
DataGemma は、Googleが開発したLLMのハルシネーションを抑制のための技術です。
この記事では、DataGemmaの概要から商用利用、使い方までを紹介します。
ざっくり言うと
- DataGemma は、Googleが開発したLLMのハルシネーションを抑制のための技術
- Apache License 2.0で提供され、無料で商用利用が可能
- DataGemmaのRIGモデル、RAGモデルの使い方を解説

DataGemmaとは

DataGemma は、Googleが開発したLLMのハルシネーションを抑制のための技術です。
DataGemmaは、Data Commonsから信頼できる統計データを取得し、RIGとRAGを用いて、LLMの出力が事実に基づいた信頼性の高い内容になるようサポートしています。

DataGemmaのモデル(RAG・RIG)

DataGemmaはRIGモデルとRAGモデルを、それぞれHuggingFaceで公開しています。
| モデルID | パラメータサイズ | 特徴 | GPUメモリ使用量 |
|---|---|---|---|
| google/datagemma-rig-27b-it | 270億パラメータ | RIGモデル | 20GB(BF16、4bit量子化) |
| google/datagemma-rag-27b-it | 270億パラメータ | RAGモデル | 20GB(BF16、4bit量子化) |
RIGは、Data Commonsの信頼できる情報を参照し、DataGemmaモデルが回答を生成する際に事実確認を行うアプローチです。
RAGは、LLMが学習データ以外の関連情報を取り込むアプローチです。生成の前段階でData Commonsからクエリに関連する情報を取得して、プロンプトに組み込むことで、より広いコンテキストに基づいた回答を実現します。
DataGemmaの商用利用・ライセンス

DataGemmaは、Gemmaのライセンス(Apache License 2.0)に基づいて提供されています。
商用利用が可能ですが、現時点では主に研究や学術目的での利用が推奨されています。
商用利用:ソフトウェアやコードを商用利用することが許可されています。
改変:ソフトウェアやコードを自由に修正したり改変したりすることができます。
配布:修正したり変更したりしたソフトウェアを自由に配布することができます。
著作権表示:元の著作権表示とライセンス条項を含める必要があります。
特許利用:利用者に特許使用権が付与されています。
詳細はGemmaの利用規約をご確認ください。
DataGemmaの利用申請

DataGemmaのモデルをダウンロードするには、事前に利用申請が必要になります。
ここでは、モデルの利用申請の方法を解説していきます。
HuggingFaceのモデルページにアクセスして、「Acknowledge license」をクリックします。
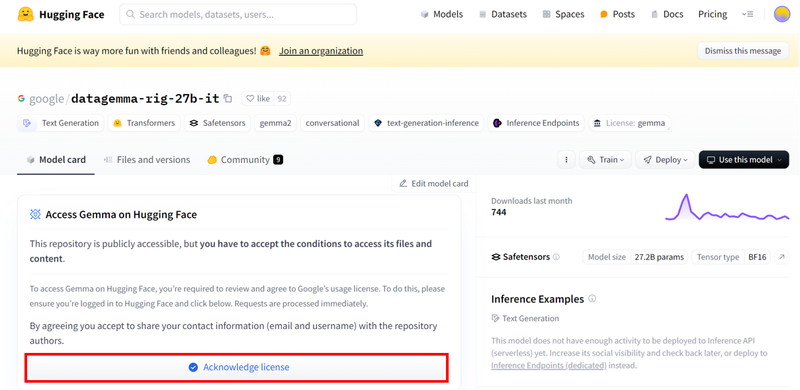
KaggleからHuggingFaceのアカウントの連絡先情報にアクセスすることを許可したうえで、[Authorize]ボタンをクリックします。
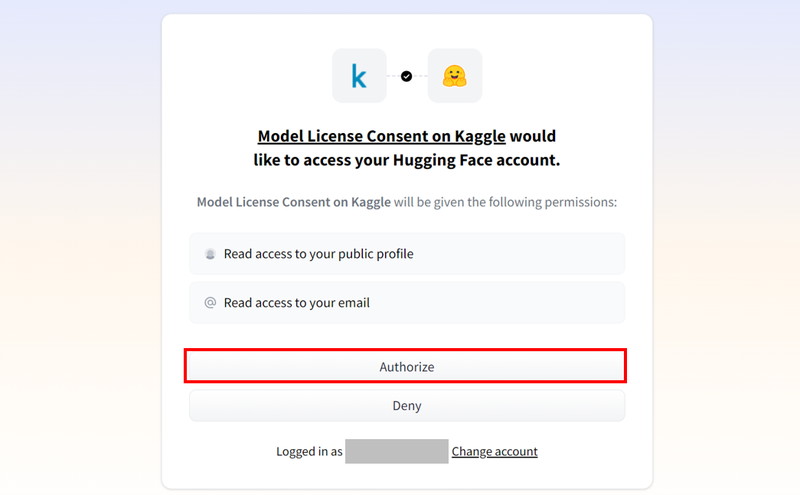
ユーザー情報を入力し、[I accept the terms and conditions(Reauired)*]にチェックをいれて、[Accept]ボタンをクリックします。
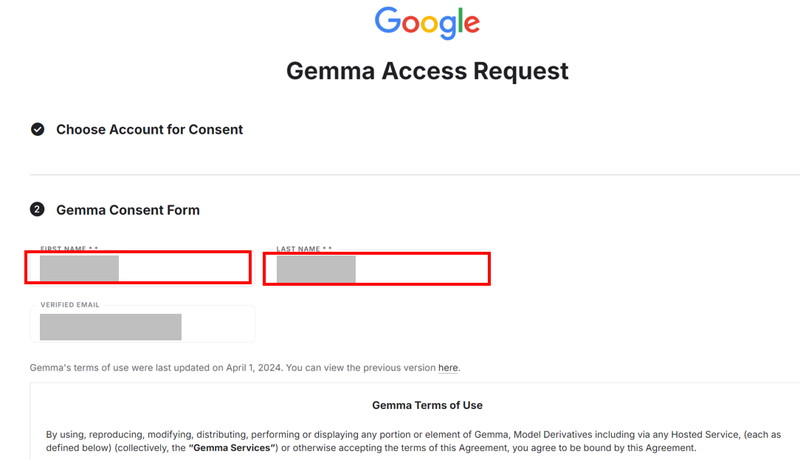
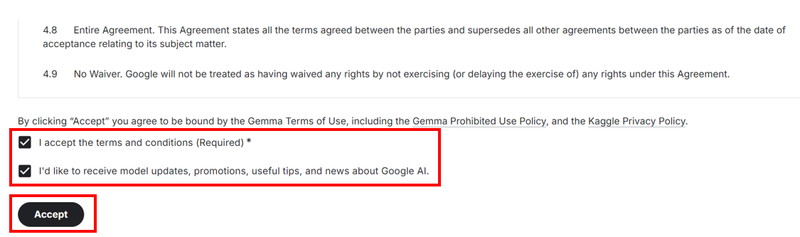
Gemmaのモデルページに、[Gated model You have been granted access to this model]と表示されたら、利用申請が完了です。
DataGemmaの環境構築

ここからDataGemmaの使い方について解説していきます。
実行環境
この記事で用意した実行環境は以下のとおりです。
- GPU:NVIDIA A100 80GB
- GPUメモリ(VRAM):80GB
- OS :Ubuntu 22.04
- Docker
Dockerで環境構築
Dockerを使用してGemma2の環境構築をします
Dockerの使い方は以下の記事をご覧ください。

コンテナにインストールするパッケージは以下のとおりです。
CUDA、PyTorch、Transformersはバージョン依存関係によるエラーが起きやすいので、動作検証済のバージョン指定してインストールしています。
