
Llama 3.2は、Metaが提供するオープンソースのLLMで、画像認識やテキスト生成を行うことができます。
Llama 3.2には、軽量テキストモデルと画像を処理するビジョンモデルが用意されています。
この記事では、Llama 3.2の性能から商用利用、使い方まで紹介します。

Llama 3.2とは

Llama 3.2は、Metaが提供するオープンソースのLLMで、画像認識やテキスト生成を行えるマルチモーダル機能を備えています。
Llama 3.2の1Bと3Bは軽量テキストモデルで、11Bと90Bは画像処理をサポートするビジョンモデルです。
このモデルは、Metaのライセンスに基づいて無料で利用でき、商用利用も許可されています。
- Llama 3.2は、Metaが提供するオープンソースのLLMです。
- 軽量テキストモデルと画像を処理するビジョンモデルがあります。
- Metaのライセンスに基づき、無料で利用できます。

Llama 3.2のモデル

Llama 3.2の性能は、主に軽量テキストモデルとビジョンモデルに分かれています。
軽量テキストモデル(1B・3B): エッジデバイスやモバイルデバイスでの動作を想定した軽量モデルです。128Kトークンのコンテキスト長をサポートし、多言語テキスト生成、ツール呼び出し、高速な処理が可能です。
ビジョンモデル(11B・90B): 画像認識機能を持つ大規模なモデルで、チャートやグラフを含む文書の理解、画像のキャプション生成、画像内のオブジェクトの指示など、視覚的なタスクをサポートします。
| モデルID | パラメータ | モデルの種類 | タイプ |
|---|---|---|---|
| meta-llama/Llama-3.2-1B | 10億 | 軽量テキストモデル | 事前学習モデル |
| meta-llama/Llama-3.2-1B-Instruct | 10億 | 軽量テキストモデル | 指示学習モデル |
| meta-llama/Llama-3.2-3B | 30億 | 軽量テキストモデル | 事前学習モデル |
| meta-llama/Llama-3.2-3B-Instruct | 30億 | 軽量テキストモデル | 指示学習モデル |
| meta-llama/Llama-3.2-11B-Vision | 110億 | ビジョンモデル | 事前学習モデル |
| meta-llama/Llama-3.2-11B-Vision-Instruct | 110億 | ビジョンモデル | 指示学習モデル |
| meta-llama/Llama-3.2-90B-Vision | 900億 | ビジョンモデル | 事前学習モデル |
| meta-llama/Llama-3.2-90B-Vision-Instruct | 900億 | ビジョンモデル | 指示学習モデル |
Llama 3.2に必要なGPUメモリ(VRAM)

Llama 3.2の推論におけるGPUメモリ(VRAM)要件は、モデルのサイズや使用する数値表現、量子化によって異なります。
推論の場合
| モデルの種類 | モデルサイズ | BF16 |
|---|---|---|
| 軽量テキストモデル | 1B | 2.5GB |
| 軽量テキストモデル | 3B | 6.5GB |
| ビジョンモデル | 11B | 13GB(4bit量子化) |
| ビジョンモデル | 90B | 57GB(4bit量子化) |
Llama 3.2の性能
Llama3.2の性能について、「主要ベンチマーク」と「人間による評価」の指標を見ていきます。

