
GraphRAGはナレッジグラフを活用して、RAGの検索精度を向上させるアプローチです。
従来のRAGの非構造化データに加えて、構造化データを統合することで検索精度が大幅に向上しています。
この記事では、オープンソースのLangChainとNeo4jを使ってGraphRAGを構築する方法を紹介しています。
ざっくり言うと
- GraphRAGの概要としくみを紹介
- オープンソースのLangChainとNeo4jを使ってGraphRAGを構築
- LLMとグラフデータベースはローカル環境に構築

GraphRAGとは?

GraphRAGはナレッジグラフを活用して、RAGの検索精度を向上させるアプローチです。
従来のRAGは、主に非構造化データを扱うため、データ間の複雑な関係性や構造を捉えきれず、それらに関する質問に対しては精度が落ちる課題がありました。
GraphRAGはナレッジグラフを利用して情報を構造化し、データ間の関係性や構造を把握することができます。

GraphRAGのしくみ

ハイブリット検索とグラフ検索
GraphRAGは、ハイブリット検索とグラフ検索の結果を組み合わせて、LLMから回答をするしくみです。
ハイブリット検索は、ベクトル検索とキーワード検索を行う非構造化データを扱う従来のRAGの手法になります。
これに加えて、GraphRAGでは構造化データを扱うグラフ検索を統合することで、データの関係性を把握できるようになります。
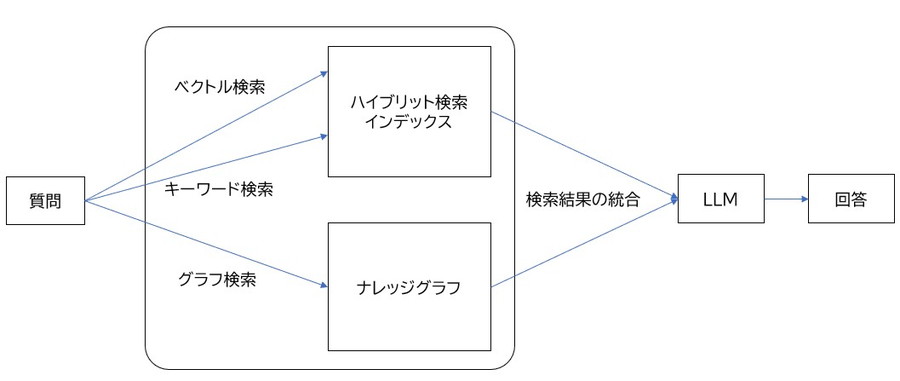
- ハイブリット検索:ベクトル検索とキーワード検索を組み合わせる手法。
- ベクトル検索:テキストの意味的な類似性に基づき、ベクトルデータを使って関連情報を検索する手法。
- キーワード検索:指定された単語やフレーズと完全一致または部分一致するデータを検索する手法。
- グラフ検索: エンティティ間の関係性やつながりをたどって情報を検索する手法。
ノードとエッジ
グラフ検索は、ノードとエッジによって構成されるデータモデルを用いて実現されます。
ノードは、人物、組織、場所などのエンティティ(実体)を表します。
エッジは、これらのエンティティ間のリレーションシップ(関係性)を表します。
エンティティ間のリレーションシップをたどることで、データの構造や関連性を探索することができます。
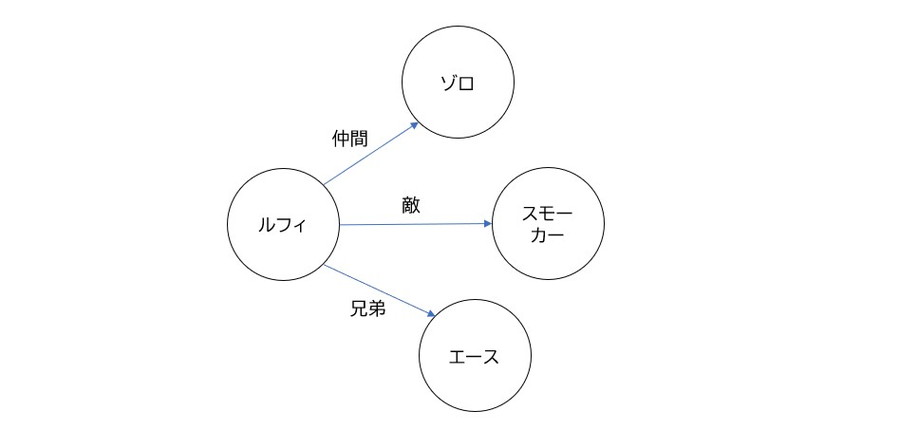
- ノード:人物、場所、組織などのエンティティ(実体)を表す要素。
- 例)人物: “ルフィ”
- 場所: “フーシャ村”
- 組織: “麦わらの一味”
- エッジ:エンティティ同士のリレーションシップ(関係性)を表す要素。
- 例)ルフィは麦わらの一味に”所属している”(BELONGS_TO)
- フーシャ村はイーストブルーに”位置している”(LOCATED_IN)
- ルフィはシャンクスを”知っている”(KNOWS)
GraphRAGの実行環境

この記事で用意した実行環境は以下のとおりです。
- GPU:NVIDIA A100 80GB
- GPUメモリ(VRAM):80GB
- OS :Ubuntu 22.04
- Docker
Dockerで環境構築
Dockerを使用してGraphRAGの環境構築をします
Dockerの使い方は以下の記事をご覧ください。

Ubuntuのコマンドラインで、Langchainの環境を構築するDockerfileを作成します。
mkdir langchain_neo4j
cd langchain_neo4j
nano langchain.DockerfileLangchain用のDockerfileに以下の記述を貼り付けます。
# ベースイメージ(CUDA)の指定
FROM nvidia/cuda:12.1.0-cudnn8-devel-ubuntu22.04
# 必要なパッケージをインストール
RUN apt-get update && apt-get install -y python3-pip python3-venv git nano curl
RUN curl -fsSL https://ollama.com/install.sh | sh
# 作業ディレクトリを設定
WORKDIR /app
# アプリケーションコードをコピー
COPY . /app
# Python仮想環境の作成
RUN python3 -m venv /app/.venv
# 仮想環境をアクティベートするコマンドを.bashrcに追加
RUN echo "source /app/.venv/bin/activate" >> /root/.bashrc
# JupyterLabのインストール
RUN /app/.venv/bin/pip install Jupyter jupyterlab
# LangChain関連のインストール
RUN /app/.venv/bin/pip install ollama langchain-ollama langchain langsmith langchain-graphrag langchain-community langchain_huggingface langchain_core langchain-experimental neo4j langchain_neo4j tiktoken
# コンテナの起動時にbashを実行
CMD ["/bin/bash"]FROM nvidia/cuda:12.1.0-cudnn8-devel-ubuntu22.04CUDA12.1のベースイメージを指定しています。