- CUDA:12.1
- Python:3.10
- PyTorch:2.2.2
- transformers:4.45.0
- accelerate
Ubuntuのコマンドラインで、Dockerfileを作成します。
mkdir datagemma
cd datagemma
nano DockerfileDockerfileに以下の記述を貼り付けます。
# ベースイメージ(CUDA)の指定
FROM nvidia/cuda:12.1.0-cudnn8-devel-ubuntu22.04
# 必要なパッケージをインストール
RUN apt-get update && apt-get install -y python3-pip python3-venv git nano
# 作業ディレクトリを設定
WORKDIR /app
# アプリケーションコードをコピー
COPY . /app
# Python仮想環境の作成
RUN python3 -m venv /app/.venv
# 仮想環境をアクティベートするコマンドを.bashrcに追加
RUN echo "source /app/.venv/bin/activate" >> /root/.bashrc
# JupyterLabのインストール
RUN /app/.venv/bin/pip install Jupyter jupyterlab
# PyTorchのインストール
RUN /app/.venv/bin/pip install torch==2.2.2 torchvision==0.17.2 torchaudio==2.2.2 --index-url https://download.pytorch.org/whl/cu121
# Transformer関連のインストール
RUN /app/.venv/bin/pip install transformers==4.45.0 accelerate bitsandbytes
# DataGemma関連リポジトリのインストール
RUN /app/.venv/bin/pip install -q git+https://github.com/datacommonsorg/llm-tools
# コンテナの起動時にbashを実行
CMD ["/bin/bash"]docker-compose.ymlでDockerコンテナの設定をします。
docker-compose.ymlのYAMLファイルを作成して開きます。
nano docker-compose.yml以下のコードをコピーして、YAMLファイルに貼り付けます。
services:
datagemma:
build:
context: .
dockerfile: Dockerfile
image: datagemma
runtime: nvidia
container_name: datagemma
ports:
- "8888:8888"
volumes:
- .:/app/datagemma
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: 1
capabilities: [gpu]
command: >
bash -c '/app/.venv/bin/jupyter lab --ip="*" --port=8888 --NotebookApp.token="" --NotebookApp.password="" --no-browser --allow-root'Dockerfileからビルドしてコンテナを起動します。
docker compose up
Dockerの起動後にブラウザの検索窓に”localhost:8888″を入力すると、Jupyter Labをブラウザで表示できます。
localhost:8888DataGemma RIGの実装

Dockerコンテナで起動したJupyter Lab上でDataGemma RIGの実装をします。
環境変数を設定します。
import os
import data_gemma as dg
os.environ["DC_API_KEY"] = "***********************************"
os.environ["HF_TOKEN"] = "***********************************"
dc = dg.DataCommons(api_key=os.environ["DC_API_KEY"])