軽量テキストモデルのベンチマーク
Llama 3.2の3Bモデルは、指示のフォロー、要約、プロンプトの書き換え、ツールの使用などのタスクで、Gemma 2 2.6BモデルやPhi 3.5-miniモデルを上回る性能を示しています。
Llama 3.2の1BモデルもGemmaと同等の性能を持ち、軽量ながら高いパフォーマンスを発揮します。
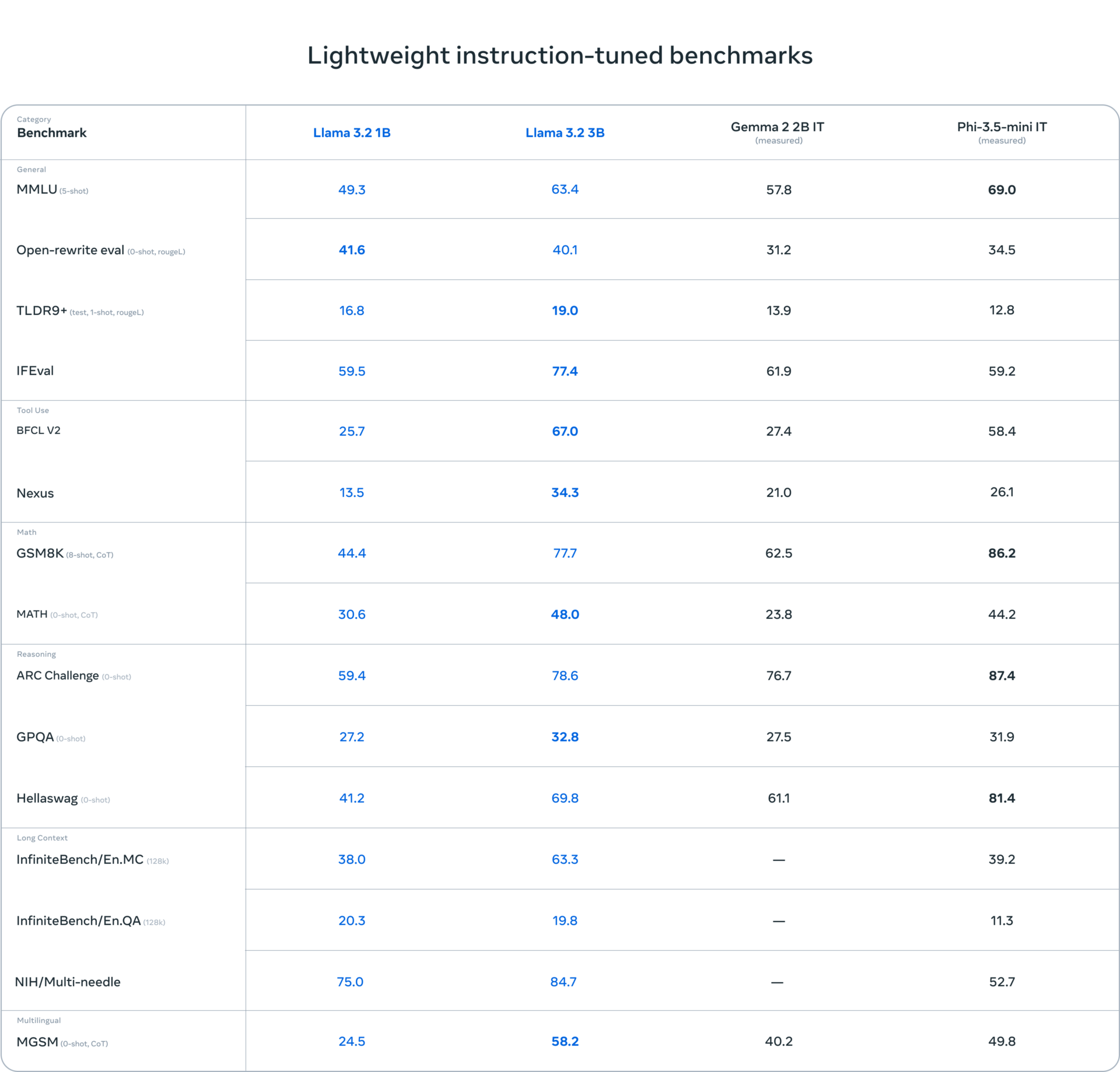
General(一般的なタスク):
- MMLU(5-shot): 多言語理解に関するタスク。Llama 3.2の3Bモデルは、63.4でGemma(57.8)を上回っていますが、Phi-3.5-mini IT(69.0)が最も高いスコアを記録しています。
- Open-rewrite eval(0-shot, rogueL): 自然言語の書き換えタスク。Llama 3.2の1Bと3Bが他モデルを上回るスコアを記録しています。
- TLDR9(task1, task4, rogueL): 要約タスク。Llama 3.2のモデルが他モデルを上回るパフォーマンスを示しています。
- IFEval: 文法チェックや構文評価。Llama 3.2 3Bモデルが最も高い77.4のスコアを記録しています。
Tool Use(ツール使用):
- BFCL V2: ツール呼び出し機能に関連するタスク。Llama 3.2の3Bモデルが67.0のスコアを記録し、他のモデルを大幅に上回っています。
- Nexus: データの検索や統合タスク。Llama 3.2の3Bモデルが34.3で最も高いスコアを記録しています。
Math(数学タスク):
- GSM8K(8-shot, CoT): 算数タスク。Phi-3.5-mini ITが86.2で最高のスコアを記録しており、Llama 3.2 3Bモデルは77.7です。
- MATH(0-shot, CoT): より複雑な数学タスクで、Llama 3.2 3Bモデルが48.0のスコアを記録し、他モデルを上回っています。
Reasoning(推論タスク):