RUN apt-get update && apt-get install -y python3-pip python3-venv git nano curlPython関連のパッケージをインストールしています。
RUN curl -fsSL https://ollama.com/install.sh | shLinux版のOllamaをインストールしています。
PythonでOllamaを動かす際にもLinux版Ollamaのインストールが必要になりますのでご注意ください。
RUN /app/.venv/bin/pip install Jupyter jupyterlabJupyterLabをインストールしています。
RUN /app/.venv/bin/pip install ollama langchain-ollama langchain langsmith langchain-graphrag langchain-community langchain_huggingface langchain_core langchain-experimental neo4j langchain_neo4j tiktokenLangChainとOllama関連のパッケージをインストールしています。
LLMはOllamaのライブラリを使って動かしますので、PyTorchやTransformerは別途インストール不要です。
neo4jの環境を構築するDockerfileを作成します。
nano neo4j.Dockerfileneo4j用のDockerfileに以下の記述を貼り付けます。
# Neo4jベースイメージ
FROM neo4j:5.25.1
# 必要なツールをインストール
RUN apt-get update && apt-get install -y curl && apt-get clean
# 環境変数の設定
ENV NEO4JLABS_PLUGINS '[ "apoc" ]'
ENV NEO4J_dbms_security_procedures_unrestricted apoc.*
# APOCプラグインをダウンロードして配置
RUN curl -L -o /var/lib/neo4j/plugins/apoc-5.25.1-core.jar \
https://github.com/neo4j/apoc/releases/download/5.25.1/apoc-5.25.1-core.jar
# ポートの公開
EXPOSE 7474 7687
# デフォルトコマンド
CMD ["neo4j"]FROM neo4j:5.25.1Neo4jのベースイメージを指定しています。
ENV NEO4JLABS_PLUGINS '[ "apoc" ]'
ENV NEO4J_dbms_security_procedures_unrestricted apoc.*APOCプラグインをインストール対象として環境変数に設定します。
APOCは、Neo4jで利用できる追加機能ライブラリであり、Cypherクエリを拡張するためのプロシージャを提供します。
RUN curl -L -o /var/lib/neo4j/plugins/apoc-5.25.1-core.jar \
https://github.com/neo4j/apoc/releases/download/5.25.1/apoc-5.25.1-core.jarNeo4j用のAPOCプラグインをダウンロードし、Neo4jプラグインのディレクトリに配置しています。
EXPOSE 7474 7687ポートの公開設定を行っています。
7474(HTTPポート)は、Neo4jの Web管理インターフェースが動作するポートです。
7687(Boltポート)は、 Pythonのneo4jライブラリがデータベースと接続するために使用されます。
CMD ["neo4j"]Dockerコンテナ起動時に Neo4jデータベース を起動します。
docker-compose.ymlでDockerコンテナの設定をします。
docker-compose.ymlのYAMLファイルを作成して開きます。
nano docker-compose.yml以下のコードをコピーして、YAMLファイルに貼り付けます。
services:
langchain_neo4j:
build:
context: .
dockerfile: langchain.Dockerfile
image: langchain
runtime: nvidia
container_name: langchain
ports:
- "8888:8888"
volumes:
- .:/app/langchain
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: 1
capabilities: [gpu]
networks:
- app-network
depends_on:
- neo4j
command: >
bash -c '/usr/local/bin/ollama serve & /app/.venv/bin/jupyter lab --ip="*" --port=8888 --NotebookApp.token="" --NotebookApp.password="" --no-browser --allow-root'
neo4j:
build:
context: .
