
ComfyUIは、ノードベースのワークフローを自由に組むことができる生成AIツールです。
プロセスの可視化や操作が直感的に行える点が大きな特徴で、カスタマイズ性にも優れています。また、Stable Diffusionをはじめとする多様な生成AIにも対応しており、幅広い用途で活用可能です。
この記事では、ComfyUIのインストール方法から具体的な使い方までをわかりやすく解説します。
ComfyUIとは

ComfyUIとは、Stable Diffusionなどの生成AIプログラムを操作するためのオープンソースツールです。
コーディングの知識が不要で、動作環境への負担も軽い設計となっており、安心して利用できます。
さらに、豊富なカスタマイズオプションを備えており、Stable Diffusion以外の生成AIにも対応した多様なワークフローが公開されています。


Stable Diffusionの使い方は、機能別に下記の記事にまとめているのでぜひご覧ください

ComfyUIのインストール手順

ここでは、ComfyUIをインストールする手順を詳しく解説します。
今回は、WindowsのローカルPCにインストールする方法と、GPUSOROBAN(Linuxのクラウド環境)にインストールする方法の2つを紹介します。
それぞれの環境に合わせた手順を参考にして、スムーズにComfyUIのセットアップを進めましょう。
WindowsPCにインストールする方法
まずは、GitHubのComfyUI公式ページにアクセスし、必要なデータをダウンロードします。
Windows PCの場合、GPUを搭載しているPC向けと、非搭載のPC向けに分かれているため、自身の環境に適したバージョンを選びましょう。
ページの中部の「Installing」の項目からComfyUIの圧縮ファイルを探します。
「Direct link to download」をクリックすると、データのダウンロードが開始します。
データのダウンロードが完了するまで待ちます。
※ ファイルサイズは約1.3GBと比較的大きいので、安定したインターネット接続環境でのダウンロードをおすすめします。
ダウンロードが完了したらデータを解凍します。
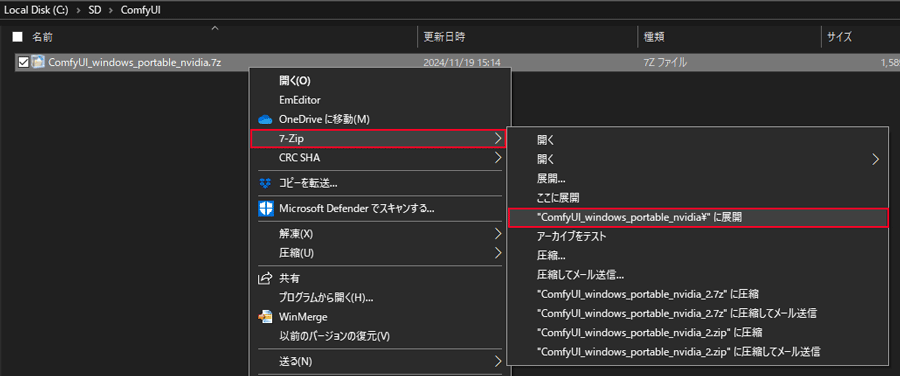