hf_token = os.environ["HF_TOKEN"]os.environ[“DC_API_KEY”]
Data CommonsのAPIキーを環境変数として設定しています。
os.environ[“HF_TOKEN”]
Hugging FaceのAPIトークンを設定しています。このトークンを使用して、Hugging Faceのモデルにアクセスすることができます。

DataGemmaのRIGモデルを読み込みます。
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
nf4_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16
)
model_name = 'google/datagemma-rig-27b-it'
tokenizer = AutoTokenizer.from_pretrained(model_name, token=hf_token)
datagemma_model = AutoModelForCausalLM.from_pretrained(model_name,
device_map="auto",
quantization_config=nf4_config,
torch_dtype=torch.bfloat16,
token=hf_token)
datagemma_model_wrapper = dg.HFBasic(datagemma_model, tokenizer)nf4_config = BitsAndBytesConfig(…
BitsAndBytesConfigクラスを使って、モデルを4ビットの精度で量子化する設定を行っています。量子化は、モデルのメモリ使用量を削減し、より少ないリソースでの実行を可能にします。bnb_4bit_compute_dtype=torch.bfloat16:計算の際に使われるデータ型をbfloat16に設定しています。load_in_4bit=True:モデルを4ビット精度でロードすることを示しています。bnb_4bit_quant_type="nf4":nf4という量子化形式を使用します。
model_name = ‘google/datagemma-rig-27b-it’
DataGemmaのRIGモデルを指定しています。
tokenizer = AutoTokenizer.from_pretrained(model_name, token=hf_token)
指定したmodel_nameに対応するトークナイザーをロードしています。
datagemma_model = AutoModelForCausalLM.from_pretrained(…
AutoModelForCausalLMクラスを使って指定されたモデルをロードしています。token=hf_token:Hugging FaceのAPIトークンを指定して、適切な認証を行います。device_map="auto":モデルを自動的に最適なデバイス(CPUまたはGPU)に配置します。quantization_config=nf4_config:4ビット量子化の設定を適用します。torch_dtype=torch.bfloat16:計算の際のデータ型をbfloat16に指定しています。
datagemma_model_wrapper = dg.HFBasic(datagemma_model, tokenizer)
HFBasicクラスを使用して、ロードしたモデルとトークナイザーのwrapperを作成しています。これにより直接的にモデルやトークナイザーを扱う必要がなく、簡単にトークナイズやモデル実行ができるようになります。
DataGemmaのRIGモデルを使用して、質問に回答します。
from IPython.display import Markdown
import textwrap
def display_chat(prompt, text):
formatted_prompt = "<font size='+1' color='brown'>User:<blockquote>" + prompt + "</blockquote></font>"
text = text.replace('•', ' *')
text = textwrap.indent(text, '> ', predicate=lambda _: True)