dockerfile: neo4j.Dockerfile
image: neo4j_with_apoc
container_name: neo4j
ports:
- "7474:7474"
- "7687:7687"
volumes:
- ./data:/data
- ./plugins:/plugins
- ./import:/import
environment:
- NEO4J_apoc_export_file_enabled=true
- NEO4J_apoc_import_file_enabled=true
- NEO4J_apoc_import_file_use__neo4j__config=true
- NEO4J_dbms_security_procedures_unrestricted=apoc.*
- NEO4J_dbms_memory_heap_initial__size=512m
- NEO4J_dbms_memory_heap_max__size=2G
- NEO4J_apoc_uuid_enabled=true
- NEO4J_dbms_default__listen__address=0.0.0.0
- NEO4J_dbms_allow__upgrade=true
- NEO4J_dbms_default__database=neo4j
- NEO4J_AUTH=neo4j/your_password
restart: unless-stopped
networks:
- app-network
networks:
app-network:
driver: bridgebash -c '/usr/local/bin/ollama serve & /app/.venv/bin/jupyter lab --ip="*" --port=8888 --NotebookApp.token="" --NotebookApp.password="" --no-browser --allow-root'Ollama ServerとJupyterサーバーを起動します。
bash -c '/usr/local/bin/ollama serve:Ollama Serverを起動しています。
PythonのOllamaを使用する際に、Ollama Serverを起動しておく必要がありますので、ご注意ください。
& /app/.venv/bin/jupyter lab --ip="*" --port=8888 --NotebookApp.token="" --NotebookApp.password="" --no-browser --allow-root'
JupyterLabを8888番ポートで起動しています。
environment:
- NEO4J_apoc_export_file_enabled=true
- NEO4J_apoc_import_file_enabled=true
- NEO4J_apoc_import_file_use__neo4j__config=true
- NEO4J_dbms_security_procedures_unrestricted=apoc.*
- NEO4J_dbms_memory_heap_initial__size=512m
- NEO4J_dbms_memory_heap_max__size=2G
- NEO4J_dbms_default__database=neo4j
- NEO4J_AUTH=neo4j/your_passwordNeo4jデータベースの環境設定をしています。
NEO4J_apoc_export_file_enabled=true:APOCのエクスポート機能を有効化します。
NEO4J_apoc_import_file_enabled=true:APOCのインポート機能を有効化します。
NEO4J_apoc_import_file_use__neo4j__config=true:データインポート時に、ディレクトリ(/import)内のファイルを扱えるようにしています。
NEO4J_dbms_security_procedures_unrestricted=apoc.*:APOCライブラリ内のすべてのプロシージャを許可します。
NEO4J_dbms_memory_heap_initial__size=512m:ヒープメモリの初期サイズを512MBに設定します。
NEO4J_dbms_default__database=neo4j:デフォルトのデータベース名をneo4jに設定します。
NEO4J_AUTH=neo4j/your_password:Neo4jの認証情報を(ユーザー名:neo4j、パスワード:your_password)に指定しています。
Dockerfileからビルドしてコンテナを起動します。
docker compose up
Dockerの起動後にブラウザの検索窓に”localhost:8888″を入力すると、Jupyter Labをブラウザで表示できます。
localhost:8888GraphRAGの実装

Dockerコンテナで起動したJupyter Lab上で、GraphRAGの実装をします。
Neo4jに関する環境変数を設定します。
import os
from langchain_neo4j import Neo4jGraph
os.environ["NEO4J_URI"] = "bolt://neo4j:7687"
os.environ["NEO4J_USERNAME"] = "neo4j"
os.environ["NEO4J_PASSWORD"] = "your_password"
url=os.getenv("NEO4J_URI")
username=os.getenv("NEO4J_USERNAME")
password=os.getenv("NEO4J_PASSWORD")
graph = Neo4jGraph()os.environ["NEO4J_URI"] = "bolt://neo4j:7687"
os.environ["NEO4J_USERNAME"] = "neo4j"
os.environ["NEO4J_PASSWORD"] = "your_password"Neo4jに関する環境変数を設定します。
NEO4J_URI: データベースへの接続URIです。この例では、Neo4jがboltプロトコルを使用して、ローカルのポート7687で接続されています。
NEO4J_USERNAME: データベースにアクセスするためのユーザー名です。
NEO4J_PASSWORD: データベース接続のパスワードです。「your_password」が設定されていますが、実際の使用時には適切な値に置き換える必要があります。
graph = Neo4jGraph()Neo4jGraphクラスのインスタンスを作成します。
このインスタンスはNeo4jデータベースとの接続やクエリ実行を可能にします。
Neo4jデータベース内のすべてのノードとリレーションシップを削除し、初期化します。
