
VectorSpaceLabは、マルチモーダル画像生成AIモデル「OmniGen」を2024年11月にリリースしました。
「OmniGen」は、単一のフレームワークで多様な生成作業を実行可能にすることを目指して開発されています。
この記事では、初心者向けに「OmniGen」の概要とローカル環境での使い方を詳しく解説します。
OmniGenとは?
OmniGenは、さまざまなタスクに対応可能な統合型画像生成モデルです。
従来のStable Diffusionなどの画像生成AIモデルにおいては、操作の複雑さが実用性を下げることになってしまうのが課題でした。
OmniGenは、この問題を解決するために設計されたプロジェクトで、複雑なタスクを簡単な操作で実行することができます。
OmniGenの大きな特徴は下記の3つです。
- 多様な画像生成タスクを統一的に処理可能に!
- 大規模言語モデル(LLM)の利用により、テキストだけで簡単に画像が生成できる!
- 多様な画像生成タスクを単一モデルで実行できる!
多様な画像生成タスクを統一的に処理可能に!
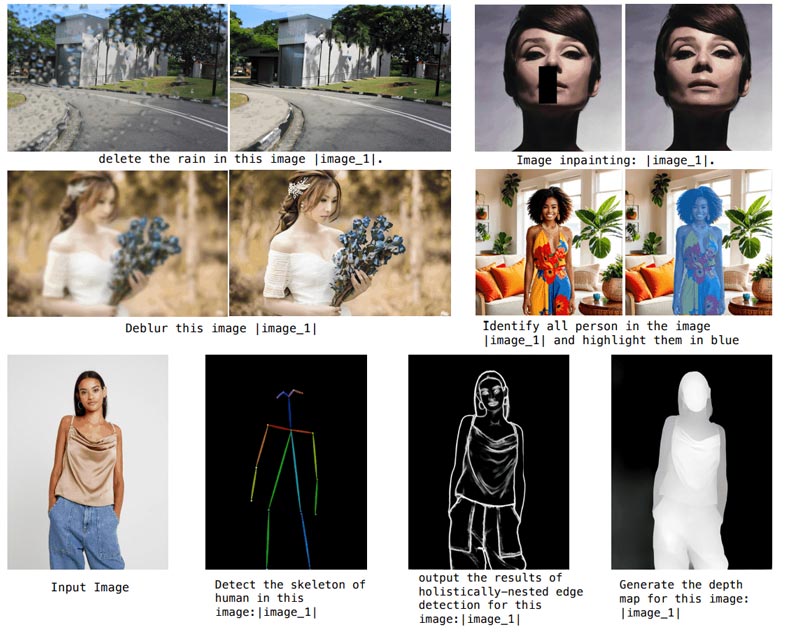
OmniGenは、画像の編集と生成のプロセスを効率化することを目的に作られた生成AIモデルです。
複雑な生成作業を伴うControlNetのような拡張機能を使用せず、基本モデルだけで直感的な生成を可能にします。
さらに、テキストだけでなく、画像をプロンプトとして利用できるため、創作の幅が広がります。
大規模言語モデル(LLM)の利用により、テキストだけで簡単に画像が生成できる!

OmniGenは、大規模言語モデル(LLM)を使用しており、ユーザーのテキスト入力だけで簡単に画像を編集できます。
複雑な処理に対しても理解力の高いLLMによって的確に処理が進められるので、これまでのように複雑なオブジェクト条件を指定する必要がなく、初心者でも簡単に使いこなせます。
多様な画像生成タスクを単一モデルで実行できる!

