
「HunyuanVideo」は、130億ものパラメータを持つ高性能なオープンソース動画生成AIです。
HunyuanVideoを使えば、簡単なテキストプロンプトで高品質な動画を生成できます。
この記事では、初心者向けにHunyuanVideoの概要とComfyUIを使ったローカル環境での使い方をわかりやすく解説します。
HunyuanVideoとは?

HunyuanVideoは、簡単なテキストプロンプトから動画を生成できる、Tencentの最新AIモデルです。
例えば「花が咲く様子をゆっくり映した動画」や「街角の夕暮れ風景」といった簡単な文章を入力するだけで、それをヒントにイメージ通りの動画を作成できます。
HunyuanVideoの大きな特徴は下記の3つです。
- マルチモーダルLLMによる高品質な動画生成
- 「統合型画像・動画生成アーキテクチャ」が統一された仕組み
- 高い圧縮率:進化した3D VAEモデル!
マルチモーダルLLMによる高品質な動画生成
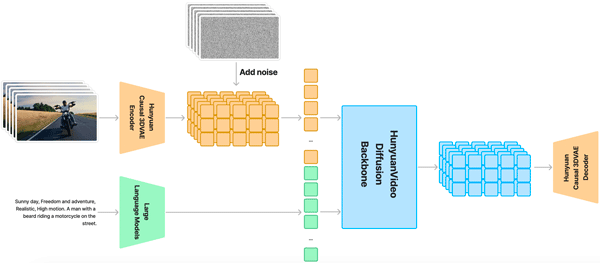
HunyuanVideoには、マルチモーダルLLMが採用することで、従来を超える高品質な動画生成を実現しています。
このモデルは、テキストプロンプトを大規模言語モデルでエンコードし、その結果を条件として活用します。
その条件を基に、因果的な3D VAEを通じて圧縮された潜在空間において、時空間的なトレーニングを実施します。
さらに、ガウスノイズと条件を入力として利用し、生成された潜在出力を3D VAEデコーダで画像や動画にデコードします。
この高度な技術により、テキストプロンプトを入力するだけで、視覚的にも意味的にも優れた動画を簡単に作成することが可能です。
「統合型画像・動画生成アーキテクチャ」が統一された仕組み

HunyuanVideoは、Transformer設計とFull Attentionメカニズムを用いて、画像と動画の統一生成を行います。
動画生成には「デュアルストリームからシングルストリーム」へのハイブリッドモデルを採用しています。
- デュアルストリームフェーズ:動画とテキストのトークンをそれぞれ独立したTransformerブロックで処理します。このフェーズでは、各モダリティ(動画とテキスト)の特性に応じた最適な調整メカニズムを学習します。
- シングルストリームフェーズ:動画とテキストのトークンを結合し、次のTransformerブロックでマルチモーダル情報を効果的に融合します。
この設計により、視覚情報(動画)と意味情報(テキスト)の複雑な相互作用を捉え、モデル全体の性能を向上させています。
高い圧縮率:進化した3D VAEモデル!

HunyuanVideoは、CausalConv3Dを用いた進化した3D VAEをトレーニングして、ピクセル空間の動画や画像を圧縮した潜在空間に変換します。
圧縮率は、動画の長さが4、空間が8、チャンネル数が16で設定されています。
これにより、後続の拡散トランスフォーマーモデルで扱うトークンの数を大幅に削減し、元の解像度とフレームレートで動画をトレーニングすることが実現しています。