ファイルは 7-zip の形式で圧縮されてますので、専用の圧縮・解凍ソフトの利用がおすすめです。
解凍後の「ComfyUI_windows_portable_nvidia_cu121_or_cpu」フォルダを開きます。この中にある「ComfyUI_windows_portable」がソフトウェアの本体です。
ファイル名が長すぎたり、日本語を含むディレクトリに配置すると、エラーが発生する可能性があります。そのため、シンプルでアクセスしやすい場所に移動することをおすすめします。
例: Cドライブ直下に「SD」というフォルダを作成し、その中に「ComfyUI_windows_portable」を移動。
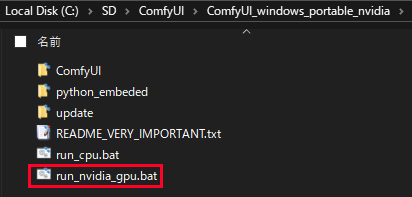
設置が完了したら「run_nvidia_gpu.bat」をダブルクリックして、ソフトを起動します。
起動後、既定のブラウザが自動で開き、ComfyUIの画面が表示されます。
GPUSOROBANにインストールする方法

ここでは、インターネット上で高性能なGPUを利用できるクラウドサービス「GPUSOROBAN」にComfyUIをインストールする方法を解説します。
まず、GPUSOROBANを利用するために、会員登録からセットアップまでを完了させる必要があります。
詳しい手順については、以下のリンクをご参照してください。
PUSOROBANの会員登録とセットアップ方法
GPUSOROBAN起動チュートリアルに従い、インスタンスの起動とSSH接続を完了させます。
「user@<インスタンス名>:~$」が表示されたら、インスタンスへの接続が正常に完了したことを確認できます。
次に、GPUSOROBANのGPUインスタンス内にComfyUI専用の環境を作成します。
今回はMinicondaのConda環境を使ってComfyUIをセットアップしていきます。
conda create -n comfy python=3.10
conda activate comfy
pip install torch==2.5.1+cu118 torchvision --extra-index-url https://download.pytorch.org/whl/cu118ComfyUIの推奨バージョンはpython 3.10ですので、プロジェクト名を「Comfy」にしてGPUSOROBANのセットアップ通りに進めて完了すれば問題ありません。