OmniGenは、テキストと画像の両方を条件として受け入れ、さまざまな画像生成タスクを1つのモデルで実行することができます。
このモデルは追加のエンコーダを必要とせず、テキストと画像を単一のモデルで処理します。その結果、既存のモデルよりもシンプルでユーザーフレンドリーなものとなっています。
また、最大3つの参照画像をアップロードして、新しい画像を生成することも可能です。


Stable Diffusionの使い方は、機能別に下記の記事にまとめているのでぜひご覧ください

OmniGen ComfyUIでの始め方・使い方

ここでは、「ComfyUI」上でのOmniGenの始め方から使い方まで紹介します。
OmniGenは、多くのGPUパワーが必要になりますので、余裕をもって準備をしておきましょう。
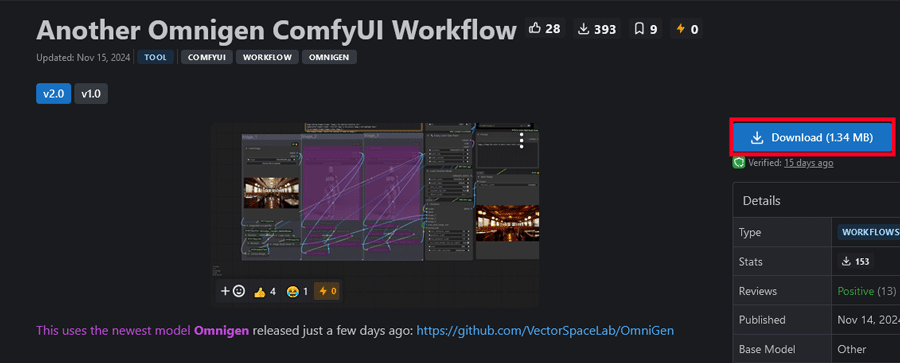
今回はcivitaiで公開されている「Another Omnigen ComfyUI Workflow」を使って画像を生成します。
まずは、ページ内のワークフローデータを先にダウンロードします。
次に、OmniGen専用の環境を設定します。
OmniGenは、Python、PyTorch、CUDAのバージョンにそれぞれ推奨設定がありますので、conda環境を利用し整えます。
同じPC内で異なるプログラムのバージョンを利用するには、ソフト専用の環境を作ります。そうすることでパッケージの競合を防ぐことができます。
下記のコマンドを入力して環境を新規で構築します。
conda create -n omnigen python=3.10.13
conda activate omnigen
pip install torch==2.3.1+cu118 torchvision --extra-index-url https://download.pytorch.org/whl/cu118環境の設定が完了したらデータのインストールに進みます。
「ComfyUI」>「models」を開き、下記のコマンドを入力してOmniGenをインストールします。
git clone https://github.com/VectorSpaceLab/OmniGen.gitOmniGenのフォルダが作成できたら、「ComfyUI」>「models」>「OmniGen」を開き、必要な追加データを入手します。
pip install -r requirements.txtデータのセットが完了したらComfyUIを再起動してOmniGen用に足りないノードを補充していきます。
ダウンロードしたワークフローデータ(Omnigen 2a.json)をComfyUIの画面にドラッグ&ドロップで読み込みます。
ポップアップでメッセージされている赤くなっている部分が未入手のカスタムノードなので、一つずつ補填していきます。
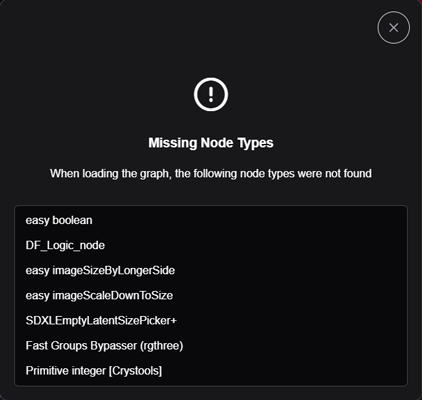
右のパネルの「Manager」ボタンをクリックして、中列の「Install Missing Custom Nodes」を選択します。
足りないカスタムノードが一覧で表示されるので、すべてのノードをインストールします。
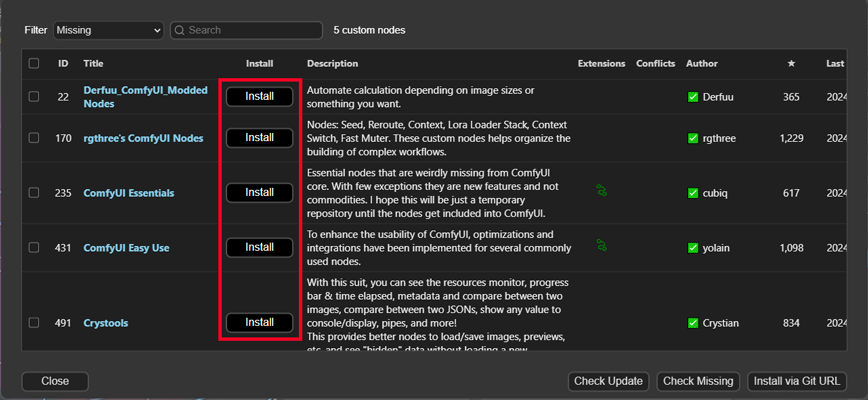
完了したらリスタートボタンをクリックして「ComfyUI」を再起動します。
再起動後、赤いノードがないことを確認して生成を開始します。
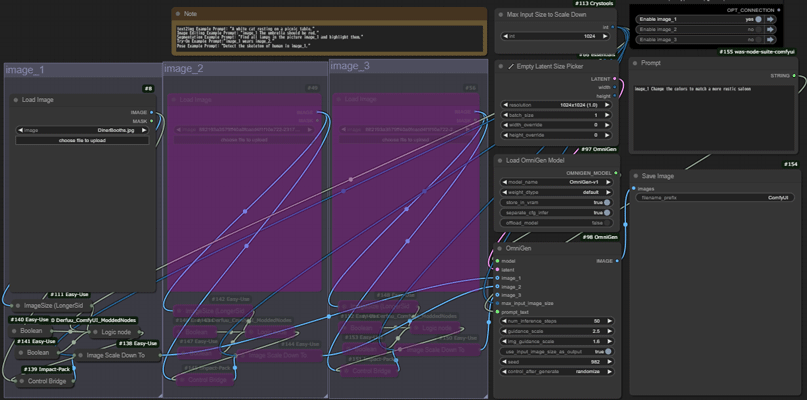
OmniGenの特徴は、素材の画像をプロンプトの内容に変更・アレンジすることです。
まずは素材の画像を用意して読み込み、変更したい内容をプロンプトに入力します。

