンの右側に数字を入力する欄あるので、そこに生成する画像の枚数を指定します。
数値を入力したらQueueボタンをクリックして画像生成を開始します。
生成された画像はSave Imageに表示されます。


ComfyUIで動画生成

ここからは実際に「Wan2.1」を使ってComfyUIで動画生成する方法を解説します。
Wan2.1は、アリババが開発した最先端の動画生成AIです。テキストや画像を入力するだけで、高品質な動画を簡単に生成できます。
下記のステップで実際に動画を生成してみましょう。
「ComfyUI」>「custom_nodes」を開き、下記のコマンドを入力してComfyUI用のWan2.1プロジェクトをインストールします。
cd ComfyUI/custom_nodes
git clone https://github.com/kijai/ComfyUI-WanVideoWrapper.git
続いて、依存関係を取り除きます。
cd ComfyUI/custom_nodes/ComfyUI-WanVideoWrapper
pip install -r requirements.txt
動画を生成するベースとなるモデルファイルをHugging Faceからダウンロードします。
今回は「Wan2_1-T2V-1_3B_fp8_e4m3fn.safetensors」を使用します。
ダウンロードしたデータは「ComfyUI」>「models」>「 diffusion_models」に格納します。
cd ComfyUI/models/diffusion_models
wget https://huggingface.co/Kijai/WanVideo_comfy/blob/main/Wan2_1-T2V-1_3B_fp8_e4m3fn.safetensors
次にVAEのモデルデータをHugging Faceからダウンロードします。
データは、「wan_2.1_vae.safetensors(254 MB)」を使用します。
ダウンロードしたデータは「ComfyUI」>「models」>「vae」に格納します。
cd ComfyUI/models/vae
wget https://huggingface.co/Comfy-Org/Wan_2.1_ComfyUI_repackaged/blob/main/split_files/vae/wan_2.1_vae.safetensors
最後にCLIPデータをHugging Faceからダウンロードします。
- umt5_xxl_fp8_e4m3fn_scaled.safetensors(6.74GB)
「ComfyUI」>「models」>「text_encoders」を開き、下記のコマンドを入力してCLIPデータフォルダにダウンロードして配置します。
cd ComfyUI/models/clip
wget https://huggingface.co/Comfy-Org/Wan_2.1_ComfyUI_repackaged/blob/main/split_files/text_encoders/umt5_xxl_fp8_e4m3fn_scaled.safetensors
今回は公式で配布されているテキストから動画を生成できるワークフローを使用します。
ワークフローデータは、公式に公開されているサンプルファイルをダウンロードして使用します。
ダウンロードしたワークフローデータ(text_to_video_wan.json)をComfyUIの画面にドラッグ&ドロップで読み込みます。
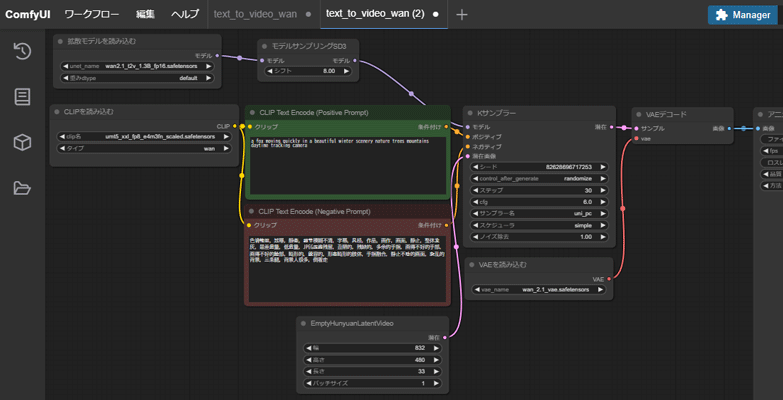
ノードが正常に反映されているか確認します。
ComfyUIの生成開始画面で、各種パラメータを変更していきます。
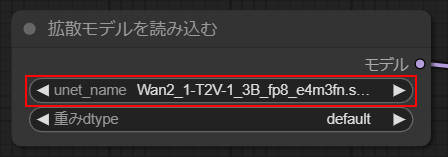
unet_name
・unet_nameにWan2_1-T2V-1_3B_fp8_e4m3fn.safetensors
を選択します。
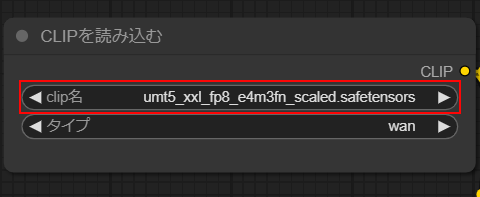
clip名
・umt5_xxl_fp8_e4m3fn_scaled.safetensors
に設定します。
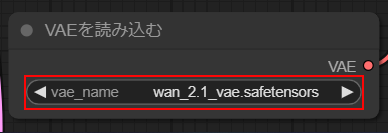
vae_name
・wan_2.1_vae.safetensors
を選択します。
その他のパラメータはデフォルトのままで問題ありません。
画面上部の▷Queueボタンの右側に数字を入力する欄あるので生成したい動画の本数を指定します。
その後「Queue」ボタンをクリックして生成を開始します。
使用したプロンプト
青色の猫型ロボットが一生懸命仕事をしている
Wan2.1(ComfyUI)で生成した動画