インスタンスを起動した状態でComfyUIをインストールします。
$の後に以下のコマンドを入力します。
git clone https://github.com/comfyanonymous/ComfyUI.git

先ほど構築したComfyUI専用環境に切り替えてComfyUI最新版をインストールします。
conda activate comfy
cd ComfyUI
pip install -r requirements.txt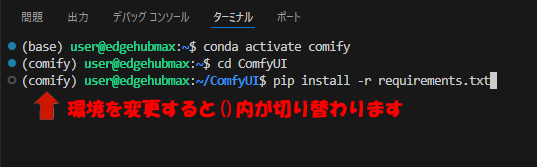
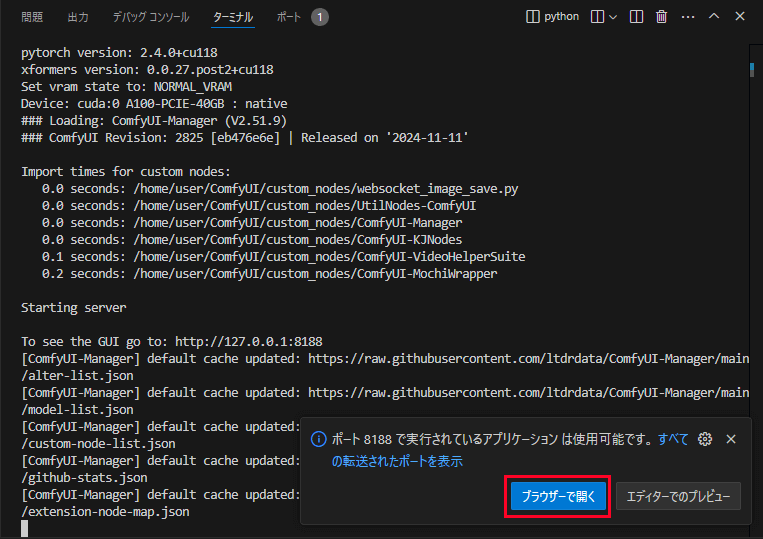
次のコマンドを実行してComfyUIを起動します。
python main.py
デバイス上の割り当てが失敗して起動がうまく行かない場合は–disable-cuda-mallocのオプションを付けて起動します。
python main.py --disable-cuda-malloc
ブラウザで開くボタンをクリックして起動完了になります。
ComfyUIの使い方
ここからはComfyUIの基本的な使い方を解説していきます。
Stable Diffusionの画像生成を例に以下のステップで、まずは基本的な使い方をマスターしましょう。
ComfyUIを起動した画面で何も表示されていない場合は「Load Default」ボタンをクリックします。
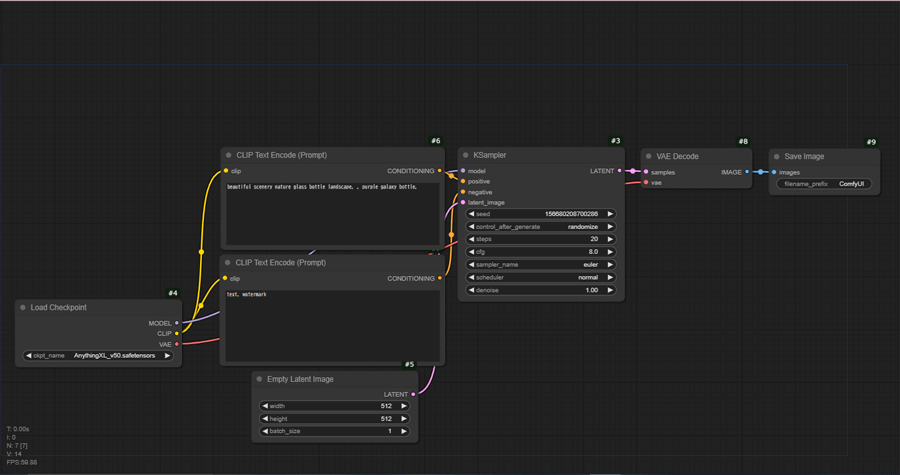
デフォルトのワークフローが再読み込みされて、Stable Diffusionのワークフローが表示されます。
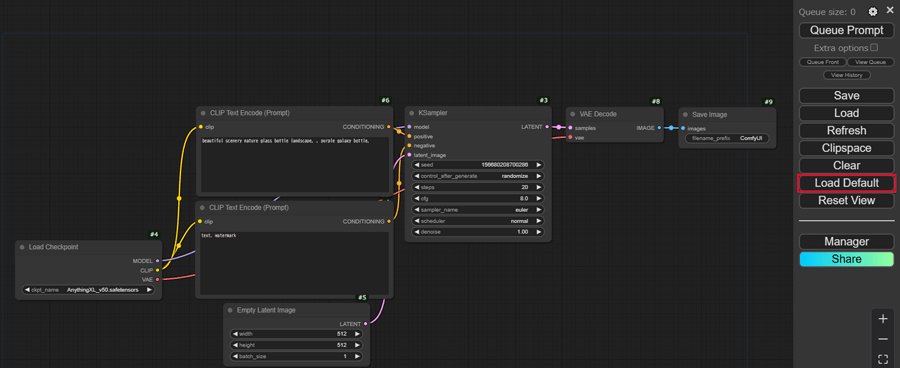
Stable Diffusionのワークフローは、各ノードで処理系統ごとに分かれていて、それぞれ線で繋がれています。
先頭からノードの役割を見ていきます。
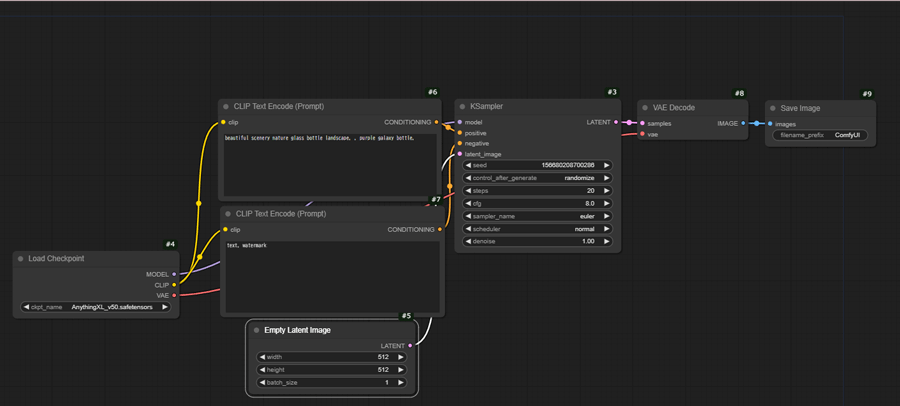
#4 Load Checkpoint
Stable Diffusionのモデルを選択します。▶でモデルデータの切り替えができます。
#6#7 CLIP Text Encode(Prompt)
