
Wan2.1 VACE(All-in-One Video Creation and Editing)は、アリババが2025年3月に公開したオープンソースの動画生成AI「Wan2.1」の最新バージョンです。
Wan2.1 VACEを使えば、動画の生成や編集を一つでこなすことができます。
この記事では、初心者にも分かりやすく、Wan2.1 VACEの概要とComfyUIを活用したローカル環境での導入・使い方を解説します。
Wan2.1 VACEとは?

Wan2.1 VACEは、VACEは動画生成や編集をとても細かくコントロールでき、いろいろな入力データを組み合わせて、自由度の高いビデオ制作ができる先進的なAIモデルです。
VACEの特徴は、これまで複数のツールやモデルを使い分ける必要があった作業(テキストからの動画生成、画像を参考にした動画生成、動画編集、動画の拡張など)が、VACE一つで簡単にできるという点です。
ユーザーは無駄な手間なく、より自由にアイデアを形にできるようになり、動画制作の創造力と効率が大きくアップします。
Wan2.1 VACEの主な特徴は下記の3つです。
- 人のポーズや動き、構造、空間的な動き、色合いなどを自由に調整しながら動画を生成
- 生成した後でもキャラクターのポーズや動き、背景のレイアウトなどを変更が可能
- オープンソースモデルで、無料で利用可能
VACEは、動画の作成と編集のためのオールインワンモデル

VACEは、リファレンスを元に動画を生成する「R2V(Reference-to-Video)」、既存の動画を編集する「V2V(Video-to-Video)」、特定の部分だけを編集する「MV2V(Masked Video-to-Video)」といった多様なタスクに対応しています。
自由にタスクを組み合わせて多様な可能性を探求し、効率的にワークフローを進めることができます。
「Move-Anything(何でも動かす)」「Swap-Anything(何でも入れ替える)」「Reference-Anything(何でも参照する)」「Expand-Anything(何でも拡張する)」「Animate-Anything(何でもアニメーション化する)」など、幅広い機能を提供します。
革新的な「ビデオ条件ユニット(VCU)」
Wan2.1 VACEは、ビデオ編集において特定領域の置き換え・追加・削除だけでなく、フレームを基に時間軸を補完する機能や背景の拡張・変更も可能です。
特に注目すべきは、画像や動画をアップロードし、それに運動姿勢、光フロー、深度マップなどの制御信号を組み合わせることで、部分的な映像の再描画や主体の置換を可能にする機能です。
この機能の大きな特徴は、Stable DiffusionのControlNetが画像編集で実現している高度な編集機能を、そのまま動画編集にも応用できる点です。
テキストからビデオ生成、ポーズコントロール、背景変更などを一つのモデルで行えるため、従来のように個別のモデルをトレーニングする必要がありません。
オープンソースモデルで、無料で利用することができる
Wan2.1 VACEは、Apache 2.0ライセンスのもとで公開されており、無料で利用可能です。
Wan2.1 VACEはローカル環境、クラウド環境、ComfyUIで動作可能で、多様な利用シナリオに対応していて、カスタマイズや独自用途への適用が容易です。
オープンソース化により、学術研究者や企業が初期費用を抑えつつ、高品質な動画生成技術をプロジェクトに統合できます。


Stable Diffusionの使い方は、機能別に下記の記事にまとめているのでぜひご覧ください

Wan2.1 VACE ComfyUIでの始め方・使い方

ここでは、「ComfyUI」を使ったローカル環境での「Wan2.1 VACE」の始め方から使い方まで紹介します。
ComfyUIの導入方法はこちらの記事で詳しく解説しています。