ComfyUIで動画をアップスケール

ComfyUIで動画を簡単にアップスケール方法を紹介します。
OpenArtで配布されているアップスケール用のワークフローをダウンロードします。
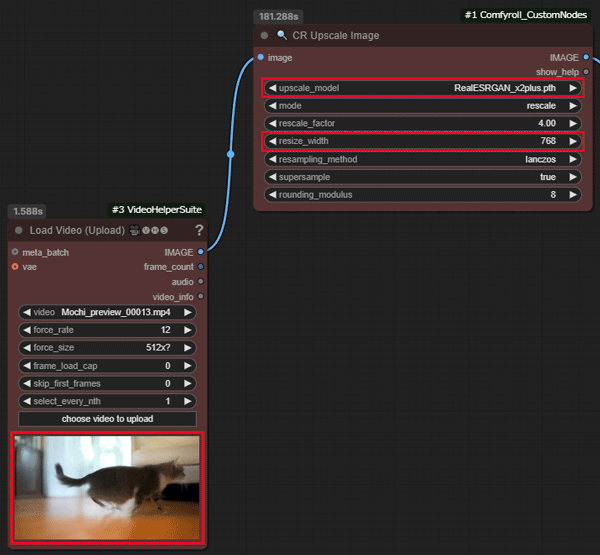
ComfyUIに読み込んで「CR Upscale Image」のノードを手動でインストールします。
ComfyUI Managerの「Install Missing Custom Nodes」から不足しているノードのプロジェクトをクリックして補完します。

拡大したい動画ファイルを読み込んでリサイズしたい大きさを指定します。
その他のパラメーターはデフォルトのままで大丈夫です。
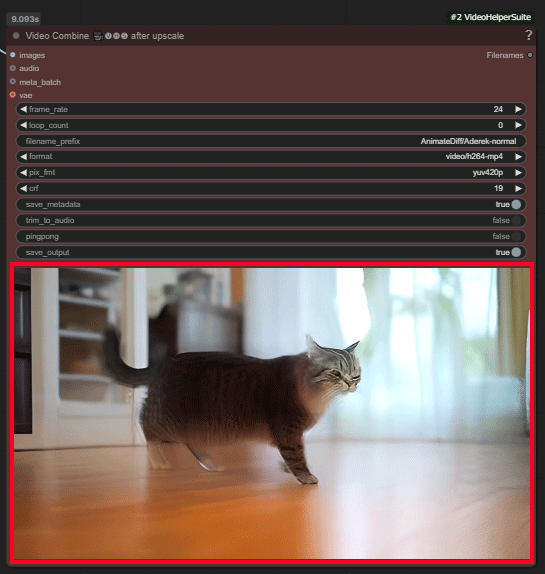
画面上部のQueueボタンの右側に数字を入力する欄あるので生成したい動画の本数を指定します。
その後「Queue」ボタンをクリックして生成を開始します。
しばらくすると拡大された動画が右側のノードに表示されます。

ComfyUIを快適に活用するならクラウドGPUがおすすめ

ComfyUIを快適に利用するなら、クラウドGPUの利用がおすすめです。
クラウドGPUとは、インターネット上で高性能なパソコンを借りることができるサービスで、最新の高性能GPUを手軽に利用することが可能です。
さらに、クラウドGPUの料金は使用時間に応じて加算されるため、停止すれば料金はかかりません。
クラウドGPUのメリット
- コスト削減:高額なGPUを購入する必要がなく、使用した分だけの支払い
- 高性能:最新の高性能GPUを利用できるため、高品質な画像生成が可能
- 柔軟性:必要なときに必要なだけ使えるので便利
こんな人におすすめ
- 少ない予算でComfyUIを快適に使いたい人
- 自分のパソコンの性能が不足していると感じる人
- 常に最新の高性能GPUを使いたい人
GPUSOROBAN

GPUSOROBANは、高性能なGPU「NVIDIA A4000 16GB」を業界最安値の1時間50円で使用することができます。
さらに、クラウドGPUを利用しない時は停止にしておくことで、停止中の料金はかかりません。
クラウドGPUを使えばいつでもStable Diffusionの性能をフルに引き出すことができるので、理想の環境に近づけることができます。
\快適に生成AI!1時間50円~/
ComfyUIで動画を生成すればクオリティアップ間違いなし!
現在展開されている動画生成AIは、有料でも短時間で自由が利かないようなサービスが多くあります。
ComfyUIは、ローカルやクラウド環境で自由に動画の生成ができるので、プロンプト次第で高いクオリティの動画を生成することができます。