プロンプトとネガティブプロンプトの入力欄です。
#5 Empty Latent Image
画像のサイズ指定とバッチ回数を指定します。
#3 KSampler
シード値やステップ数など画像を構成する要素を入力します。
#8 VAE Decode
生成画像を pixel 画像に変換します。Stable DiffusionのVAEを含める要素とは異なります。
#9 Save Image
生成された画像を保存します。
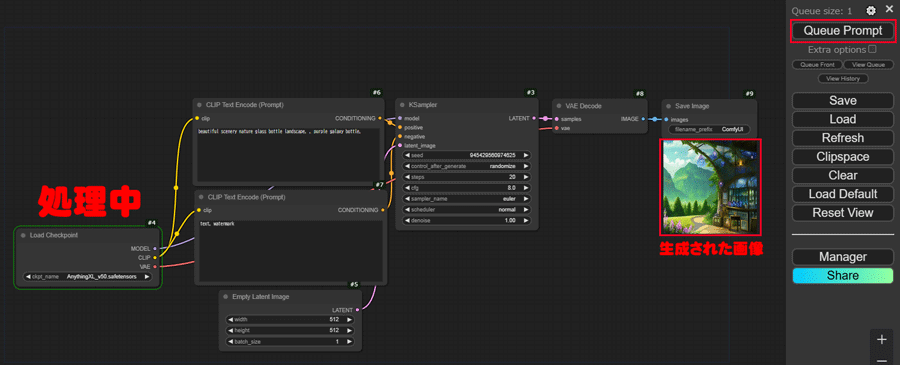
実際に画像を生成してみましょう。
右側にあるパネル上部の「Queue Prompt」ボタンをクリックして生成を開始します。
現在入力されている数値は、デフォルト値のままで問題ありません。
生成処理が開始されると、緑色の枠が表示され、進行状況をリアルタイムで確認できます。
生成が完了すると「#9 Save Image」モードの下に画像が表示されます。
拡張機能ComfyUI Manager
ComfyUIを使い始める際に、まず導入しておきたい拡張機能がComfyUI Managerです。
ComfyUI Managerは、ComfyUIのカスタムノードやツールを一括で管理するための便利な拡張機能です。これを利用することで、カスタマイズやアップデートの管理もスムーズに行えます。
インストール方法は、カスタムノードフォルダ内で下記コマンドを入力すれば完了です。
WindowsPCの場合
「SD」>「ComfyUI」>「custom_nodes」フォルダを開きます。
フォルダ内で右クリックして「Git Bash here」でコマンド画面を表示して下記コマンドを入力します。
git clone https://github.com/ltdrdata/ComfyUI-Manager.git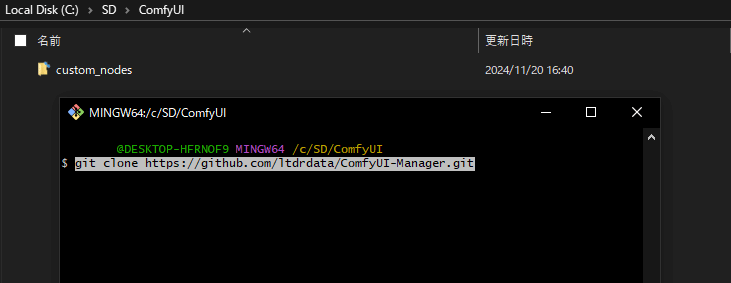
GPUSOROBAN(Linuxのクラウド環境)
「ComfyUI」>「custom_nodes」で開き、クローンを実行します。
cd ComfyUI/custom_nodes
git clone https://github.com/ltdrdata/ComfyUI-Manager.gitComfyUIを再起動して、右のパネルに「Manager」ボタンが表示されていれば、インストールは完了です。