Stable Diffusionの使い方は、機能別に下記の記事にまとめているのでぜひご覧ください

HunyuanVideo ComfyUIでの始め方・使い方

ここでは、「ComfyUI」を使ったローカル環境での「HunyuanVideo」の始め方から使い方まで紹介します。
HunyuanVideoは、多くのGPUパワーが必要になりますので、余裕をもって準備をしておきましょう。
最初にHunyuanVideo専用の環境を設定します。
HunyuanVideoは、Python、PyTorch、CUDAのバージョンに推奨設定があります。
同じPC内で異なるプログラムのバージョンを利用するには、ソフト専用の環境を作ります。そうすることでパッケージの競合を防ぐことができます。
ここでは、conda環境を利用して整えます。
下記のコマンドを入力して環境を新規で構築します。
conda create -n hunyuanvideo python=3.10.9
conda activate hunyuanvideo
pip install torch==2.5.1+cu118 torchvision --extra-index-url https://download.pytorch.org/whl/cu118環境の設定が完了したらデータのインストールに進みます。
「ComfyUI」>「custom_nodes」を開き、下記のコマンドを入力してComfyUI用のHunyuanVideoプロジェクトをインストールします。
cd ComfyUI/custom_nodes
git clone https://github.com/kijai/ComfyUI-HunyuanVideoWrapper.git「ComfyUI-HunyuanVideoWrapper」を開き、起動に必要な追加データを入手します。
cd ComfyUI/custom_nodes/ComfyUI-HunyuanVideoWrapper
pip install -r requirements.txt次に、動画を生成するためのモデルデータを入手します。
動画生成に必要なモデルデータは下記の4つです。
- 動画のモデルデータ
- VAE
- LLM
- CLIP
動画のモデルデータ
動画のモデルデータをHugging Faceからダウンロードします。
- hunyuan_video_720_cfgdistill_bf16.safetensors(25.6 GB)
- hunyuan_video_720_cfgdistill_fp8_e4m3fn.safetensors(13.2 GB)
最初は軽量版の「hunyuan_video_720_cfgdistill_fp8_e4m3fn.safetensors」を使用します。
「ComfyUI」>「models」>「diffusion_models」を開き、下記のコマンドを入力して動画のモデルデータをダウンロードして配置します。
cd ComfyUI/models/diffusion_models
wget https://huggingface.co/Kijai/HunyuanVideo_comfy/blob/main/hunyuan_video_FastVideo_720_fp8_e4m3fn.safetensorsVAE
次にVAEのモデルデータをHugging Faceからダウンロードします。
- hunyuan_video_vae_bf16.safetensors(493 MB)
- hunyuan_video_vae_fp32.safetensors(986 MB)
「ComfyUI」>「models」>「vae」を開き、下記のコマンドを入力してVAEのモデルデータをダウンロードして配置します。
cd ComfyUI/models/vae
wget https://huggingface.co/Kijai/HunyuanVideo_comfy/blob/main/hunyuan_video_vae_fp32.safetensors
wget https://huggingface.co/Kijai/HunyuanVideo_comfy/blob/main/hunyuan_video_vae_bf16.safetensorsLLM
次にLLMのモデルデータをHugging Faceから「llava-llama-3-8b-text-encoder-tokenizer」をダウンロードします。
- llava-llama-3-8b-text-encoder-tokenizer(約16GB)
「ComfyUI」>「models」>「LLM」を開き、下記のコマンドを入力してLLMのモデルデータフォルダをダウンロードして配置します。
cd ComfyUI/models/LLM
git clone https://huggingface.co/Kijai/llava-llama-3-8b-text-encoder-tokenizerCLIP
最後にCLIPデータをHugging Faceから「clip-vit-large-patch14」をダウンロードします。
- clip-vit-large-patch14(約7GB)
「ComfyUI」>「models」>「clip」を開き、下記のコマンドを入力してCLIPデータフォルダをダウンロードして配置します。
cd ComfyUI/models/clip
git clone https://huggingface.co/openai/clip-vit-large-patch14今回は公式で配布されているテキストから動画を生成できるワークフローを使用します。
ワークフローデータは、公式に公開されているサンプルファイルをダウンロードして使用します。

