
Reflection Llama-3.1 70Bは、自己修正機能を持つ「Reflection-Tuning」でトレーニングされたLLMです。
推論中に誤りを検出し修正することで、高い精度と生成過程の透明性を実現し、Claude 3.5 SonnetやGPT-4oに匹敵する性能があります。
この記事では、Reflection Llama-3.1 70Bの性能から商用利用、使い方まで紹介します。
ざっくり言うと
- 推論中に誤りを修正することで、高い精度と透明性を実現
- Claude 3.5 SonnetやGPT-4oに匹敵する性能
- 性能、商用利用、使い方まで解説

Reflection Llama-3.1 70Bとは

Reflection Llama-3.1 70Bは、Llama 3.1 70Bモデルをベースに、自己修正機能を持つ「Reflection-Tuning」でトレーニングされたLLMです。
このモデルは、推論中に誤りを検出し修正することで、より高い精度と生成過程の透明性を実現します。
Claude 3.5 SonnetやGPT-4oなどのモデルに匹敵する性能を持つオープンソースモデルです。
Llama3.1については別の記事で詳しく解説しています。


Reflection Llama-3.1 70Bのモデル

Reflection Llama3.1 70Bは、700億パラメータのモデルがHuggingFaceで公開されています。
この記事では、Ollamaで公開されているGGUFフォーマットのモデルを使用します。
| モデルID | パラメータサイズ | GPUメモリ | 公開 |
|---|---|---|---|
| mattshumer/Reflection-Llama-3.1-70B | 700億パラメータ | 42GB | HuggingFace |
Reflection Llama-3.1 70Bの性能

Reflection Llama-3.1 70Bは、主要なベンチマークにおいて、GPT-4oやClaude 3.5 Sonnetといったモデルに対して優れたパフォーマンスを発揮しています。
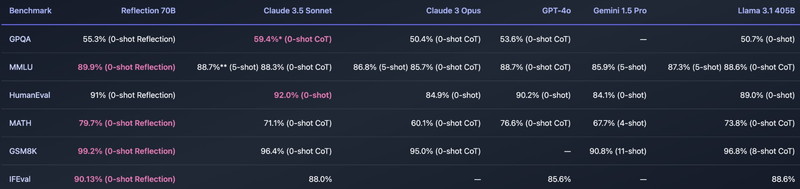
GPQA(一般知識に関するクエリ):
- Reflection 70Bは55.3%の正解率を達成しており、「0-shot Reflection」として事前情報なしでモデルの推論能力を測定しています。他のモデルと比較すると、Claude 3.5 Sonnetが59.4%とわずかに高い結果を示していますが、他のモデルも50%前後であり、Reflection 70Bも十分に高いパフォーマンスを発揮しています。
MMLU(マルチタスク学習):
- 複数の分野にまたがる問題に対する理解力を測定するこのベンチマークで、Reflection 70Bは89.9%の正解率を示しており、他のモデルに比べても非常に高いパフォーマンスを発揮しています。Claude 3.5 SonnetやGPT-4oと比べて、Reflection 70Bがわずかに優れた結果を出しています。
HumanEval(コード生成タスク):
- プログラミング問題に対するモデルの解答精度を測定するこのベンチマークで、Reflection 70Bは91%のスコアを達成しており、Claude 3.5 Sonnetの92%とほぼ同等の結果を示しています。
MATH(数学に関する問題):
- Reflection 70Bは79.7%の正解率を示しており、他のモデルに対しても優れた結果を示しています。
GSM8K(数学的な問題解決能力):
- Reflection 70Bは99.2%という非常に高いスコアを記録しており、他のモデルに比べて最も優れた結果を示しています。
IFEval(一般的な推論力):
- Reflection 70Bは90.13%を示しており、他のモデルと比較しても非常に高いパフォーマンスを発揮しています。
Reflection Llama-3.1 70Bの商用利用・ライセンス

Reflection Llama-3.1 70Bは、「META LLAMA 3.1 COMMUNITY LICENSE」にもとづいて、無料で利用でき、商用利用も可能です。
商用利用:ソフトウェアやコードを商用利用することが許可されています。
改変:ソフトウェアやコードを自由に修正したり改変したりすることができます。
配布:修正したり変更したりしたソフトウェアを自由に配布することができます。
著作権表示:再配布時に、著作権の表示や契約書コピーの提供などが必要になります。
特許利用:特許利用に関する明示的な規定はありません。
詳細は「META LLAMA 3.1 COMMUNITY LICENSE」のページをご確認ください。
Reflection Llama-3.1 70Bの実行環境