FLUX.1を使う

ComfyUIでFLUX.1を使って画像を生成する方法を解説します。
FLUX.1を利用するには、専用の学習モデルデータをHugging Faceからダウンロードしてセットアップする必要があります。
FLUX.1が搭載された学習モデルのデータをHugging Faceからダウンロードします。
「ComfyUI」で生成に使用するファイルは下記の4つです。
モデル: flux1-schnell.safetensors (23.8GB)
テキストエンコーダー: t5xxl_fp8_e4m3fn.safetensors (4.89GB)
クリップ: clip_l.safetensors
VAE: ae.safetensors
ダウンロードしたデータをフォルダにセットします。
「models」>「unet」フォルダに「flux1-schnell.safetensors」を配置。
「models」>「clip」フォルダに「t5xxl_fp8_e4m3fn.safetensors 」と「clip_l.safetensors」を配置。
「models」>「vae」フォルダに「ae.safetensors」 を配置。
画像付きの導入方法はこちらの記事を参考にしてみて下さい。
FLUX.1専用のワークフローを利用するために、公式サイトからデモ画像をダウンロードします。
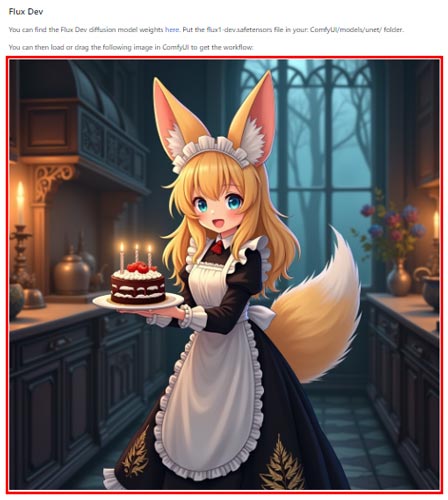
ダウンロードした画像をComfyUIの画面にドラッグ&ドロップで画像を読み込むと埋め込まれているワークフローデータを表示することができます。
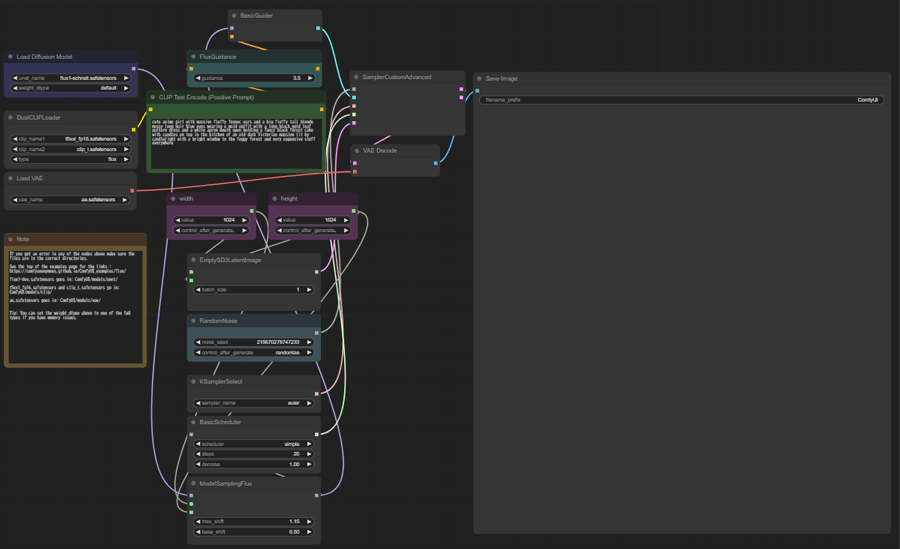
ComfyUIの生成画面で、必要なパラメータを設定して画像生成を始めましょう。
- UNETローダーの設定
UNET名:flux1-schnell.safetensorsを選択します。 - デュアルCLIPローダーの設定
CLIP1:t5xxl_fp8_e4m3fn.safetensorsを選択します。
CLIP2:clip_l.safetensorsを選択します。 - VAEローダーの設定
VAE名:ae.safetensorsを選択します。 - CLIPテキストエンコーダーの設定