formatted_text = "<font size='+1' color='teal'>AI:\n\n" + text + "\n</font>"
return Markdown(formatted_prompt+formatted_text)
def to_markdown(text):
text = text.replace('•', ' *')
return Markdown(textwrap.indent(text, '> ', predicate=lambda _: True))
QUERY = "What is the population of Japan"
ans = dg.RIGFlow(llm=datagemma_model_wrapper, data_fetcher=dc, verbose=False).query(query=QUERY)
Markdown(textwrap.indent(ans.answer(), '> ', predicate=lambda _: True))
display_chat(QUERY, ans.answer())def display_chat(prompt, text)…
ユーザーの質問と、それに対するLLMの回答を見やすい形式で表示するための関数です。
formatted_promptでは、ユーザーからの質問promptをフォーマットして、Markdown形式で表示します。text.replace('•', ' *')は、テキスト内の箇条書き記号「•」をMarkdownのリスト記号「*」に変換しています。textwrap.indent(text, '> ', predicate=lambda _: True)で、LLMからの回答をMarkdownの引用形式(「>」)でインデントしています。formatted_textでは、AIの回答をティールカラーでフォーマットしています。Markdownオブジェクトとしてユーザーの質問とLLMの回答を結合して返します。
def to_markdown(text)…
テキストをMarkdown形式で引用インデントして表示するための関数です。テキスト中の「•」を「*」に置き換え、すべての行を引用形式でインデントしてからMarkdownオブジェクトとして返します。
QUERY = “What is the population of Japan”
QUERYには、ユーザーの質問内容が入力されます。
ans = dg.RIGFlow(llm=datagemma_model_wrapper, data_fetcher=dc, verbose=False).query(query=QUERY)
dg.RIGFlow:DataGemmaモデルのRIGパイプラインを使ってクエリを実行しています。llm=datagemma_model_wrapper:LLMには事前に作成したWrapperを指定しています。data_fetcher=dc:Data Commonsのクライアントオブジェクトを使用して、必要なデータを取得します。verbose=False:詳細なログ出力を無効にしています。query(query=QUERY):ユーザーのクエリを使ってDataGemmaモデルに質問を投げかけています。
指定したmodel_nameに対応するトークナイザーをロードしています。
Markdown(textwrap.indent(ans.answer(), ‘> ‘, predicate=lambda _: True))
ans.answer()で取得した回答をMarkdown形式で引用インデントして表示しています。
display_chat(QUERY, ans.answer())
ユーザーのクエリと、DataGemmaモデルからの回答を渡して、結果をフォーマットし、表示します。
LLMの回答
... calling HF Pipeline API "What is the population of Japan..."
... calling DC with "what is the population of Japan?"
User:
What is the population of Japan
AI:
Japan has a population of around [DC#1(125124989 [1] || 125 million)] people.
It's important to note that this number is shrinking due to a low birth rate and limited immigration.