image_1
・image_1に素材の画像を読み込みます
choose file to uploadでファイルをアップします。
その他のパラメータはデフォルト値で問題ありません。
Prompt
・変更内容を含めたプロンプトを入力します。
プロンプト内にimage_1を必ず含めます。
今回は素材の画像の背景をお城が見えるように変更します。
各種のパラメータやプロンプト以外の入力項目やパラメータは、入力しなくても問題ありません。
生成は右上の「Queue Prompt」ボタンをクリックします。
初回の生成はモデルデータのダウンロードを伴うので時間がかかります。
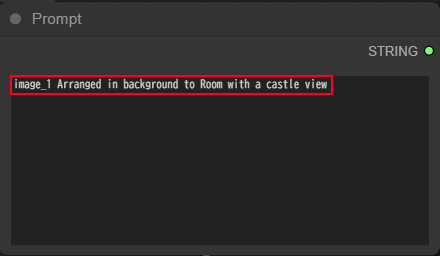
image_1 Arranged in background to Room with a castle view


スポンサーリンク
OmniGenの料金プランと商用利用は?

OmniGenの料金プランと商用利用に関して紹介します。
OmniGenの公式プロジェクトはApache 2.0 ライセンスでリリースされていて、自由にコードを利用することができます。
Huggingfaceでは、無料で生成が試せるオンラインデモページが公開されています。
OmniGenの商用利用は?
OmniGen公式GitHubでは、「個人使用および商用使用に自由に利用できます」とコメントされています。
OmniGenで生成された画像は、他の人の肖像画や関連写真を使用して許可なく生成しない限り、商用目的で使用できます。
概要は以下の通りです。


OmniGenを使いこなして生成AIをマスターしよう!
今回は、VectorSpaceLabが公開したマルチモーダル画像生成AI「OmniGen」の使い方について紹介しました。
OmniGenは、従来の画像生成サービスと比較して、最も最先端で画像生成における様々な機能が内包されています。
無料で利用できる画像生成AIのオープンソースの中でトップクラスなので、このチャンスに高性能ツールで画像生成を極めてみましょう。