プロンプトを入力します。
ネガティブプロンプト:入力不要です。 - 画像サイズとパラメータの確認
画像サイズ:デフォルトの 1024×1024 のままでOKです。
その他のパラメータ:デフォルト設定を使用します。
パラメータ設定後、右上の「Queue Prompt」ボタンをクリックして生成を開始します。
FLUX.1(ComfyUI)で生成した画像


LoRAを使う
ComfyUIでLoRAを使用するには、ノードを手動で追加する必要があります。
以下の手順に従って設定を行いましょう。
LoRA モデルのデータは、「ComfyUI」>「models」>「loras」の順で開き、データを格納します。
空きスペースで右クリックして、Add Node>loaders>Load LoRAを選択します。
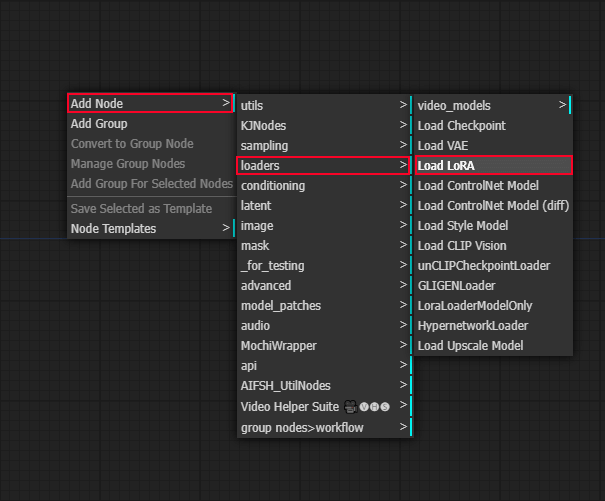
次に作成したLoad LoRAノードにコードを繋げます。
先頭のLoad Checkpoint横にLoad LoRAノードを配置して。MODELとCLIPに下図のように接続します。
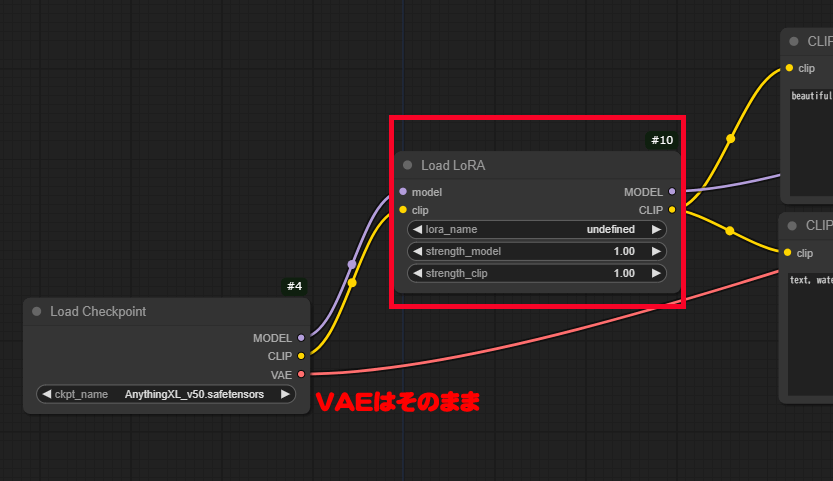
LoRAモデルファイルを選択して生成を開始します。
Strength_model と Strength_clip の値を調整します。
推奨範囲:0.8 ~ 1.3
強度を調整することで、LoRAの影響度をコントロールできます。
ComfyUIでupscale同様の機能を実現する方法
ここでは、ComfyUIを使って生成する画像をアップスケール(高解像度化)する方法を解説します。
Stable Diffusion Web UIの「Hires.fix」を再現する形で進めます。
デフォルトの画像生成ワークフローを開き、以下のノードを手動で追加します。
Add Node > latent > Upscale Latent
Add Node > sampling > Ksampler
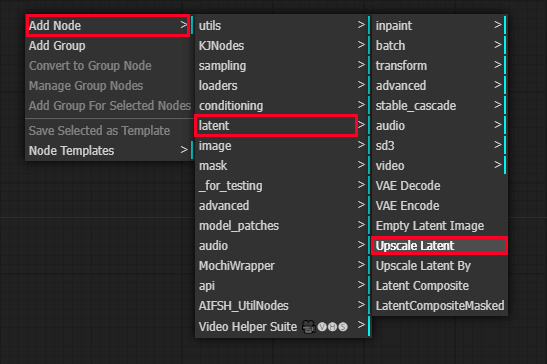
今回は、この2つのノードを使います。
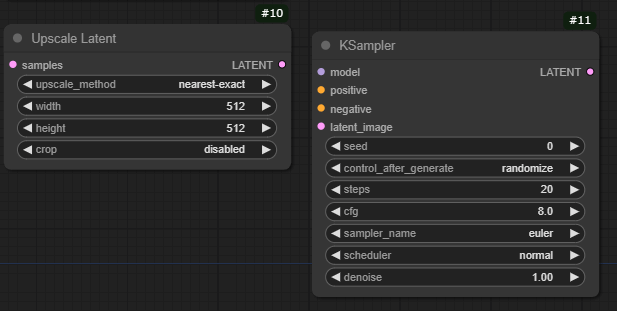
次に、追加したノードを線で接続してワークフローを作成します。