- ARC Challenge(0-shot): 複雑な推論タスク。Phi-3.5-mini ITが87.4で最高のスコアを記録し、Llama 3.2の3Bは78.6です。
- GPQA(0-shot): 質問応答タスクで、Llama 3.2 3Bモデルが32.8と他のモデルよりも優れています。
- Hellaswag(0-shot): 推論の一貫性を問うタスクで、Phi-3.5-mini ITが81.4で最高スコアですが、Llama 3.2 3Bモデルも69.8と高いスコアを示しています。
Long Context(長文脈処理):
- InfiniteBench/En.MC(128K): 長い文脈を持つタスクで、Llama 3.2 3Bモデルが63.3と非常に高いスコアを示しています。
- InfiniteBench/En.QA(128K): 質問応答タスクで、Llama 3.2のモデルが優れた性能を示しています。
Multilingual(多言語タスク):
- MGSM(0-shot, CoT): 多言語の算数タスク。Llama 3.2の3Bモデルが58.2で他モデルより優れています。
ビジョンモデルのベンチマーク
Llama 3.2の90Bモデルは、視覚関連のタスクで非常に優れた性能を示しています。AI2 DiagramやChartQAといったベンチマークで、ClaudeやGPT-4o-miniを上回る高いスコアを記録しています。
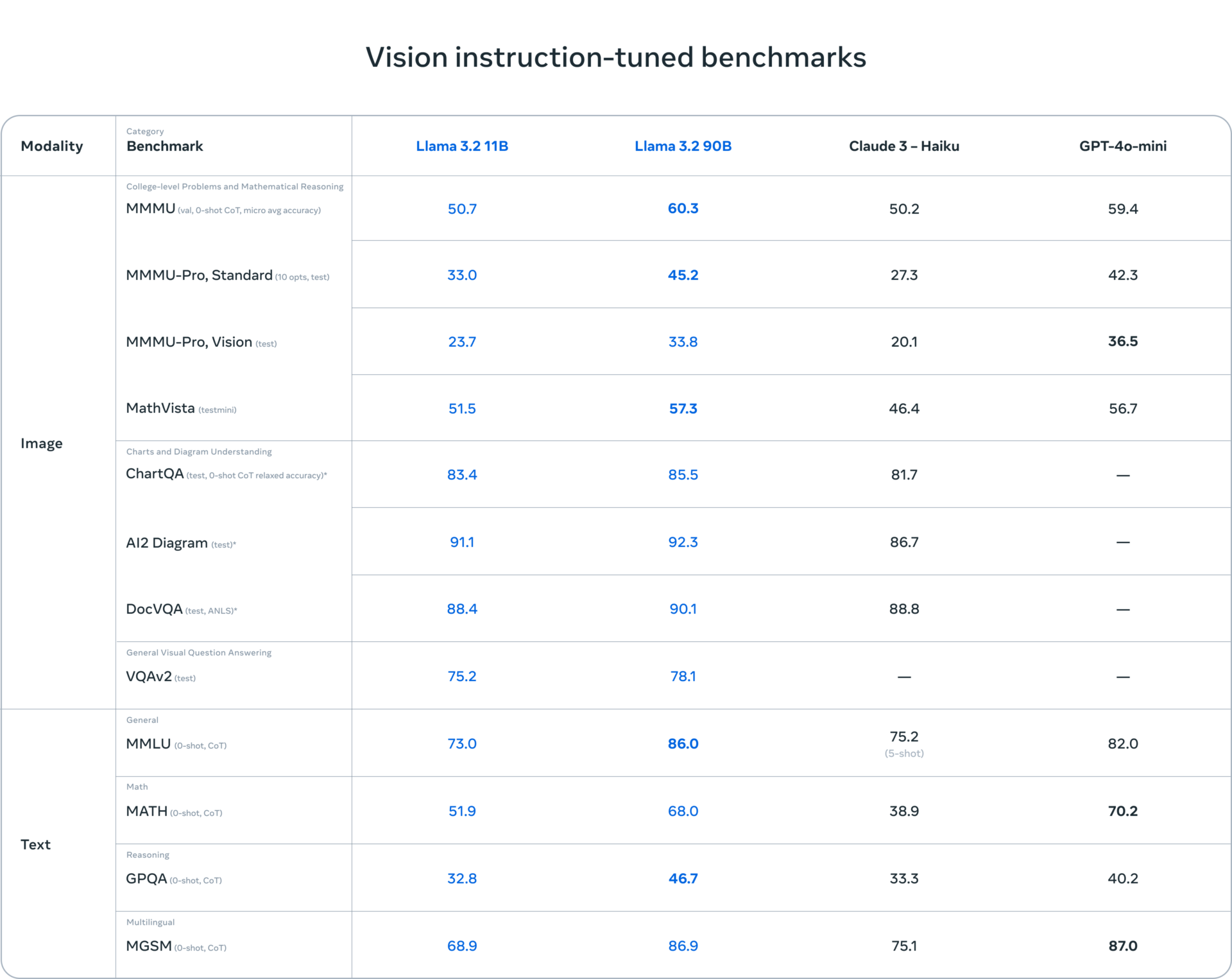
1. College-level Problems and Mathematical Reasoning(大学レベルの問題と数学的推論の画像タスク)
- MMMU (Val, 0-shot CoT): Llama 3.2 90Bは60.3、GPT-4o-miniは59.4で、Llama 3.2 90Bが最も高いスコアを示しています。
- MMMU-Pro, Standard: Llama 3.2 90Bは45.2で、GPT-4o-miniが42.3。Llama 3.2 90Bが優れています。