Wan2.1 VACEは、多くのGPUパワーが必要になりますので、余裕をもって準備をしておきましょう。
最初にベースとなるWan2.1 専用の環境を設定します。
同じPC内で異なるプログラムのバージョンを利用するには、ソフト専用の環境を作ります。そうすることでパッケージの競合を防ぐことができます。
ここでは、conda環境を利用して整えます。
下記のコマンドを入力して環境を新規で構築します。
conda create -n Wan python=3.10
conda activate Wan
pip install torch==2.5.1+cu118 torchvision --extra-index-url https://download.pytorch.org/whl/cu118環境の設定が完了したらデータのインストールに進みます。
「ComfyUI」>「custom_nodes」を開き、下記のコマンドを入力してComfyUI用のWan2.1 VACEプロジェクトをインストールします。
cd ComfyUI/custom_nodes
git clone https://github.com/kijai/ComfyUI-WanVideoWrapper.git「ComfyUI-WanVideoWrapper」を開き、依存関係を取り除く追加データを入手します。
cd ComfyUI/custom_nodes/ComfyUI-WanVideoWrapper
pip install -r requirements.txt次に、動画を生成するためのモデルデータを入手します。
動画生成に必要なモデルデータは下記の3つです。
- 動画のモデルデータ
- VAE
- CLIP
動画のモデルデータ
動画のモデルデータをHugging Faceからダウンロードします。
- wan2.1_vace_1.3B_fp16.safetensors(4.31 GB)
最初は軽量版の「wan2.1_vace_1.3B_fp16.safetensors」を使用します。
「ComfyUI」>「models」>「diffusion_models」を開き、下記のコマンドを入力して動画のモデルデータをダウンロードして配置します。
cd ComfyUI/models/diffusion_models
wget https://huggingface.co/Comfy-Org/Wan_2.1_ComfyUI_repackaged/blob/main/split_files/diffusion_models/wan2.1_vace_1.3B_fp16.safetensorsVAE
次にVAEのモデルデータをHugging Faceからダウンロードします。
- wan_2.1_vae.safetensors(254 MB)
「ComfyUI」>「models」>「vae」を開き、下記のコマンドを入力してVAEのモデルデータをダウンロードして配置します。
cd ComfyUI/models/vae
wget https://huggingface.co/Comfy-Org/Wan_2.1_ComfyUI_repackaged/blob/main/split_files/vae/wan_2.1_vae.safetensorsCLIP
最後にCLIPデータをHugging Faceからダウンロードします。
- umt5_xxl_fp8_e4m3fn_scaled.safetensors(6.74GB)
「ComfyUI」>「models」>「text_encoders」を開き、下記のコマンドを入力してCLIPデータフォルダにダウンロードして配置します。
cd ComfyUI/models/clip
wget https://huggingface.co/Comfy-Org/Wan_2.1_ComfyUI_repackaged/blob/main/split_files/text_encoders/umt5_xxl_fp8_e4m3fn_scaled.safetensors今回は公式で配布されている総合ワークフローを使用します。
ワークフローデータは、公式に公開されているサンプルファイル(動画ファイル)を右クリック後にダウンロードして使用します。
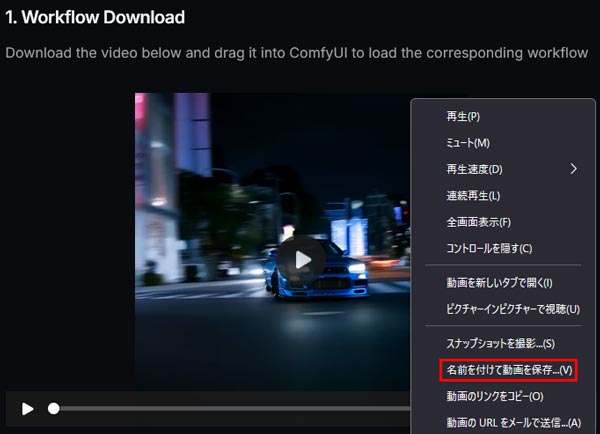
ダウンロードしたワークフローデータ(動画ファイル)をComfyUIの画面にドラッグ&ドロップで読み込みます。
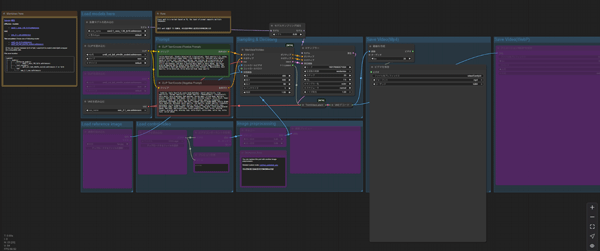
ノードが正常に反映されているか確認します。
ComfyUIの生成開始画面で、VACE用のモデルデータをセットして準備を整えます。
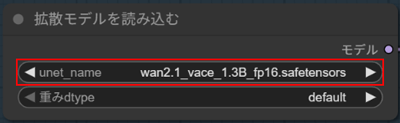
モデル
・wan2.1_vace_1.3B_fp16.safetensors
を選択します。
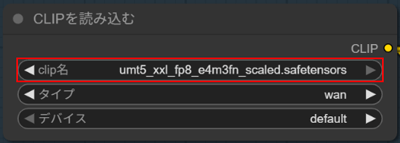
clip
・umt5_xxl_fp8_e4m3fn_scaled.safetensors
に設定します。
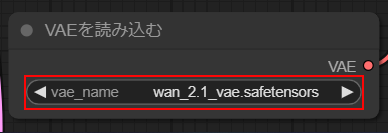
VAE
・wan_2.1_vae.safetensors
を選択します。
その他のパラメータはデフォルトのままで問題ありません。
プロンプトとネガティブプロンプトを入力して、画面上部の「▷Queueボタン」の右側に数字を入力する欄あるので生成したい動画の本数を指定します。
その後「▷Queue」ボタンをクリックして生成を開始します。
A cat walking,Instead of “a cat walking,” try “a fluffy orange tabby cat walking slowly, on a cloud
Wan2.1 VACE(ComfyUI)で生成した動画
Wan2.1 VACEには、動画を生成するいくつかの方法があります。
ワークフローではノードを切り替えることができ、共通して利用することが可能です。
画像から動画を生成(Image-to-Video)
Wan2.1 VACEのワークフローには画像から動画を生成する機能があります。
ノード「Load referemce imade」の枠内でCtl+Bを押下して、Image-to-Videoをアクティブに切り替えます。
動画のベースとなる画像を読み込んで、付けたい動きをプロンプトに入力します。
smile,cute smile