1.Ksampler (#3) → Upscale Latent
元からある #3 Ksampler の LATENT から Upscale Latent の LATENT に接続します。
2.Upscale Latent → 新しい Ksampler (#11)
Upscale Latent の LATENT 出力から、新たに追加した #11 Ksampler の LATENT image に接続します。
3.新しい Ksampler (#11) → VAE Decode
追加した#11のKsamplerからVAE Decodeのsamplesに線をつなぎます。
このように3か所を接続します。
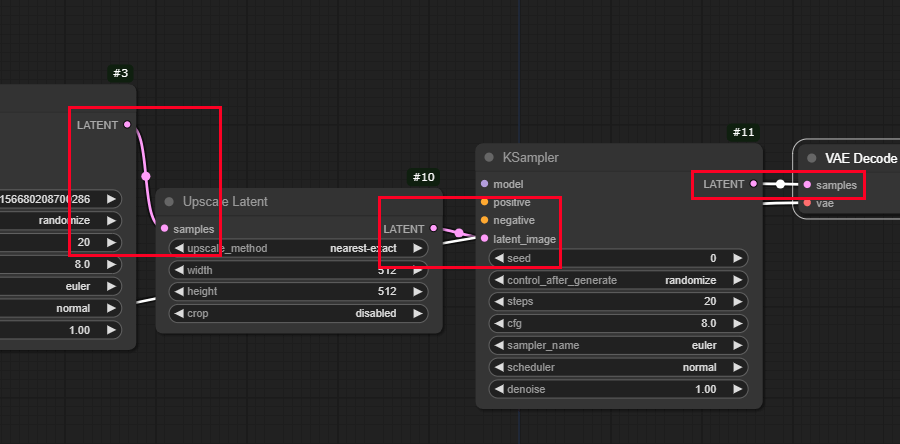
最後に、#1のmodelノード /#6 CLIP Text Encode(プロンプト) ノード / #7CLIP Text Encode(ネガティブプロンプト) ノードを新たに追加した#11のKsamplerに接続します。
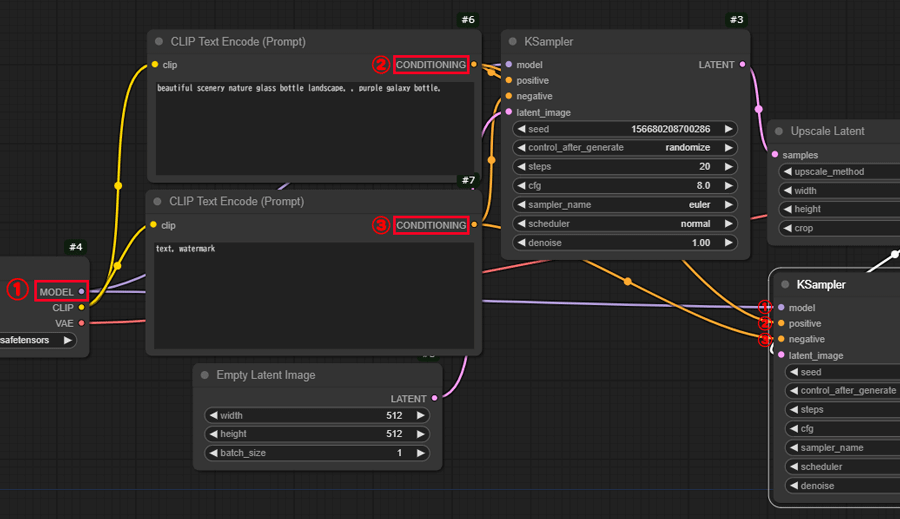
ノードの設置が完了したら、右側パネルの「Queue Prompt」をクリックして、画像生成を開始します。
高解像度の画像が生成されました。
例:通常の 512px × 512pxの画像をアップスケールして768px×768pxにしても、画質がしっかりと維持されました。

ComfyUIでADetailer同様の機能を実現する方法
ComfyUIには、顔の補正や表情差分をコントロールできる拡張機能「ADetailer」に似た機能、「Facedetailer」があります。
ここでは、Facedetailerの使い方を解説します。
Facedetailerは、拡張機能「ComfyUI-Impact-Pack」に含まれています。このパッケージをインストールしましょう。
右パネルのManagerメニューからCustom Nodes Managerを選択します。
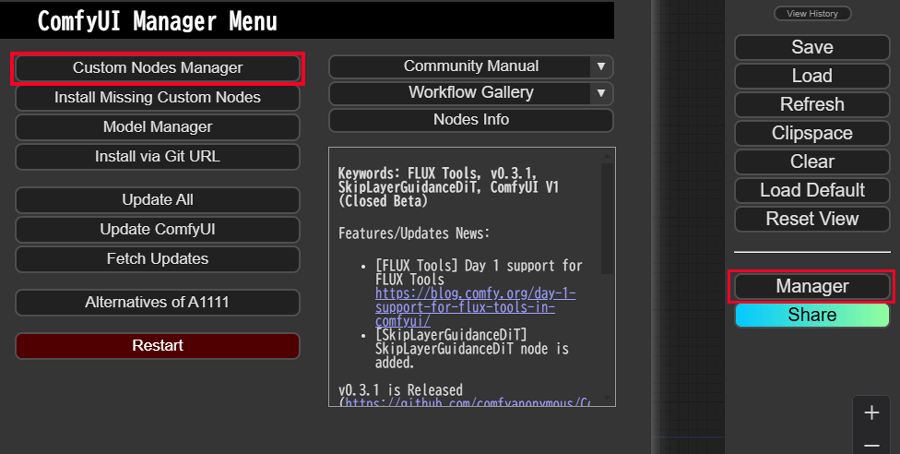
検索欄にComfyUIを入力すると上の方にComfyUI-Impact-Packが出てくるので、インストールボタンをクリックして進めます。
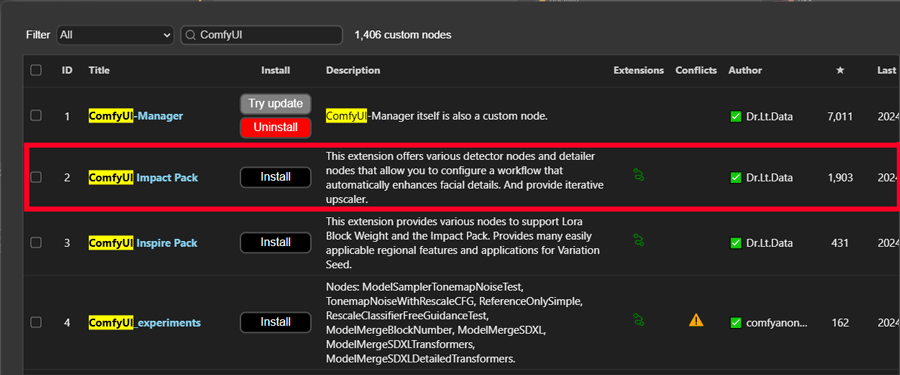