- MMMU-Pro, Vision: Llama 3.2 90Bは33.8で、GPT-4o-miniは36.5でやや上回っています。
- MathVista: Llama 3.2 90Bが57.3で最も高いスコアを記録しています。
2. Charts and Diagram Understandings(チャートや図表の理解)
- ChartQA: チャートやグラフを含む質問応答タスクで、Llama 3.2 90Bが85.5、Llama 3.2 11Bが83.4、Claude 3 – Haikuは81.7です。Llama 3.2 90Bが最も高いスコアです。
- AI2 Diagram: 図の理解に関するタスクで、Llama 3.2 90Bが92.3、Claude 3 – Haikuは86.7。Llama 3.2 90Bが最も高いスコアを示しています。
- DocVQA: 文書内のビジュアルに関する質問応答タスクで、Llama 3.2 90Bが90.1と最高スコアです。
3. General Visual Question Answering(一般的な視覚質問応答)
- VQAv2: Llama 3.2 90Bは78.1で、他モデルと比較しても優れたスコアを示しています。
4. Text(テキスト関連タスク)
- MMLU (0-shot CoT): 一般的な多言語理解タスクで、Llama 3.2 90Bが86.0、GPT-4o-miniは82.0です。Llama 3.2 90Bが高いスコアを記録しています。
- MATH (0-shot CoT): 数学タスクで、Llama 3.2 90Bは68.0で、GPT-4o-miniの70.2に近いスコアです。
- GPQA (0-shot CoT): 質問応答タスクで、Llama 3.2 90Bが46.7、GPT-4o-miniは40.2。Llama 3.2がリードしています。
- MGSM (0-shot CoT): 多言語の数学タスクで、GPT-4o-miniが87.0で最も高く、Llama 3.2 90Bは86.9と僅差です。
Llama 3.2の日本語能力は?