この記事で用意した実行環境は以下のとおりです。
- GPU:NVIDIA A100 80GB
- GPUメモリ(VRAM):80GB
- OS :Ubuntu 22.04
- Docker
Dockerで環境構築
Dockerを使用してLangChainの環境構築をします
Dockerの使い方は以下の記事をご覧ください。

Ubuntuのコマンドラインで、Dockerfileを作成します。
mkdir reflection_70b
cd reflection_70b
nano DockerfileDockerfileに以下の記述を貼り付けます。
# ベースイメージ(CUDA)の指定
FROM nvidia/cuda:12.1.0-cudnn8-devel-ubuntu22.04
# 必要なパッケージをインストール
RUN apt-get update && apt-get install -y python3-pip python3-venv git nano curl
RUN curl -fsSL https://ollama.com/install.sh | sh
# 作業ディレクトリを設定
WORKDIR /app
# アプリケーションコードをコピー
COPY . /app
# Python仮想環境の作成
RUN python3 -m venv /app/.venv
# 仮想環境をアクティベートするコマンドを.bashrcに追加
RUN echo "source /app/.venv/bin/activate" >> /root/.bashrc
# JupyterLabのインストール
RUN /app/.venv/bin/pip install Jupyter jupyterlab
# LangChain関連のインストール
RUN /app/.venv/bin/pip install ollama langchain-ollama langchain langsmith langchain-chroma faiss-gpu langchain-community langchain_huggingface langchain_core tiktoken
# コンテナの起動時にbashを実行
CMD ["/bin/bash"]FROM nvidia/cuda:12.1.0-cudnn8-devel-ubuntu22.04
CUDA12.1のベースイメージを指定しています。
RUN apt-get update && apt-get install -y python3-pip python3-venv git nano curl
必要なパッケージをインストールしています。
RUN curl -fsSL https://ollama.com/install.sh | sh
Linux版のOllamaをインストールしています。PythonでOllamaを動かす際にもLinux版Ollamaのインストールが必要になりますのでご注意ください。
RUN /app/.venv/bin/pip install Jupyter jupyterlab
JupyterLabをインストールしています。
RUN /app/.venv/bin/pip install ollama langchain-ollama langchain langsmith langchain-chroma faiss-gpu langchain-community langchain_huggingface langchain_core tiktoken
LangChainとOllama関連のパッケージをインストールしています。
LLMはOllamaのライブラリを使って動かしますので、PyTorchやTransformerは別途インストール不要です。
docker-compose.ymlでDockerコンテナの設定をします。
docker-compose.ymlのYAMLファイルを作成して開きます。
nano docker-compose.yml以下のコードをコピーして、YAMLファイルに貼り付けます。
services:
reflection_70b:
build:
context: .
dockerfile: Dockerfile
image: reflection_70b
runtime: nvidia
container_name: reflection_70b
ports:
- "8888:8888"
volumes:
- .:/app/reflection_70b
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: 1
capabilities: [gpu]
command: >
bash -c '/usr/local/bin/ollama serve & /app/.venv/bin/jupyter lab --ip="*" --port=8888 --NotebookApp.token="" --NotebookApp.password="" --no-browser --allow-root'bash -c ‘/usr/local/bin/ollama serve & /app/.venv/bin/jupyter lab –ip=”*” –port=8888 –NotebookApp.token=”” –NotebookApp.password=”” –no-browser –allow-root’
bash -c '/usr/local/bin/ollama serve
Ollama Serverを起動しています。PythonのOllamaを使用する際に、Ollama Serverを起動しておく必要がありますので、ご注意ください。
& /app/.venv/bin/jupyter lab --ip="*" --port=8888 --NotebookApp.token="" --NotebookApp.password="" --no-browser --allow-root'
JupyterLabを8888番ポートで起動しています。
Dockerfileからビルドしてコンテナを起動します。
docker compose up
Dockerの起動後にブラウザの検索窓に”localhost:8888″を入力すると、Jupyter Labをブラウザで表示できます。
localhost:8888Reflection Llama-3.1 70Bの実装