ダウンロードしたワークフローデータ(hunyuanvideo_t2v.json)をComfyUIの画面にドラッグ&ドロップで読み込みます。
ノードが正常に反映されているか確認します。
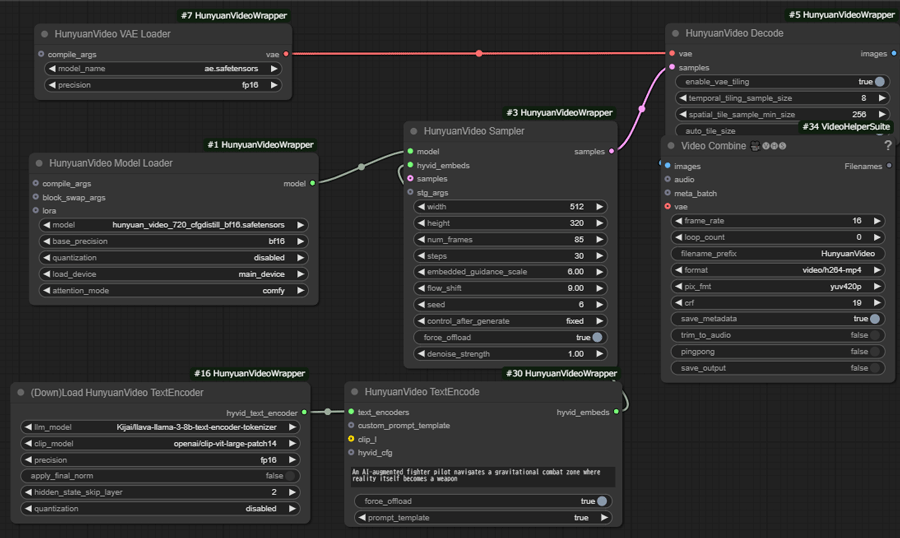
再起動後、赤いノードがないことを確認して生成を開始します。
ComfyUIの生成開始画面で、各種パラメータを変更していきます。
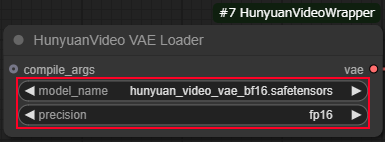
HunyuanVideo VAE Loader
・model_nameにhunyuan_video_vae_bf16.safetensors
・precisionにfp16
を選択します。
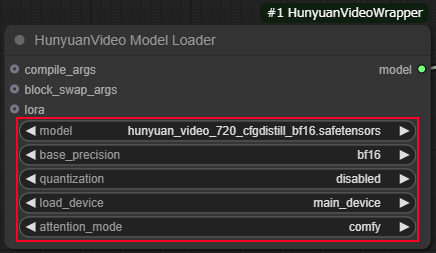
HunyuanVideo Model Loader
・quanlizationを「disabled」
・load deviceを「main_device」
・attention_modeを「comfy」
に設定します。
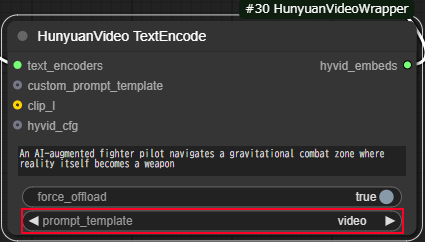
HunyuanVideo TextEncode
・prompt_templateに「video」を選択します。
その他のパラメータはデフォルトのままで問題ありません。
画面上部の▷Queueボタンの右側に数字を入力する欄あるので生成したい動画の本数を指定します。
その後「Queue」ボタンをクリックして生成を開始します。
(masterpiece, best quality, high quality, highres, ultra-detailed),(8K,top-quality:1.2),anime,ultra-detailliert, (1boy:1.4), solo, silver hair,upper body, (smiling:1.2), looking at viewer, walking towards the camera
HunyuanVideo(ComfyUI)で生成した動画

スポンサーリンク
HunyuanVideoの料金プランと商用利用は?

HunyuanVideoの料金プランと商用利用に関して紹介します。
HunyuanVideoの公式プロジェクトはApache 2.0 ライセンスでリリースされていて、自由にコードを利用することができます。
Tencent Hunyuan Community License Agreementによると、モデルに関する規約は以下の通りです。
1.改変と派生物
・モデルの改変は可能ですが、改変後のモデルは「派生物」として扱われます。
・改変内容については、明確に「改変したこと」を示す必要があります。
・改変したモデルや派生物をTencent Hunyuan以外のAIモデルで使用することは禁止されています。
2.配布
・モデルやその派生物を配布することは可能です。
・配布する際には、第三者にこのライセンス契約のコピーを提供しなければなりません。
・改変したファイルには必ず「改変した」ことを明示する必要があります。
・配布物には、「Tencent HunyuanはTencent Hunyuan Community License Agreementの下でライセンスされています」というテキストファイル(Notice)を含める必要があります。
これらのポイントを守ることで、ライセンスの条件に従ってモデルを使用および配布することができます。
HunyuanVideoの商用利用は?
Tencent Hunyuan Community License Agreementによると、商用利用は特許使用以外可能とコメントされています。
例外として月間のサービス利用者数が合計で1億人を超える場合、Tencentからライセンスを取得する必要があります。
また、Tencent Hunyuan Worksを商用プロダクトに利用する場合、「Powered by Tencent Hunyuan」の記載が推奨されています。
概要は以下の通りです。


HunyuanVideoのような動画生成AIにはクラウドGPUがおすすめ

HunyuanVideoをスムーズに利用するには、高スペックなパソコンが必要です。
ただし、HunyuanVideoを快適に利用できるような高性能なパソコンは、ほとんどが30万円以上と高額になります。
コストを抑えたい方へ:クラウドGPUの利用がおすすめ
クラウドGPUとは、インターネット上で高性能なパソコンを借りることができるサービスです。これにより、最新の高性能GPUを手軽に利用することができます。
クラウドGPUのメリット
- コスト削減:高額なGPUを購入する必要がなく、使った分だけ支払い
- 高性能:最新の高性能GPUを利用できるため、高品質な画像生成が可能
- 柔軟性:必要なときに必要なだけ使えるので便利

HunyuanVideoを使いこなして動画生成AIをマスターしよう!
今回は、Tencentが公開した動画生成AI「HunyuanVideo」の使い方について紹介しました。
HunyuanVideoは、従来の動画生成サービスと比較して、最も最先端で使いやすいプロジェクトです。
無料で利用できる動画生成AIのオープンソースの中でトップクラスなので、このチャンスに高性能ツールで動画生成を極めてみましょう。