Llama 3.2は、英語、ドイツ語、フランス語、イタリア語、ポルトガル語、ヒンディー語、スペイン語、タイ語をサポートしていますが、日本語をサポートしていません。
この記事では、Llama3.2を使って日本語生成のテストも行っています。
Llama 3.2の商用利用・ライセンス

Llama 3.2は「META LLAMA 3.2 COMMUNITY LICENSE」にもとづいて、無料で利用でき、商用利用も可能です。
商用利用:ソフトウェアやコードを商用利用することが許可されています。
改変:ソフトウェアやコードを自由に修正したり改変したりすることができます。
配布:修正したり変更したりしたソフトウェアを自由に配布することができます。
著作権表示:再配布時に、著作権の表示や契約書コピーの提供などが必要になります。
特許利用:特許利用に関する明示的な規定はありません。
詳細は「META LLAMA 3.2 COMMUNITY LICENSE」のページをご確認ください。
Llama 3.2のモデル申請

Llama 3.2のモデルの利用申請をします。
HuggingFaceにログインして、Llama 3.2のモデルページにアクセスします。

Llama 3.2のモデルページで、「Expand to review and access」ボタンを押して展開します。
ページの下のほうに進むと入力フォームがありますので、
「ユーザー情報」を入力し、「ライセンス条項の同意文」にチェックを入れて、「Submit」ボタンをクリックします。
「Access granted」というタイトルで承認通知メールが届いたら、モデルの利用承認が完了です。
利用承認が得られたら、HuggingFaceのLlama 3.2のモデルページに「Granted model」と表示がされます。
Llama 3.2の環境構築

Llama 3.2の環境構築について解説していきます。
実行環境
この記事で用意した実行環境は以下のとおりです。
- GPU:NVIDIA A100 80GB
- GPUメモリ(VRAM):80GB
- OS :Ubuntu 22.04
- Docker
Dockerで環境構築
Dockerを使用してLlama 3.2の環境構築をします
Dockerの使い方は以下の記事をご覧ください。

コンテナにインストールするパッケージは以下のとおりです。
CUDA、PyTorch、Transformersはバージョン依存関係によるエラーが起きやすいので、動作検証済のバージョン指定してインストールしています。
- CUDA:12.1
- Python:3.10
- PyTorch:2.2.2
- transformers:4.45.0
- accelerate
- bitsandbytes
Ubuntuのコマンドラインで、Dockerfileを作成します。
mkdir llama32
cd llama32
nano DockerfileDockerfileに以下の記述を貼り付けます。
# ベースイメージ(CUDA)の指定
FROM nvidia/cuda:12.1.0-cudnn8-devel-ubuntu22.04
# 必要なパッケージをインストール
RUN apt-get update && apt-get install -y python3-pip python3-venv git nano
# 作業ディレクトリを設定
WORKDIR /app
# アプリケーションコードをコピー
COPY . /app
# Python仮想環境の作成
RUN python3 -m venv /app/.venv
# 仮想環境をアクティベートするコマンドを.bashrcに追加
RUN echo "source /app/.venv/bin/activate" >> /root/.bashrc
# JupyterLabのインストール
RUN /app/.venv/bin/pip install Jupyter jupyterlab
# PyTorchのインストール
RUN /app/.venv/bin/pip install torch==2.2.2 torchvision==0.17.2 torchaudio==2.2.2 --index-url https://download.pytorch.org/whl/cu121
# Transformer関連のインストール
RUN /app/.venv/bin/pip install transformers==4.45.0 accelerate bitsandbytes
# コンテナの起動時にbashを実行
CMD ["/bin/bash"]docker-compose.ymlでDockerコンテナの設定をします。
docker-compose.ymlのYAMLファイルを作成して開きます。
nano docker-compose.yml以下のコードをコピーして、YAMLファイルに貼り付けます。
services:
llama32:
build:
context: .
dockerfile: Dockerfile
image: llama32
runtime: nvidia
container_name: llama32
ports:
- "8888:8888"
volumes:
- .:/app/llama32
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: 1
capabilities: [gpu]
command: >
bash -c '/app/.venv/bin/jupyter lab --ip="*" --port=8888 --NotebookApp.token="" --NotebookApp.password="" --no-browser --allow-root'Dockerfileからビルドしてコンテナを起動します。
docker compose up
Dockerの起動後にブラウザの検索窓に”localhost:8888″を入力すると、Jupyter Labをブラウザで表示できます。
localhost:8888Llama 3.2のビジョンモデルを実装