graph.query("MATCH (n) DETACH DELETE n;")graph.query("MATCH (n) DETACH DELETE n;")Neo4jデータベース内のすべてのノードとリレーションシップを削除し、初期化します。
MATCH (n):Neo4jのCypherクエリで、すべてのノード (n) を検索します。
DETACH: ノードに関連付けられているすべてのリレーションシップを削除します。
Neo4jではリレーションシップが存在するノードは直接削除できません。そのため、先にリレーションシップを削除する必要があります。
DELETE n: ノード自体を削除します。
LLMモデル「Llama 3.1」をダウンロードします。
LLMの実行にはOllamaを使用します。
import ollama
ollama.pull('llama3.1')Llama 3.1については、別記事で詳しく解説しています。

LangChain上でOllamaとLLMのモデルが使えるように設定します。
from langchain_experimental.llms.ollama_functions import OllamaFunctions
llm = OllamaFunctions(model="llama3.1", temperature=0, format="json")llm = OllamaFunctions(model="llama3.1", temperature=0, format="json")OllamaでLLMのモデルが使えるように、モデルやパラメーター、出力形式を指定します。
model="llama3.1":
- 使用する言語モデルの指定しています。
temperature=0:
- モデルの創造性やランダム性を制御するパラメータです。
0は最も決定論的な設定であり、一貫性と正確性を重視した応答を生成します。
format="json":
- 出力形式をJSONに指定します。
Ollamaの詳しい使い方は、別の記事で解説しています。

テキストをベクトル表現に変換する埋め込みモデルを読み込みます。
無料で使える埋め込みモデル「mxbai-embed-large」を指定しています。
from langchain_ollama import OllamaEmbeddings
ollama.pull('mxbai-embed-large')
embeddings = OllamaEmbeddings(model="mxbai-embed-large")ollama.pull('mxbai-embed-large')指定したモデルをOllamaの環境にダウンロードします。
embeddings = OllamaEmbeddings(model="mxbai-embed-large")ダウンロードしたモデルを使用して、埋め込み生成用のインスタンスを作成します。
Neo4jデータベースの構築

『ワンピース』のWikiのからテキストを抽出しています。
データの読み込みとチャンク分割を行います。
from langchain_community.document_loaders import TextLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_path = "./text.txt"
loader = TextLoader(text_path)
raw_documents = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=250, chunk_overlap=24)
documents = text_splitter.split_documents(raw_documents)text_path = "./text.txt"
loader = TextLoader(text_path)
raw_documents = loader.load()テキストファイルを読み込みます。
text_path = "./text.txt": 読み込むテキストファイルのパスを指定します。text.txtは、『ワンピース』のWikiのデータから作成しています。
loader.load(): 実際にテキストファイルを読み込みます。
text_splitter = RecursiveCharacterTextSplitter(chunk_size=250, chunk_overlap=24)
documents = text_splitter.split_documents(raw_documents)テキストデータをチャンク分割します。
chunk_size=250: 各チャンクのサイズを最大250文字に設定します。
chunk_overlap=24: 各チャンクの間で24文字分の重複を持たせます。重複により、分割されるテキスト間の文脈の継続性を保持しやすくなります。
split_documents(raw_documents): 読み込んだドキュメントを設定されたサイズと重複のルールに基づいて分割します。
ドキュメントからエンティティとリレーションシップを抽出してグラフ構造に変換し、Neo4jのグラフデータベースに保存します。
from langchain.graphs import Neo4jGraph
from langchain_experimental.graph_transformers import LLMGraphTransformer
llm_transformer = LLMGraphTransformer(llm=llm)
graph_documents = llm_transformer.convert_to_graph_documents(documents)
graph.add_graph_documents(
graph_documents,
baseEntityLabel=True,
include_source=True
)llm_transformer = LLMGraphTransformer(llm=llm)
graph_documents = llm_transformer.convert_to_graph_documents(documents)LLMを用いて、ドキュメントからエンティティやリレーションシップを抽出して、グラフデータの構造に変換します。
- 文書中のエンティティ(例: 人物、組織、場所など)をノードとして抽出。
- それらのエンティティ間の関係性(リレーションシップ)をエッジとして抽出。
graph.add_graph_documents(
graph_documents,
baseEntityLabel=True,
include_source=True
)Neo4jデータベースにグラフデータの追加や設定をします。
graph_documents: LLMによって変換されたグラフ形式のデータ(エンティティとリレーションシップ)を追加します。baseEntityLabel=True: すべてのエンティティにベースラベル(基本的なカテゴリ)を追加します。例:Person,Locationなどのラベルが付与されます。include_source=True: 元のドキュメント情報をエンティティやリレーションシップに含めます。