FOOTNOTES
[1] - Per datacatalog.worldbank.org, value was 125124989 in 2022. See more at https://datacommons.org/explore#q=what%20is%20the%20population%20of%20Japan%3F&mode=toolformer_rigDataGemma RAGの実装

Jupyter Lab上でDataGemma RAGの実装をします。
環境変数の設定をします。
import os
import data_gemma as dg
os.environ["DC_API_KEY"] = "****************************"
os.environ["HF_TOKEN"] = "****************************"
os.environ["GEMINI_API_KEY"] = "****************************"
dc = dg.DataCommons(api_key=os.environ["DC_API_KEY"])
hf_token = os.environ["HF_TOKEN"]
gemini_api_key = os.environ["GEMINI_API_KEY"]os.environ[“DC_API_KEY”]
Data CommonsのAPIキーを環境変数として設定しています。
os.environ[“HF_TOKEN”]
Hugging FaceのAPIトークンを設定しています。このトークンを使用して、Hugging Faceのモデルにアクセスすることができます。
os.environ[“GEMINI_API_KEY”]
Google GeminiモデルにアクセスするためのAPIキーを設定しています。
DataGemmaのRAGモデルを読み込みます。
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
gemini_model = dg.GoogleAIStudio(model='gemini-1.5-pro', api_keys=[gemini_api_key])
nf4_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16
)
model_name = 'google/datagemma-rag-27b-it'
tokenizer = AutoTokenizer.from_pretrained(model_name, token=hf_token)
datagemma_model = AutoModelForCausalLM.from_pretrained(model_name,
device_map="auto",
quantization_config=nf4_config,
torch_dtype=torch.bfloat16,
token=hf_token)
datagemma_model_wrapper = dg.HFBasic(datagemma_model, tokenizer)gemini_model = dg.GoogleAIStudio(model=’gemini-1.5-pro’, api_keys=[gemini_api_key])
gemini-1.5-proのモデルを初期化します。
nf4_config = BitsAndBytesConfig(…
BitsAndBytesConfigクラスを使って、モデルを4ビットの精度で量子化する設定を行っています。量子化は、モデルのメモリ使用量を削減し、より少ないリソースでの実行を可能にします。bnb_4bit_compute_dtype=torch.bfloat16:計算の際に使われるデータ型をbfloat16に設定しています。load_in_4bit=True:モデルを4ビット精度でロードすることを示しています。bnb_4bit_quant_type="nf4":nf4という量子化形式を使用します。
model_name = ‘google/datagemma-rag-27b-it’
DataGemmaのRAGモデルを指定しています。
tokenizer = AutoTokenizer.from_pretrained(model_name, token=hf_token)
指定したmodel_nameに対応するトークナイザーをロードしています。
datagemma_model = AutoModelForCausalLM.from_pretrained(…
AutoModelForCausalLMクラスを使って指定されたモデルをロードしています。token=hf_token:Hugging FaceのAPIトークンを指定して、適切な認証を行います。device_map="auto":モデルを自動的に最適なデバイス(CPUまたはGPU)に配置します。quantization_config=nf4_config:4ビット量子化の設定を適用します。torch_dtype=torch.bfloat16:計算の際のデータ型をbfloat16に指定しています。
datagemma_model_wrapper = dg.HFBasic(datagemma_model, tokenizer)
HFBasicクラスを使用して、ロードしたモデルとトークナイザーのwrapperを作成しています。これにより直接的にモデルやトークナイザーを扱う必要がなく、簡単にトークナイズやモデル実行ができるようになります。
DataGemmaのRAGモデルを使用して質問に回答します。
from IPython.display import Markdown
import textwrap
def display_chat(prompt, text):
formatted_prompt = "<font size='+1' color='brown'>User<blockquote>" + prompt + "</blockquote></font>"
text = text.replace('•', ' *')
text = textwrap.indent(text, '> ', predicate=lambda _: True)
formatted_text = "<font size='+1' color='teal'>AI\n\n" + text + "\n</font>"
return Markdown(formatted_prompt+formatted_text)
def to_markdown(text):
text = text.replace('•', ' *')
return Markdown(textwrap.indent(text, '> ', predicate=lambda _: True))
QUERY = "Compare the GDP of Japan and India."