Dockerコンテナで起動したJupyter Lab上でLlama 3.2の実装をします。
HuggingFaceからモデルをダウンロードするために、HuggingFaceにログインします。
from huggingface_hub import login
token = "**************************"
login(token)token = “******************************”
Hugging Faceのアクセストークンを指定します。**********に実際のトークン値が入ります。
Hugging Faceのアクセストークンの発行方法は、別の記事で解説しています。

Llama 3.2のモデルをダウンロードして読み込みます。
import requests
import torch
from PIL import Image
from transformers import MllamaForConditionalGeneration, AutoProcessor
model_id = "meta-llama/Llama-3.2-11B-Vision-Instruct"
model = MllamaForConditionalGeneration.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
device_map="auto",
)
processor = AutoProcessor.from_pretrained(model_id)model_id = “meta-llama/Llama-3.2-11B-Vision-Instruct”
Llama3.2のモデルタイプを指定します。
model = MllamaForConditionalGeneration.from_pretrained(…
from_pretrained: 指定したモデルをロードします。torch_dtype=torch.bfloat16: モデルのパラメータのデータ型をbfloat16に設定します。device_map="auto": 利用可能なデバイス(CPUやGPU)に自動的にモデルを割り当てます。
processor = AutoProcessor.from_pretrained(model_id)
モデルに入力するデータ(テキストや画像)を適切な形式に変換するプロセッサを定義します。
モデルを量子化して読み込みます。
量子化によりモデルの精度が低下しますが、GPUメモリを節約することができます。
import torch
from PIL import Image
from transformers import MllamaForConditionalGeneration, AutoProcessor
from transformers import BitsAndBytesConfig
model_id = "meta-llama/Llama-3.2-11B-Vision-Instruct"
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16
)
model = MllamaForConditionalGeneration.from_pretrained(
model_id,
quantization_config=bnb_config
)
processor = AutoProcessor.from_pretrained(model_id)bnb_config = BitsAndBytesConfig(…
load_in_4bit=True:モデルのパラメータを4ビット量子化してロードすることを指定します。
bnb_4bit_quant_type="nf4":4ビット量子化の手法としてnf4を使用することを指定します。
bnb_4bit_compute_dtype=torch.bfloat16:計算時のデータ型をbfloat16に指定します。
画像とプロンプトを入力として、モデルからテキストを生成する関数を定義します。
def textvision(path_image, prompt):
image = Image.open(path_image)
messages = [
{"role": "user", "content": [
{"type": "image"},
{"type": "text", "text": prompt}
]}
]
input_text = processor.apply_chat_template(messages, add_generation_prompt=True)
inputs = processor(
image,
input_text,
add_special_tokens=False,
return_tensors="pt"
).to(model.device)
output = model.generate(**inputs, max_new_tokens=128)
resized_image = image.resize((int(image.width * 0.5), int(image.height * 0.5)))
resized_image.show()
print(processor.decode(output[0]))image = Image.open(path_image)
指定したパスから画像を読み込みます。
messages = [ {“role”: “user”, “content”: [ {“type”: “image”}, {“type”: “text”, “text”: prompt} ]} ]
{"role": "user"}:このメッセージがユーザーからのものであることを示します。{"type": "image"}:メッセージに画像が含まれていることを示します。{"type": "text", "text": prompt}:テキストのプロンプトを含みます。
input_text = processor.apply_chat_template(messages, add_generation_prompt=True)
apply_chat_template:メッセージをチャット形式のテンプレートに当てはめます。add_generation_prompt=True: モデルにテキスト生成の開始位置を示しています。
inputs = processor( image, input_text, add_special_tokens=False, return_tensors=”pt” ).to(model.device)
processor:トークナイザーや画像のエンコーダーが含まれます。
add_special_tokens=False:文の開始や終了を示す特殊なトークンを追加しない設定。return_tensors="pt":PyTorchのテンソル形式でデータを返します。
to(model.device):テンソルを、モデルが動作しているCPUまたはGPUに移動します。
output = model.generate(**inputs, max_new_tokens=128)
model.generate:モデルが入力に基づいてテキストを生成します。
max_new_tokens=128:生成される最大トークン数を128に設定します。
print(processor.decode(output[0]))
モデルが生成した出力を人間が読めるテキストに変換し、表示します。
Llama 3.2ビジョンモデルで画像からテキストを生成する