Dockerコンテナで起動したJupyter Lab上でReflection Llama-3.1 70Bの実装をします。
LangChainに関する環境変数を設定します。
import os
from uuid import uuid4
unique_id = uuid4().hex[0:8]
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_PROJECT"] = f"reflection - {unique_id}"
os.environ["LANGCHAIN_ENDPOINT"] = "https://api.smith.langchain.com"
os.environ["LANGCHAIN_API_KEY"] = "***************"unique_id = uuid4().hex[0:8]
8桁のランダムな一意の識別子unique_idを生成しています。
os.environ[“LANGCHAIN_TRACING_V2”] = “true”
この設定により、LangChainのトレースが可能になります。
os.environ[“LANGCHAIN_PROJECT”] = f”reflection – {unique_id}”
LangChainプロジェクトの名前を設定しています。ここでは、生成したunique_idを使用してプロジェクト名を「reflection – {unique_id}」の形式で一意にしています。
os.environ[“LANGCHAIN_ENDPOINT”] = “https://api.smith.langchain.com”
LangChainのAPIエンドポイントを指定しています。
os.environ[“LANGCHAIN_API_KEY”] = “***************”
LangChain APIを利用するためのAPIキーを設定しています。
「Reflection Llama-3.1 70B」のGGUFフォーマットをダウンロードします。
!ollama pull reflectionダウンロードしたモデルを確認します。
import ollama
ollama.list(){'models': [{'name': 'reflection:latest',
'model': 'reflection:latest',
'modified_at': '2024-09-14T05:54:50.934099176Z',
'size': 39969818946,
'digest': '5084e77c1e102030795dfbb58fd19adb792e5c0ec5ebf684c5481e3b2d66b740',
'details': {'parent_model': '',
'format': 'gguf',
'family': 'llama',
'families': ['llama'],
'parameter_size': '70.6B',
'quantization_level': 'Q4_0'}}]}‘model’: ‘reflection:latest’,
モデル名とバージョンを表しています。
‘format’: ‘gguf’,
モデルが保存されているファイル形式「GGUF」を示しています。
‘parameter_size’: ‘70.6B’,
モデルのパラメータ数(70.6億)を表しています。
‘quantization_level’: ‘Q4_0’
モデルに適用された量子化のレベル(Q4_0)を示しています。
Ollamaの詳しい使い方は、別の記事で解説しています。

モデルに入力するためのプロンプトテンプレートを定義しています。
from langchain.prompts import PromptTemplate
prompt = PromptTemplate(
template="""You are a world-class AI system, capable of complex reasoning and reflection. Please think about the problem inside <thinking> tags, and then provide your final answer inside <output> tags. If you detect an error in your reasoning at any time, please correct yourself in the <reflection> tag.
Input:
{input}
""",
input_variables=["input"],
)PromptTemplate()
<thinking>タグ内に推論の内容を出力します。
<output>タグ内に最終的な答えを出力します。
<reflection>タグ内で、エラーが検出された場合に自己修正を行います。
{input}はプロンプトに挿入される変数を表しています。
input_variablesには、テンプレート内で使用される変数{input}が指定されています。
LangChainのOllamaにモデルを設定し、プロンプトからLLMで生成するチェーンを構築しています。
from langchain_ollama import ChatOllama
from langchain_core.output_parsers import StrOutputParser
llm = ChatOllama(
model="reflection",
temperature=0,
)
reflection_model = prompt | llm | StrOutputParser()llm = ChatOllama(model=”reflection”, temperature=0)
model="reflection"は、「Reflection Llama-3.1 70B」のモデルを指定しています。temperature=0は、生成されたテキストのランダム性を制御するパラメータで、0に設定することで安定的な出力を得ることができます。
reflection_model = prompt | llm | StrOutputParser()
プロンプトpromptから始まり、モデルllmを通して生成されたテキストが、最後にStrOutputParserによって出力される流れを示しています。
Reflection Llama-3.1 70Bで推論してみる