ans = dg.RAGFlow(llm_question=datagemma_model_wrapper, llm_answer=gemini_model, data_fetcher=dc).query(query=QUERY)
Markdown(textwrap.indent(ans.answer(), '> ', predicate=lambda _: True))
display_chat(QUERY, ans.answer())def display_chat(prompt, text)…
ユーザーの質問と、それに対するLLMの回答を見やすい形式で表示するための関数です。
formatted_promptでは、ユーザーからの質問promptをフォーマットして、Markdown形式で表示します。text.replace('•', ' *')は、テキスト内の箇条書き記号「•」をMarkdownのリスト記号「*」に変換しています。textwrap.indent(text, '> ', predicate=lambda _: True)で、LLMからの回答をMarkdownの引用形式(「>」)でインデントしています。formatted_textでは、AIの回答をティールカラーでフォーマットしています。Markdownオブジェクトとしてユーザーの質問とLLMの回答を結合して返します。
def to_markdown(text)…
テキストをMarkdown形式で引用インデントして表示するための関数です。テキスト中の「•」を「*」に置き換え、すべての行を引用形式でインデントしてからMarkdownオブジェクトとして返します。
QUERY = “Compare the GDP of Japan and India.”
QUERYには、ユーザーの質問内容が入力されます。
ans = dg.RAGFlow(llm_question=datagemma_model_wrapper, llm_answer=gemini_model, data_fetcher=dc).query(query=QUERY)
dg.RIGFlow:DataGemmaモデルのRIGパイプラインを使ってクエリを実行しています。llm=datagemma_model_wrapper:質問の関連性について処理をするLLMを指定しています。llm_answer=gemini_model: 最終的な回答を生成するためのLLMを指定しています。data_fetcher=dc:Data Commonsのクライアントオブジェクトを使用して、必要なデータを取得します。verbose=False:詳細なログ出力を無効にしています。query(query=QUERY):ユーザーのクエリを使ってDataGemmaモデルに質問を投げかけています。
指定したmodel_nameに対応するトークナイザーをロードしています。
Markdown(textwrap.indent(ans.answer(), ‘> ‘, predicate=lambda _: True))
ans.answer()で取得した回答をMarkdown形式で引用インデントして表示しています。
display_chat(QUERY, ans.answer())
ユーザーのクエリと、DataGemmaモデルからの回答を渡して、結果をフォーマットし、表示します。
LLMの回答
... [RAG] Calling FINETUNED model for DC questions
... calling HF Pipeline API ""
Your role is that of a Question Generator. Give..."
... [RAG] Making DC Calls
... calling DC for table with "What is the GDP of India?"
... calling DC for table with "What is the GDP of Japan?"
... [RAG] Calling UNTUNED model for final response
... calling AIStudio gemini-1.5-pro "Using statistics from the tables below, respond t..."
User
Compare the GDP of Japan and India.
AI
Japan's nominal GDP in 2022 was
3416645826052.87 [Table 1]. This means that Japan's economy was larger than India's in 2022. Looking back at the historical data, Japan's GDP has consistently been larger than India's since at least 1960 [Table 1], [Table 2].