ハイブリット検索を行う非構造化データ用のリトリーバーを構築します。
ハイブリット検索とは、ベクトル検索とキーワード検索を組み合わせた手法です。
from langchain_community.vectorstores import Neo4jVector
hybrid_index = Neo4jVector.from_existing_graph(
embeddings,
search_type="hybrid",
node_label="Document",
text_node_properties=["text"],
embedding_node_property="embedding",
)
unstructured_retriever = hybrid_index.as_retriever()hybrid_index = Neo4jVector.from_existing_graph(
embeddings,
search_type="hybrid",
node_label="Document",
text_node_properties=["text"],
embedding_node_property="embedding",
)ハイブリット検索インデックスの設定をします。
embeddings:埋め込みモデルを指定します。テキストをベクトル化し、意味的な類似度を計算するために使用されます。
search_type="hybrid":検索タイプをハイブリッド検索に指定しています。
ハイブリッド検索とは、ベクトル検索とキーワード検索を組み合わせた手法です。
node_label="Document":
Neo4jデータベース内の「Document」のラベル名を持つノードを検索対象としています。
text_node_properties=["text"]:
「text」のプロパティ名を持つノードを検索対象としています。このプロパティには、テキストデータが格納され、全文検索に使用されます。
embedding_node_property="embedding":
「embedding」のプロパティ名を持つノードを検索対象としています。このプロパティには、ベクトルデータが格納され、ベクトル検索に使用されます。
unstructured_retriever = hybrid_index.as_retriever()ハイブリット検索インデックスからクエリに基づいて関連情報を取得するリトリーバーを作成します。
Neo4jデータベースに対して、全文検索インデックスを作成します。
Neo4jデータベースの「Entity」ラベルを持つノードの「id」プロパティに対して、全文検索ができるインデックスです。
from neo4j import GraphDatabase
driver = GraphDatabase.driver(uri=url, auth=(username, password))
def create_fulltext_index(tx):
query = '''
CREATE FULLTEXT INDEX `fulltext_entity_id`
FOR (n:__Entity__)
ON EACH [n.id];
'''
tx.run(query)
def create_index():
with driver.session() as session:
session.execute_write(create_fulltext_index)
print("Fulltext index created successfully.")
try:
create_index()
except:
pass
driver.close()driver = GraphDatabase.driver(uri=url, auth=(username, password))Neo4jデータベースへの接続を確立します。
def create_fulltext_index(tx):
query = '''
CREATE FULLTEXT INDEX `fulltext_entity_id`
FOR (n:__Entity__)
ON EACH [n.id];
'''
tx.run(query)Neo4jに対して全文検索インデックスを作成するクエリを定義します。
create_fulltext_index(tx):tx内でクエリを実行します。
CREATE FULLTEXT INDEX fulltext_entity_id``:インデックス名をfulltext_entity_idと定義しています。FOR (n:__Entity__):__Entity__ラベルが付いたノードがインデックスの対象になります。ON EACH [n.id]:ノードのプロパティidが全文検索の対象になります。
def create_index():
with driver.session() as session:
session.execute_write(create_fulltext_index)
print("Fulltext index created successfully.")Neo4jのセッションを開き、全文検索インデックスを作成するクエリを実行します。
with driver.session():Neo4jとのセッションを開きます。session.execute_write(create_fulltext_index):書き込みトランザクションモードで、Neo4jに対して、全文検索インデックス作成クエリを実行します。
try:
create_index()
except:
pass
driver.close()インデックス作成時に発生する例外処理
try...except:インデックス作成時にすでに同じインデックスが存在していたり、エラーが発生した場合でも、プログラムを停止せずに処理を続行します。driver.close():データベース接続をクローズします。
ブラウザからhttp://localhost:7474にアクセスして、Neo4jの管理画面を開きます。
http://localhost:7474サイドバーの「データベースアイコン」をクリックします。
ノードラベルから「Person」を選択します。
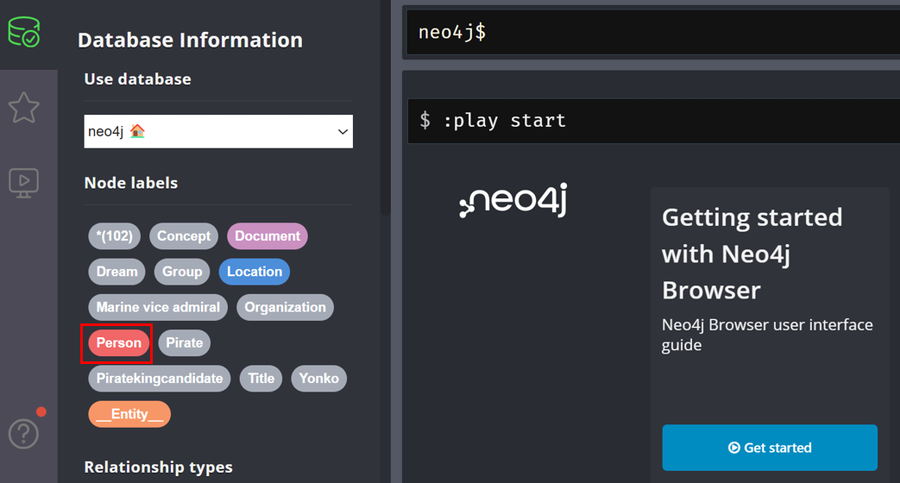
「Person」ノードのリレーションシップ図が表示されます。
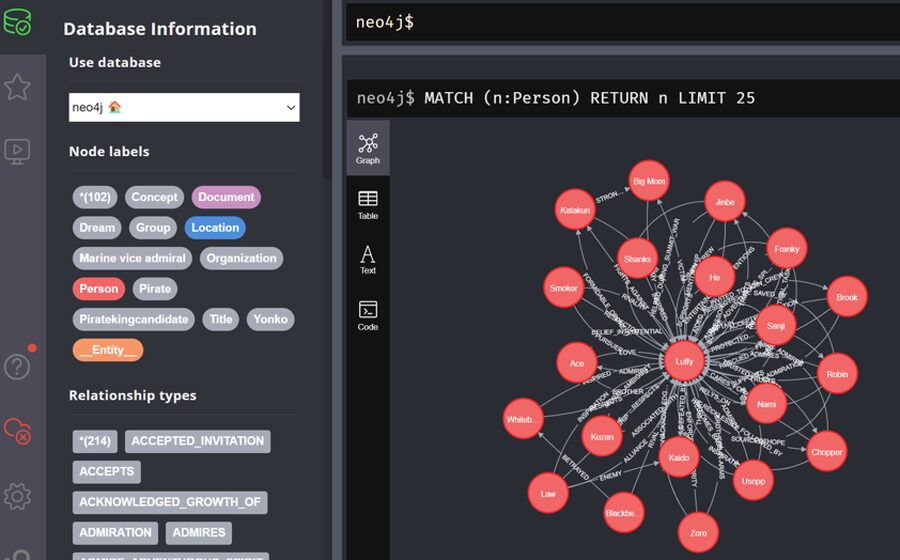
GraphRAGの構築

テキストからエンティティ(人物や組織など)の構造化データを抽出します。
from pydantic import BaseModel, Field
from langchain_core.prompts import ChatPromptTemplate
class Entities(BaseModel):