Llama 3.2のビジョンモデルを使って、英語・日本語での質問応答を試してみます。
英語での質問応答
「ラマとアルパカの違いについて教えて下さい。」というプロンプトを実行してみます。
path_image = "cat25.jpg"
prompt = "Describe this image"
textvision(path_image, prompt)
Describe this image
<|begin_of_text|><|start_header_id|>user<|end_header_id|>
<|image|>Describe this image<|eot_id|><|start_header_id|>assistant<|end_header_id|>
The image depicts a cat wearing a hard hat and safety vest, holding a clipboard in a factory setting. The cat is dressed in a black suit jacket, white shirt, and gray tie, with a yellow and orange safety vest over it. It wears a yellow hard hat on its head and holds a blue clipboard in its paws.
In the background, several people are working in the factory, some of whom are also wearing hard hats and safety vests. The factory is filled with various machinery and equipment, including conveyor belts, pipes, and large metal objects. The atmosphere suggests that the cat is inspecting or overseeing the factory operations.
Overall
<翻訳>
その画像は、工場内でクリップボードを持ち、ヘルメットと安全ベストを着た猫を描いています。猫は黒いスーツジャケット、白いシャツ、グレーのネクタイを着用しており、その上に黄色とオレンジの安全ベストを着ています。また、頭には黄色のヘルメットをかぶり、前足で青いクリップボードを持っています。
背景には数人の人々が工場で作業しており、その中には同じくヘルメットと安全ベストを着用している者もいます。工場内にはコンベアベルトやパイプ、大きな金属製の機械などがあり、猫が工場の業務を点検または監督している様子がうかがえます。
日本語での質問応答
「ラマとアルパカの違いについて教えて下さい。」というプロンプトを実行してみます。
path_image = "cat36.jpg"
prompt = "この画像について教えて下さい。"
textvision(path_image, prompt)
この画像について教えて下さい。
<|begin_of_text|><|start_header_id|>user<|end_header_id|>
<|image|>この画像について教えて下さい。<|eot_id|><|start_header_id|>assistant<|end_header_id|>
この画像は、猫の頭部と人間の体を合わせたようなキャラクターが、ワインを楽しむ場面を描いたイラストです。
キャラクターは、黒いスーツと白いシャツ、黒のネクタイ、白いハンカチを着用し、ワイングラスを手にしています。キャラクターの背後には、木製の壁に並べられたワイン樽とボトルが見えます。
この画像は、ワインを楽しむ猫のイメージを表現したものと考えられます。
Llama 3.2の軽量テキストモデルを実装

Dockerコンテナで起動したJupyter Lab上でLlama 3.2の軽量テキストモデルを実装します。
HuggingFaceからモデルをダウンロードするために、HuggingFaceにログインします。
from huggingface_hub import login
token = "**************************"
login(token)token = “******************************”
Hugging Faceのアクセストークンを指定します。**********に実際のトークン値が入ります。
Hugging Faceのアクセストークンの発行方法は、別の記事で解説しています。
Llama 3.2のモデルをダウンロードして読み込みます。
import torch
from transformers import pipeline
model_id = "meta-llama/Llama-3.2-1B-Instruct"
pipe = pipeline(
"text-generation",
model=model_id,
torch_dtype=torch.bfloat16,
device_map="auto",
)token = “******************************”
Hugging Faceのアクセストークンを定義。******に実際のトークン値が入ります。
model_id = “meta-llama/Llama-3.2-1B-Instruct”
Llama 3.2のモデルタイプを指定します。
transformers.pipeline()
テキスト生成タスクのためのTransformerのパイプラインを設定しています。
model_kwargs={"torch_dtype": torch.bfloat16}データ型をBF16に指定しています。
量子化を行う場合は引数に"quantization_config": {"load_in_4bit": True}を加えてください。
Llama 3.2の軽量テキストモデルで生成を試す