TABLES
Table 1: GDP (Nominal Value) in India (unit: USD), according to datacatalog.worldbank.org date | GDP (Nominal Value)
2022 | 3416645826052.87 2021 | 3150306839142.13 2020 | 2671595405986.86 2019 | 2835606256616.03 2018 | 2702929641707.38 2017 | 2651474262735.28 2016 | 2294796885682.55 2015 | 2103588360066.32 2014 | 2039126479228.11 2013 | 1856721507681.08 2012 | 1827637590787.19 2011 | 1823051829900.81 2010 | 1675615519489.35 2009 | 1341888016984.36 2008 | 1198895139014.62 2007 | 1216736438842.41 2006 | 940259888794.351 2005 | 820381595510.643 2004 | 709148514815.787 2003 | 607699285436.048 2002 | 514937948874.212 2001 | 485441014538.638 2000 | 468394937255.803 1999 | 458820417337.807 1998 | 421351317224.941 1997 | 415867563592.829 1996 | 392896866204.516 1995 | 360281909643.489 1994 | 327275583530.004 1993 | 279295648982.529 1992 | 288208070278.013 1991 | 270105341879.226 1990 | 320979026420.035 1989 | 296042052944.66 1988 | 296589670895.932 1987 | 279033584092.223 1986 | 248985994040.59 1985 | 232511554840.372 1984 | 212157645177.652 1983 | 218262146413.158 1982 | 200715624830.902 1981 | 193491368445.573 1980 | 186325345086.661 1979 | 152991653793.77 1978 | 137300295313.3 1977 | 121486641441.309 1976 | 102717164466.397 1975 | 98472796456.884 1974 | 99525899116.054 1973 | 85515269585.4 1972 | 71463193831.0092 1971 | 67351404351.833 1970 | 62422483054.6667 1969 | 58447995017.3333 1968 | 53085455870.6667 1967 | 50134942204 1966 | 45865462034.2857 1965 | 59554854575.8085 1964 | 56480289940.9899 1963 | 48421923459.1235 1962 | 42161481858.0819 1961 | 39232435784.0358 1960 | 37029883876.1839
Table 2: GDP (Nominal Value) in Japan (unit: USD), according to datacatalog.worldbank.org date | GDP (Nominal Value)
2022 | 4232173916086.67 2021 | 5005536736792.29 2020 | 5048789595589.43 2019 | 5117993853016.51 2018 | 5040880939324.86 2017 | 4930837369151.42 2016 | 5003677627544.24 2015 | 4444930651964.18 2014 | 4896994405353.29 2013 | 5212328181166.18 2012 | 6272362996105.03 2011 | 6233147172341.35 2010 | 5759071769013.11 2009 | 5289493117993.89 2008 | 5106679115127.3 2007 | 4579750920354.81 2006 | 4601663122649.92 2005 | 4831467035389.8 2004 | 4893116005656.56 2003 | 4519561645253.53 2002 | 4182846045873.61 2001 | 4374711694090.87 2000 | 4968359075956.59 1999 | 4635982224063.88 1998 | 4098362709531.24 1997 | 4492448605638.94 1996 | 4923391533851.63 1995 | 5545563663889.7 1994 | 4998797547740.97 1993 | 4536940479038.25 1992 | 3980702922117.66 1991 | 3648065760648.88 1990 | 3185904656663.85 1989 | 3109455047823.93 1988 | 3125724434400.79 1987 | 2580748422781.09 1986 | 2120083812109.91 1985 | 1427019759717.41 1984 | 1345824500836.76 1983 | 1270859919742.9 1982 | 1158731426905.85 1981 | 1245221410764.15 1980 | 1129377244854.04 1979 | 1077910077676.37 1978 | 1035611588216.59 1977 | 737069290927.712 1976 | 598883902155.605 1975 | 532861438884.724 1974 | 490035789970.299 1973 | 441460582535.921 1972 | 324933841268.585 1971 | 245364056622.363 1970 | 217223652719.444 1969 | 172204199480.889 1968 | 146601072685.511 1967 | 123781880217.6 1966 | 105628070343.111 1965 | 90950278257.7778 1964 | 81749006381.5111 1963 | 69498131797.3333 1962 | 60723018683.7333 1961 | 53508617739.3778 1960 | 44307342950.4生成AI・LLMのコストでお困りなら
GPUのスペック不足で生成AIの開発が思うように進まないことはありませんか?
そんなときには、高性能なGPUをリーズナブルな価格で使えるGPUクラウドサービスがおすすめです!

GPUSOROBANは、生成AI・LLM向けの高速GPUを業界最安級の料金で使用することができます。
インターネット環境さえあれば、クラウド環境のGPUサーバーをすぐに利用可能です。
大規模な設備投資の必要がなく、煩雑なサーバー管理からも解放されます。