スポンサーリンク
Wan2.1 VACEの料金プランと商用利用は?

Wan2.1 VACEの料金プランと商用利用について解説します。
Wan2.1 VACEの公式プロジェクトはApache 2.0ライセンスのもとで提供されており、自由にコードを利用できます。
現在、公式の料金プランは発表されていません。しかし、将来的にアリババクラウドなどのプラットフォームでAPI提供される可能性があると考えられます。
その際、他の生成AIサービスと同様に、計算資源に応じた従量課金制や月額プランが導入される可能性があります
Wan2.1 VACEの商用利用は?
Wan2.1 VACEはApache 2.0ライセンスのもとで提供されており、商用利用を含めた幅広い用途での利用が認められています。
具体的には、以下のような利用例が許可されています。
- 商用利用
- コードの改変・再配布
- 特許の使用
ただし、今後、サービス提供時にライセンスが変更される可能性もあるため、商用プロジェクトで利用する際は、最新のライセンス情報を必ず確認しましょう。


Wan2.1 VACEのような動画生成AIにはクラウドGPUがおすすめ

Wan2.1 VACEで長尺の動画を生成するには、高スペックなパソコンが必要です。
ただし、Wan2.1 VACEを快適に利用できるような高性能なパソコンは、ほとんどが30万円以上と高額になります。
コストを抑えたい方へ:クラウドGPUの利用がおすすめ
クラウドGPUとは、インターネット上で高性能なパソコンを借りることができるサービスです。これにより、最新の高性能GPUを手軽に利用することができます。
クラウドGPUのメリット
- コスト削減:高額なGPUを購入する必要がなく、使った分だけ支払い
- 高性能:最新の高性能GPUを利用できるため、高品質な画像生成が可能
- 柔軟性:必要なときに必要なだけ使えるので便利

Wan2.1 VACEを使いこなして動画生成AIをマスターしよう!
今回は、動画生成AI・Wan2.1の最新バージョン「Wan2.1 VACE」の使い方について紹介しました。
Wan2.1 VACEは、あらゆる方法で動画生成が可能なオールインワンタイプのワークフローで。無料で利用することができます。
無料で利用できる動画生成AIのオープンソースの中でトップクラスなので、このチャンスに高性能ツールで動画生成を極めてみましょう。







