
NVIDIA H100は、生成AIや大規模言語モデル(LLM)向けに設計された最先端のGPUです。
AIトレーニングと推論を飛躍的に向上させるTensorコアや、NVLinkによる高速データ転送など、H100の特徴を簡単にわかりやすくお伝えします。
この記事では、NVIDIA H100の種類、性能、価格、消費電力などについて詳しく解説します。

NVIDIA H100とは

NVIDIA H100は、AIモデルのトレーニングや推論、シミュレーションを高速に行うために開発された高性能GPUです。
AI技術の進展に伴い、大規模なデータ処理や複雑な計算が必要となる中、NVIDIA H100はそれに対応する強力なGPUとして設計されています。
H100には、NVIDIAが開発したAI開発に特化したTensorコアが実装されています。Tensorコアは行列演算を高速に処理し、AIトレーニングや推論の並列処理性能を大幅に向上させます。
これにより、NVIDIA H100は大規模なAIトレーニングを効率的に行うことができ、AI開発の最前線でその真価を発揮します。

NVIDIA H100の性能

NVIDIA H100の性能と前世代となる第3世代A100との比較について紹介します。
NVIDIA H100の性能
NVIDIA H100は、最新の第4世代Hopper™ アーキテクチャを採用しており、前世代と比較して大幅に性能が向上しています。
特にAIトレーニングや推論において、卓越した計算能力を発揮します。
NVIDIA H100では、次の精度形式がサポートされています。
精度形式とは、数値をコンピュータ内でどのように表現するかを定義する形式です。
H100モデル別の性能比較
| 精度形式 | H100 SXM | H100 PCIe |
| FP64 | 34 teraFLOPS | 26 teraFLOPS |
| FP64 Tensor コア | 67 teraFLOPS | 51 teraFLOPS |
| FP32 | 67 teraFLOPS | 51 teraFLOPS |
| TF32 Tensor コア | 989 teraFLOPS | 756 teraFLOPS |
| BFLOAT16 Tensor コア | 1,979 teraFLOPS | 1,513 teraFLOPS |
| FP16 Tensor コア | 1,979 teraFLOPS | 1,513 teraFLOPS |
| FP8 Tensor コア | 3,958 teraFLOPS | 3,026 teraFLOPS |
| INT8 Tensor コア | 3,958 TOPS | 3,026 TOPS |
NVIDIA H100は、AIトレーニングなどの高精度計算に対応した精度形式をサポートしています。
中でもTF32 TensorコアやBFLOAT16 Tensorコアを使用することで、行列演算の高速化を実現し、AIトレーニングの効率を大幅に向上させます。
第3世代A100とH100の比較
第3世代のAmpereアーキテクチャを搭載したA100とH100の性能の違いに関して紹介します。
最初に結論をお伝えすると、H100はA100に比べ、AI推論で最大30倍、AIトレーニングで最大9倍の性能が向上しています。
AI推論で最大30倍の性能向上
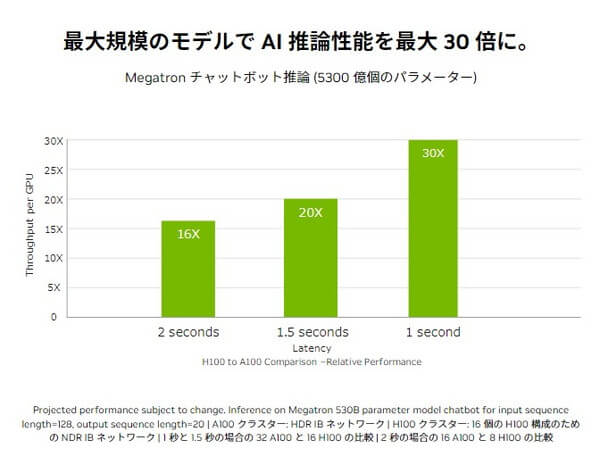
NVIDIAによると、H100はA100に比べてAI推論性能が最大30倍に向上しています。
H100は、第4世代のTensorコアになっており、FP64、TF32、FP32、FP16、INT8の性能が強化されています。
特に、新たにFP8(8ビット浮動小数点)の採用により、AI推論の大幅な性能向上を達成しています。
AIトレーニングで最大9倍の性能向上
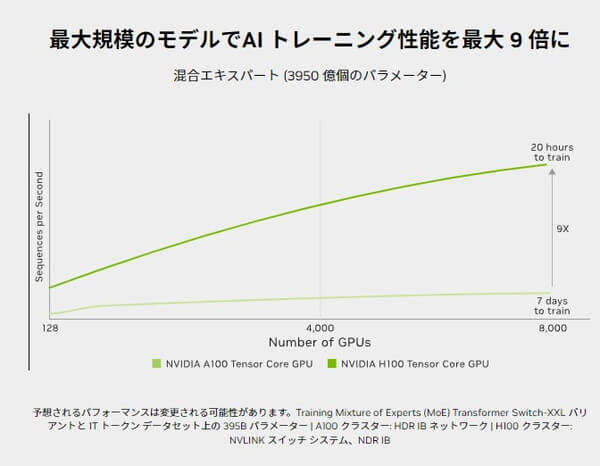
NVIDIA H100は、最新の第4世代TensorコアとFP8精度を活用する「Transformer Engine」を搭載しています。
Transformer Engineは、FP8とFP16の精度を自動的に再構築し、AIパフォーマンスを大幅に向上させます。
これにより、前世代のA100と比べてAIモデルのトレーニング速度が最大9倍速くなります。
約1.64倍のメモリ帯域幅向上
NVIDIA H100は、最新のHBM3 GPUメモリを採用しており、前世代のA100で使用されていたHBM2 GPUメモリと比較して、メモリ帯域幅が約1.64倍向上しています。
具体的には、A100 80GB SXMのメモリ帯域幅は約2.039TB/sであるのに対し、H100 SXMでは最大3.35TB/sに達します。
メモリ帯域幅が広がることで、一度に処理できるデータ量が増加し、全体の通信速度が向上します。
(参考:NVIDIA H100 Tensor コア GPU / NVIDIA A100 Tensor コア GPU)
H100 PCIeとH100 SXMの違い