Llama 3.2の軽量テキストモデルを使って、英語と日本語で質問応答を試してみます。
英語での質問応答
「休暇についてアドバイスをください。」というプロンプトを実行してみます。
messages = [
{"role": "system", "content": "You are an assistant answering in English."},
{"role": "user", "content": "Please give me some advice about vacation."},
]
outputs = pipe(
messages,
max_new_tokens=256,
)
print(outputs[0]["generated_text"][-1])Please give me some advice about vacation.
<翻訳>
休暇についてアドバイスをください。
{‘role’: ‘assistant’, ‘content’: “I’d be happy to help you with some vacation advice.\n\nTo get started, can you tell me a bit more about the type of vacation you’re looking for? For example:\n\n- What destination are you thinking of?\n- How long do you have for the trip?\n- What activities or experiences are you interested in (e.g. beach relaxation, city exploration, outdoor adventures, cultural events)?\n- Are there any specific budget constraints or preferences you have?\n\nThe more information you can provide, the better I can tailor my advice to suit your needs.”}
<翻訳>
休暇についてのアドバイスを喜んでお手伝いします。
まず始めに、どのような休暇をお考えか教えていただけますか?例えば:
・どの目的地を考えていますか?
・旅行期間はどのくらいですか?
・どんなアクティビティや体験に興味がありますか(例:ビーチでのリラクゼーション、都市の探索、アウトドアアドベンチャー、文化的イベント)?
・予算に関する制約や特別な希望はありますか?
より多くの情報を提供いただければ、ニーズに合ったアドバイスができると思います。
日本語での質問応答
「観葉植物の選び方を教えて下さい。」というプロンプトを実行してみます。
messages = [
{"role": "system", "content": "あなたは日本語で回答するアシスタントです。"},
{"role": "user", "content": "観葉植物の選び方を教えて下さい。"},
]
outputs = pipe(
messages,
max_new_tokens=256,
)
print(outputs[0]["generated_text"][-1])観葉植物の選び方を教えて下さい。
{‘role’: ‘assistant’, ‘content’: ‘観葉植物は、自然に生える植物の種類や形状を選ぶ際に大切な選択肢です。以下は、観葉植物の種類と特性をご紹介します。\n\n特性\n\n* 低水分性: 観葉植物は、水分を少なくすることができるため、低水分性の植物が多くいます。\n* 低光度: 観葉植物は、光を過剰に受けることができないため、低光度の植物が多くいます。\n* 低温: 観葉植物は、低温の植物が多くいます。\n* 低酸素: 観葉植物は、酸素を多く取ることができないため、低酸素の植物が多くいます。\n\n観葉植物の種類\n\n* アスパラガス (Asparagus): 低水分性と低光度の植物で、夏に熟した植物を食べる。\n* シリエント (Succulent): 低水分性と低光度の植物で、水分を少なくすることができる。\n* ‘}
生成AI・LLMのコストでお困りなら
GPUのスペック不足で生成AIの開発が思うように進まないことはありませんか?
そんなときには、高性能なGPUをリーズナブルな価格で使えるGPUクラウドサービスがおすすめです!

GPUSOROBANは、高性能GPU「NVIDIA H200」を業界最安級の料金で使用することができます。
NVIDIA H200は、生成AI・LLMの計算にかかる時間を大幅に短縮することが可能です。
クラウドで使えるため、大規模な設備投資の必要がなく、煩雑なサーバー管理からも解放されます。