Reflection Llama-3.1 70Bで推論してみる(1)
「2つのサイコロを振ったときに、合計が7になる確率を求める」推論を実行してみます。
reflection_model.invoke({'input': "Calculate the probability of rolling a total of 7 when rolling two dice."})原文:Calculate the probability of rolling a total of 7 when rolling two dice.
翻訳:2つのサイコロを振ったときに、合計が7になる確率を求めなさい。
原文:
“<thinking>\nTo solve this problem, we need to calculate the probability of rolling a total of 7 with two dice. Let’s break it down into steps:\n\n1. Understand the possible outcomes for each die:\n – Each die has 6 faces (1, 2, 3, 4, 5, 6)\n – There are 36 possible combinations when rolling two dice\n\n2. Identify all combinations that sum to 7:\n – (1, 6), (2, 5), (3, 4), (4, 3), (5, 2), (6, 1)\n\n3. Count the favorable outcomes:\n – There are 6 favorable outcomes\n\n4. Calculate the probability:\n – Probability = Number of favorable outcomes / Total number of possible outcomes\n – Probability = 6 / 36 = 1/6\n\n<reflection>\nLet’s verify our calculation:\n- We correctly identified all combinations that sum to 7.\n- The total number of possible outcomes (36) is correct, as it’s the product of the number of faces on each die (6 * 6).\n- Our probability calculation seems accurate: 6 favorable outcomes out of 36 possible ones.\n\nThe reasoning and calculations appear to be correct. We can proceed with confidence.\n</reflection>\n</thinking>\n\n<output>\nThe probability of rolling a total of 7 when rolling two dice is 1/6 or approximately 0.1667 (rounded to four decimal places).\n\nTo arrive at this answer, we considered the following:\n\n1. Each die has six faces (1 through 6), resulting in 36 possible combinations when rolling two dice.\n\n2. We identified all combinations that sum up to 7:\n – (1, 6)\n – (2, 5)\n – (3, 4)\n – (4, 3)\n – (5, 2)\n – (6, 1)\n\n3. There are six favorable outcomes out of the total 36 possible combinations.\n\n4. The probability is calculated as:\n Probability = Number of favorable outcomes / Total number of possible outcomes\n = 6 / 36\n = 1/6\n\nThis result means that if you were to roll two dice many times, you would expect to get a sum of 7 about one-sixth of the time. It’s worth noting that rolling a total of 7 is actually the most common outcome when rolling two six-sided dice, as it has more possible combinations than any other number.\n</output>”
翻訳:
<thinking>
この問題を解くためには、2つのサイコロを振ったときに合計が7になる確率を計算する必要があります。これをステップに分けて考えましょう。
各サイコロの可能な結果を理解します:
各サイコロには6つの面があります(1、2、3、4、5、6)。
2つのサイコロを振ると、36通りの組み合わせが可能です。
合計が7になるすべての組み合わせを特定します:
(1, 6)、(2, 5)、(3, 4)、(4, 3)、(5, 2)、(6, 1)
有利な結果を数えます:
6通りの有利な結果があります。
確率を計算します:
確率 = 有利な結果の数 / 全体の可能な結果の数
確率 = 6 / 36 = 1/6
<reflection>
計算を確認してみましょう:
合計が7になるすべての組み合わせを正確に特定しました。
全体の可能な結果の数(36)は正しいです。これは、各サイコロの面の数(6 * 6)の積です。
確率計算も正確です:36通りの中で6通りの有利な結果があります。
理由と計算は正しいようです。自信を持って次に進めることができます。
</reflection>
</thinking>
<output>
2つのサイコロを振ったときに合計が7になる確率は1/6、つまり約0.1667(小数点以下4桁に丸めた値)です。
この答えに至るために、以下の点を考慮しました:
各サイコロには1から6までの6つの面があり、2つのサイコロを振ると36通りの組み合わせが可能です。
合計が7になるすべての組み合わせを特定しました:
(1, 6)
(2, 5)
(3, 4)
(4, 3)
(5, 2)
(6, 1)
36通りの全組み合わせのうち、6通りが有利な結果です。
確率は次のように計算されます: 確率 = 有利な結果の数 / 全体の可能な結果の数 = 6 / 36 = 1/6
この結果は、もしサイコロを何度も振るとしたら、約6回に1回は合計が7になることを意味します。2つの6面サイコロを振る際、合計が7になるのは実際に最も一般的な結果であり、他のどの数字よりも多くの組み合わせがあることに注意してください。
</output>
<thinking>タグ内に推論の内容を出力します。
<output>タグ内に最終的な答えを出力します。
<reflection>タグ内で、エラーが検出された場合に自己修正を行います。
Reflection Llama-3.1 70Bで推論してみる(2)
「コインを3回投げたとき、すべて表が出る確率を計算してください。」推論を実行してみます。
reflection_model.invoke({'input': "Calculate the probability of getting heads on all three flips when flipping a coin three times."})原文:Calculate the probability of getting heads on all three flips when flipping a coin three times.
翻訳:コインを3回投げたとき、すべて表が出る確率を計算してください。
原文:
“<thinking>\nTo solve this problem, we need to calculate the probability of getting heads on all three flips when flipping a coin three times. Let’s break it down step by step:\n\n1. Understand the basic probability of a single coin flip:\n – A fair coin has two sides: heads and tails.\n – The probability of getting heads on a single flip is 1/2 or 0.5.\n\n2. Determine the number of flips:\n – We are flipping the coin three times.\n\n3. Calculate the probability for each flip:\n – For each individual flip, the probability of getting heads remains 1/2 or 0.5.\n\n4. Apply the multiplication rule for independent events:\n – When we have multiple independent events (like separate coin flips), we multiply their probabilities to get the combined probability.\n – So, we need to calculate: (1/2) * (1/2) * (1/2)\n\n5. Simplify and express the result as a fraction or decimal.\n\nLet’s work through this calculation:\n\n(1/2) * (1/2) * (1/2) = 1/8\n\nThis can also be expressed as 0.125 in decimal form.\n\n<reflection>\nLet’s verify our reasoning:\n- We correctly identified that each flip is an independent event.\n- We used the multiplication rule for independent events, which is correct.\n- Our calculation of 1/8 or 0.125 seems logical and mathematically sound.\n- This result makes sense intuitively: getting heads on all three flips should be less likely than any other specific outcome.\n\nThe reasoning appears to be correct, so we can proceed with confidence in our answer.\n</reflection>\n</thinking>\n\n<output>\nThe probability of getting heads on all three flips when flipping a coin three times is 1/8 or 0.125 (12.5%).\n\nTo arrive at this result, we need to consider the following:\n\n1. Each individual coin flip has a 50% chance of landing on heads.\n2. When we have multiple independent events (like separate coin flips), we multiply their probabilities to get the combined probability.\n3. In this case, we’re flipping the coin three times, so we calculate: (1/2) * (1/2) * (1/2) = 1/8\n\nThis result makes sense intuitively because getting heads on all three flips is less likely than any other specific outcome. For example, you could get two heads and one tail in multiple ways (HTT, THT, or TTH), but there’s only one way to get three heads in a row.\n\nIt’s worth noting that this probability applies specifically to the sequence HHH (heads on all three flips). If we were interested in getting exactly three heads regardless of order, the calculation would be different and involve combinations. However, for the specific question asked, 1/8 or 0.125 is the correct answer.\n</output>”
翻訳:
<thinking> この問題を解決するためには、コインを3回投げたときに全て表が出る確率を計算する必要があります。これをステップごとに分解してみましょう:
単一のコイントスの基本的な確率を理解する:
公平なコインには、表と裏の2つの面があります。
1回のコイントスで表が出る確率は1/2、つまり0.5です。
コイントスの回数を確認する:
コインを3回投げます。
各コイントスの確率を計算する:
各コイントスごとに、表が出る確率は1/2、つまり0.5のままです。
独立した事象の積の法則を適用する:
独立した複数の事象(例えば、別々のコイントス)がある場合、それらの確率を掛け合わせて全体の確率を求めます。
したがって、次の計算を行います:(1/2) * (1/2) * (1/2)
結果を簡略化し、分数または小数で表現する。
この計算を進めましょう:
(1/2) * (1/2) * (1/2) = 1/8
これは小数形式では0.125と表現できます。
<reflection> 私たちの推論を確認しましょう:
各コイントスが独立した事象であることを正しく認識しました。
独立した事象の積の法則を使用しましたが、これは正しい方法です。
1/8または0.125という計算結果は論理的で、数学的にも正しいようです。
この結果は直感的にも意味があります。コインを3回投げて全て表が出る確率は、他の特定の結果よりも低いはずです。
推論は正しいようなので、自信を持ってこの答えで進めることができます。
</reflection> </thinking>
<output> コインを3回投げて全て表が出る確率は1/8、つまり0.125(12.5%)です。
この結果に到達するために、以下の点を考慮しました:
各コイントスには50%の確率で表が出ます。
独立した複数の事象(例えば、別々のコイントス)がある場合、それらの確率を掛け合わせて全体の確率を求めます。
この場合、コインを3回投げるので、次の計算を行います:(1/2) * (1/2) * (1/2) = 1/8
この結果は直感的にも意味があります。コインを3回投げて全て表が出る確率は、他の特定の結果よりも低いはずです。例えば、2回表で1回裏が出る可能性(HTT、THT、TTHなど)は複数ありますが、3回連続で表が出る可能性は1通りしかありません。
なお、この確率は特定の順序(HHH、つまり3回連続で表が出る)に適用されます。もし順序に関係なく3回表が出る確率を求めたい場合は、計算方法が異なり、組み合わせを考慮する必要があります。しかし、今回の特定の質問に対しては、1/8または0.125が正しい答えです。 </output>
生成AI・LLMのコストでお困りなら
GPUのスペック不足で生成AIの開発が思うように進まないことはありませんか?
そんなときには、高性能なGPUをリーズナブルな価格で使えるGPUクラウドサービスがおすすめです!

GPUSOROBANは、高性能GPU「NVIDIA H200」を業界最安級の料金で使用することができます。
NVIDIA H200は、生成AI・LLMの計算にかかる時間を大幅に短縮することが可能です。
クラウドで使えるため、大規模な設備投資の必要がなく、煩雑なサーバー管理からも解放されます。