names: list[str] = Field(
...,
description="All the person, organization, or business entities that "
"appear in the text",
)
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"You are extracting organization and person entities from the text.",
),
(
"human",
"Use the given format to extract information from the following "
"input: {question}",
),
]
)
entity_chain = prompt | llm.with_structured_output(Entities)
entity_chain.invoke({"question":"Who are Luffy and Shanks?"})class Entities(BaseModel):
names: list[str] = Field(
...,
description="All the person, organization, or business entities that "
"appear in the text",
)エンティティ情報を格納するためのデータモデルを定義しています。
Entitiesは、エンティティ(人物名や組織名など)を格納するためのデータモデルです。BaseModel: Pydanticから提供されるクラスで、データの型検証やバリデーション機能を提供します。names: list[str]: namesフィールドは、抽出された人名や組織名、企業名などのエンティティをリスト形式で保持します。Field(...):フィールドが必須であることを意味します。description:このフィールドの説明を記述しています。
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"You are extracting organization and person entities from the text.",
),
(
"human",
"Use the given format to extract information from the following "
"input: {question}",
),
]
)このプロンプトはLLMに対して、入力された質問文から組織名や人物名を特定するように指示します。
- システムメッセージでは、モデルに対する指示や役割を設定します。「組織や人物のエンティティを抽出する」ことを指示します。
- ユーザーメッセージでは、実際に人間がモデルに質問する部分を定義します。入力テキストから指定されたフォーマットに従って情報を抽出するように求めています。
entity_chain = prompt | llm.with_structured_output(Entities)
entity_chain.invoke({"question":"Who are Luffy and Shanks?"})エンティティ抽出用チェーンの構築し、エンティティの抽出を実行しています。
prompt | llm.with_structured_output(Entities):promptをllmに渡します。LLMの出力をEntitiesデータモデルに従って整形します。
entity_chain.invoke({"question":"Who are Luffy and Shanks?"}):作成したチェーンにクエリを入力して実行しています。
Lucene構文に基づく全文検索用のクエリを生成します。
Neo4jの全文検索機能はLuceneのクエリ構文を採用しているため、構文に適合した形式にしています。
この全文検索用クエリは、曖昧検索や複数条件検索に対応しています。
from langchain_community.vectorstores.neo4j_vector import remove_lucene_chars
def generate_full_text_query(input: str) -> str:
full_text_query = ""
words = [el for el in remove_lucene_chars(input).split() if el]
for word in words[:-1]:
full_text_query += f" {word}~2 AND"
full_text_query += f" {words[-1]}~2"
return full_text_query.strip()words = [el for el in remove_lucene_chars(input).split() if el]Luceneにおける特殊文字の除去や空要素を除外し、空でない単語のみをリストに格納します。
remove_lucene_chars(input):Luceneクエリにおける特殊文字を取り除き正規化します。- 特殊文字の例:
+ - && || ! ( ) { } [ ] ^ " ~ * ? : \ /など。
- 特殊文字の例:
.split():入力文字列をスペース区切りで単語に分割し、単語リストを作成します。if el:空白文字列を除外します。
for word in words[:-1]:
full_text_query += f" {word}~2 AND"
full_text_query += f" {words[-1]}~2"曖昧検索や複数キーワード検索に対応します。
full_text_query += f" {word}~2 AND":- 各単語に曖昧検索の指定
~2を追加します。 ~2は、2文字以内の違いがある単語を検索対象に含み、類似した単語を検索できます。- 単語同士は
AND演算子で結合し、複数条件を満たす検索を指定します。
- 各単語に曖昧検索の指定
full_text_query += f" {words[-1]}~2":ループ外で処理される最後の単語にも曖昧検索指定(~2)を追加しますが、無効なクエリとならないように、最後の単語には AND 演算子を付けません。
return full_text_query.strip()クエリの前後に不要なスペースがあれば除去して返します。
グラフ検索をする構造化データ用のリトリーバーを構築します。
質問文からエンティティを抽出し、エンティティと一致するノードを検索します。
検索したノードに関連する隣接ノードとリレーションシップを検索するリトリーバーです。
def structured_retriever(question: str) -> str:
result = ""
entities = entity_chain.invoke(question)