インストール完了したらリスタートボタンをクリックしてComfyUIを再起動します。
次に、Facedetailerに必要なノードを追加して、ワークフローを作成します。
デフォルトのワークフローを表示し、背景をダブルクリックしてFacedetailerを検索してノードを追加します。
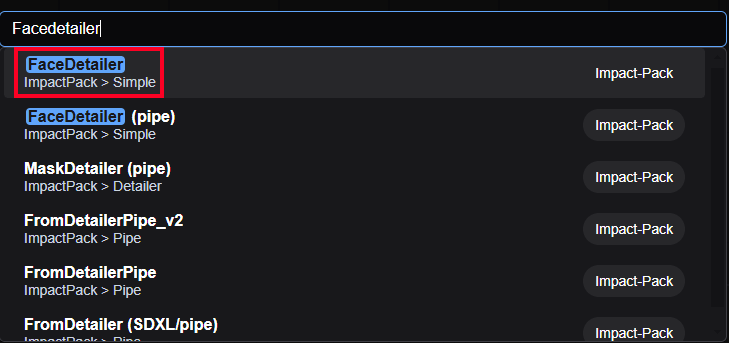
同様に以下のノードも追加します。
- UltralyticsDetectorProvider
- SAMLoader
- Load Image
すべてのノードを追加したら、以下のように接続します。
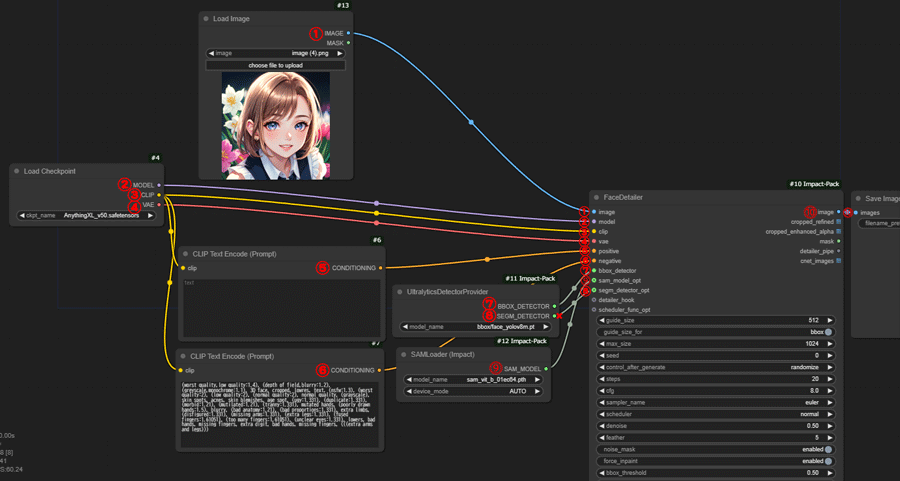
接続されていない余分なノードは削除して構いません。
プロンプトには表情に関する内容のみを入力して生成を開始します。さまざまな差分画像が生成できました。


ComfyUIを快適に活用するならクラウドGPUがおすすめ

ComfyUIを快適に利用するなら、クラウドGPUの利用がおすすめです。
クラウドGPUとは、インターネット上で高性能なパソコンを借りることができるサービスで、最新の高性能GPUを手軽に利用することが可能です。
さらに、クラウドGPUの料金は使用時間に応じて加算されるため、停止している間は料金がかかりません。
クラウドGPUのメリット
- コスト削減:高額なGPUを購入する必要がなく、使用した分だけの支払い
- 高性能:最新の高性能GPUを利用できるため、高品質な画像生成が可能
- 柔軟性:必要なときに必要なだけ使えるので便利
こんな人におすすめ
- 少ない予算でComfyUIを快適に使いたい人
- 自分のパソコンの性能が不足していると感じる人
- 常に最新の高性能GPUを使いたい人
GPUSOROBAN
GPUSOROBANは、高性能なGPU「NVIDIA A4000 16GB」を業界最安値の1時間50円で使用することができます。
さらに、クラウドGPUを利用しない時は停止にしておくことで、停止中の料金はかかりません。
クラウドGPUを使えばいつでもStable Diffusionの性能をフルに引き出すことができるので、理想の環境に近づけることができます。
\快適に生成AI!1時間50円~/