for entity in entities.names:
response = graph.query(
"""
CALL db.index.fulltext.queryNodes('fulltext_entity_id', $query, {limit:2})
YIELD node, score
CALL (node) {
WITH node
MATCH (node)-[r:!MENTIONS]->(neighbor)
RETURN node.id + ' - ' + type(r) + ' -> ' + neighbor.id AS output
UNION ALL
WITH node
MATCH (node)<-[r:!MENTIONS]-(neighbor)
RETURN neighbor.id + ' - ' + type(r) + ' -> ' + node.id AS output
}
RETURN output LIMIT 50
""",
{"query": generate_full_text_query(entity)},
)
result += "\n".join(el["output"] for el in response)
return result
print(structured_retriever("Who is Luffy?"))entities = entity_chain.invoke(question)質問文questionを入力として、エンティティ抽出をするチェーンを実行します。
for entity in entities.names:抽出されたエンティティごとに、グラフ検索のクエリを実行します。
graph.query(
"""
CALL db.index.fulltext.queryNodes('fulltext_entity_id', $query, {limit:2})
YIELD node,score
(省略)
""",
{"query": generate_full_text_query(entity)},
)全文検索インデックスを使用して、エンティティに一致するノードを検索します。
graph.query()の動作の流れ{"query": generate_full_text_query(entity)}は、Lucene形式の検索クエリを作成します。- 上記で作成したクエリを以下の
$queryに挿入します。 CALL db.index.fulltext.queryNodesを使い、Neo4jの全文検索インデックスからエンティティ名に関連するノードを検索します。
graph.query()の引数の説明fulltext_entity_id:全文検索インデックス名を指定しています。$query:クエリに一致するノードを検索します。(エンティティに関連するノードを検索){limit:2}:取得する最大ノード数を2つに設定しています。
YIELD node, score:CALLが返すデータの中からどのフィールドを抽出するかを指定します。ここでは検索されたノードとマッチングのスコアを取得しています。
{"query": generate_full_text_query(entity)}:
entityを入力として受け取り、Lucene形式の検索クエリを作成します。検索クエリは曖昧検索や複数条件検索に対応しています。ここで作成したクエリが上記の$queryに挿入されます。
CALL (node) {
WITH node
MATCH (node)-[r:!MENTIONS]->(neighbor)
RETURN node.id + ' - ' + type(r) + ' -> ' + neighbor.id AS output
UNION ALL
WITH node
MATCH (node)<-[r:!MENTIONS]-(neighbor)
RETURN neighbor.id + ' - ' + type(r) + ' -> ' + node.id AS output
}
RETURN output LIMIT 50指定されたノードとに関連する隣接ノードとリレーションシップを検索します。
CALL(node){ ... }:サブクエリを実行するために使用される構文です。WITH node:外部クエリからサブクエリに変数nodeを引き継ぐために使用されます。MATCH (node)-[r:!MENTIONS]->(neighbor):nodeに関連する隣接ノードと外向きのリレーションシップを検索します。neighborは、隣接ノード(関連するノード)です。[r:!MENTIONS]の!は、否定リレーション演算子で、MENTIONS以外の関係でつながっているノードを見つけます。
RETURN node.id + ' - ' + type(r) + ' -> ' + neighbor.id AS output:ノードのID、リレーションのタイプ、および隣接ノードのIDを文字列で結合し、output として返します- 例:
"Luffy - RESCUER -> Robin"
- 例:
UNION ALL:外向きと内向きのリレーションシップを個別に取得して、重複を排除しません。(node)<-[r:!MENTIONS]-(neighbor):nodeに向か内向きのリレーションシップを探索します。RETURN neighbor.id + ' - ' + type(r) + ' -> ' + node.id AS output:隣接ノードのID、リレーションのタイプ、およびノードのIDを文字列で結合し、output として返します。- 例:
Robin - ADMIRES -> Luffy
- 例:
- 結果制限:
LIMIT 50で最大50件の結果を取得します。
{"query": generate_full_text_query(entity)}クエリ文字列内の $query プレースホルダーに以下の値を動的に埋め込みます。
エンティティ名を Lucene構文の全文検索クエリに変換し、曖昧検索や複数条件の検索に対応した値が入ります。
result += "\n".join([el['output'] for el in response])リストから文字列への変換し、改行区切りで連結します。
出力結果を一部抜粋
Luffy - RESCUER -> Robin
Luffy - FIGHTS_AGAINST -> Katakuri
Luffy - RESCUED -> Sanji
Luffy - ADMIRES -> Ace
Luffy - INVITED_TO_JOIN_CREW -> Brook
Luffy - TRUSTS -> Jinbe
Luffy - ACCEPTS -> Chopper
Luffy - RELYS_ON -> Nami
Luffy - WELCOMES_BACK -> Usopp
Luffy - IS_RECKLESSLY_FOLLOWED_BY -> Chopper
Usopp - SUPPORTS -> Luffy
Franky - SUPPORTS -> Luffy
Sanji - SUPPORTS -> Luffy
Robin - SAVED_BY -> Luffy
Ace - BROTHER -> Luffy
Big Mom - ENEMY -> Luffy
Usopp - FRIENDSHIP -> Luffy
Law - ALLIANCE -> Luffy質問に対して グラフ検索とハイブリット検索の結果を統合する関数を定義します。
def full_retriever(question: str):
structured_data = structured_retriever(question)
unstructured_data = [el.page_content for el in unstructured_retriever.invoke(question)]
final_data = f"""Structured data:
{structured_data}
unstructured_data:
{"#Document ". join(unstructured_data)}
"""
return final_datastructured_data = structured_retriever(question)質問をもとにグラフ検索を行い、エンティティやリレーションシップを取得します。
unstructured_data = [el.page_content for el in unstructured_retriever.invoke(question)]質問に関連する情報をハイブリット検索(ベクトル検索+キーワード検索)で取得します。
final_data = f"""Structured data:
{structured_data}
unstructured_data:
{"#Document ". join(unstructured_data)}
"""グラフ検索とハイブリット検索のデータをまとめて一つの文字列にフォーマットします。
質問とリトリーバーから取得した情報をもとにプロンプトを作成し、モデルに渡して生成するRAGチェーンを構築します。
from langchain_core.runnables import RunnablePassthrough
from langchain_core.output_parsers import StrOutputParser
template = """Answer the question based only on the following context:
{context}
Question: {question}
Use natural language and be concise.
Answer:"""
prompt = ChatPromptTemplate.from_template(template)
chain = (
{
"context": full_retriever,
"question": RunnablePassthrough(),
}
| prompt
| llm
| StrOutputParser()
)template = """Answer the question based only on the following context:
{context}
Question: {question}
Use natural language and be concise.
Answer:"""質問応答のテンプレートを作成します。
{context}:full_retrieverから取得したグラフ検索とハイブリット検索の統合データが入ります。{question}: ユーザーの質問が入ります。
chain = (
{
"context": full_retriever,
"question": RunnablePassthrough(),
}
| prompt
| llm
| StrOutputParser()
)入力データを順次処理して最終結果を生成するチェーンを作成します。
context:full_retrieverを呼び出し、グラフ検索とハイブリット検索の統合データを取得します。question: 質問はそのまま使用します。prompt:プロンプトテンプレートにデータを埋め込みます。llm:プロンプトに基づきLLMが自然言語で回答します。StrOutputParser():LLMの出力を文字列形式で解析し、最終的な結果を返します。
GraphRAGに『ONE PIECE』について聞いてみる

GraphRAGを使って、用意したデータの『ONE PIECE』について質問してみます。
GraphRAGに質問する(1)
「ルフィは誰ですか?彼の仲間は誰ですか?」と質問してみます。
chain.invoke(input="Who is Luffy? Who are his companions?")Who is Luffy? Who are his companions?
ルフィは誰ですか?彼の仲間は誰ですか?
‘Luffy is the captain of the Straw Hat Pirates. His companions include Zoro, Nami, Usopp, Sanji, Brook, Jinbe, Chopper, and Robin.’
ルフィは麦わらの一味の船長です。彼の仲間には、ゾロ、ナミ、ウソップ、サンジ、ブルック、ジンベエ、チョッパー、そしてロビンがいます。
GraphRAGに質問する(2)
「ルフィの敵は誰ですか? 」と質問してみます。
chain.invoke(input="Who are Luffy's enemies?")Who are Luffy’s enemies?
ルフィの敵は誰ですか?
“Luffy’s enemies include Blackbeard(Teach), Kaido, Big Mom, and Smoker.”
ルフィの敵には、黒ひげ(ティーチ)、カイドウ、ビッグ・マム、そしてスモーカーが含まれます。
GraphRAGに質問する(3)
「ルフィの兄弟は誰ですか?」と質問してみます。
chain.invoke(input="Who are Luffy's brother?")Who are Luffy’s brother?
ルフィの兄弟は誰ですか?
“Luffy’s older brother is Ace.”
ルフィの兄はエースです。
生成AI・LLMのコストでお困りなら
GPUのスペック不足で生成AIの開発が思うように進まないことはありませんか?
そんなときには、高性能なGPUをリーズナブルな価格で使えるGPUクラウドサービスがおすすめです!

GPUSOROBANは、高性能GPU「NVIDIA H200」を業界最安級の料金で使用することができます。
NVIDIA H200は、生成AI・LLMの計算にかかる時間を大幅に短縮することが可能です。
クラウドで使えるため、大規模な設備投資の必要がなく、煩雑なサーバー管理からも解放されます。