NVIDIA H100にはPCIe版とSXM版の2種類があります。
それぞれの特徴を簡単に説明します。
NVIDIA H100 PCIe

H100 PCIe(Peripheral Component Interconnect-Express)は、一般的なコンピュータのスロット(PCI Express)に挿入して使います。
PCIeに対応している既存のデバイスに導入しやすく、汎用性が高いのが特徴です。
専用のNVLinkブリッジを使用し、連結したGPUペア間でNVLinkを利用して処理速度を向上させることができます。
NVIDIA H100 SXM

H100 SXM(Scalable Link Interface Cross-Connect Module)は、基本的にH100 GPU8枚セットで構成される専用のサーバーとして提供されます。
上記画像の金色の部分がH100 SXMで、画像では8枚のGPUが連結されています。
SXMはNVLinkを使用し、複数のGPUを効率的に連結して処理速度を向上させるのが特徴です。
NVIDIA H100 SXMがLLMトレーニングに推奨される理由

H100 SXMは、高速データ転送技術である第4世代NVLinkを利用できます。
NVLinkは、NVIDIAが開発した技術で、複数のGPUを直接連結します。
従来の技術では、GPU同士がデータを直接やり取りできず、必ずCPUを経由する必要がありました。
例えば、GPU2が必要とするデータがお隣のGPU1に存在していても、一度CPUを経由しないとデータが転送されてきませんでした。これでは、欲しいデータをすぐ取得できず、計算効率が低下します。
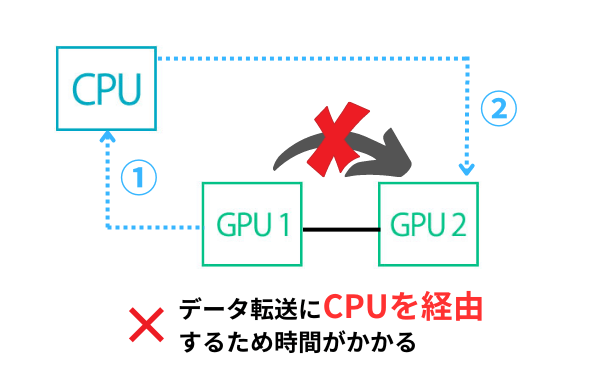
NVLinkはこの状況を解決し、GPU同士が直接データをやり取りできるようにしたのです。これにより、データ転送速度が大幅に向上し、計算効率が圧倒的に上がります。
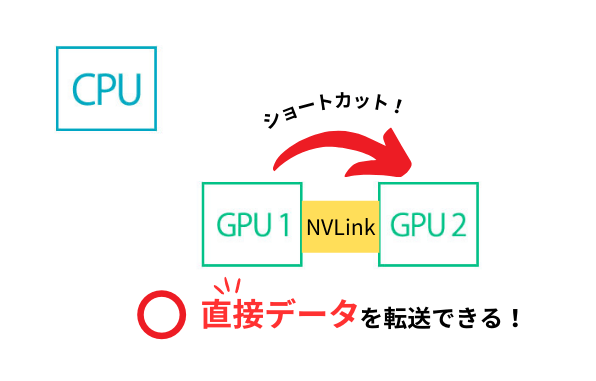
第4世代のNVLinkは第3世代に比べ、GPU間の通信帯域幅が広がり、一度の通信で多くのデータをやり取りできるようになりました。
一方、H100 PCIeもNVLinkを使用できますが、専用のNVLinkブリッジで連結したペア間のみでの使用になります。
このため、H100 PCIeではすべてのGPUを完全に相互接続できず、H100 SXMと比較してデータ転送速度が低下し、拡張性の点で劣ります。
NVIDIA H100 SXMは、NVLinkの利点を活かし、LLMのトレーニングでデータ転送を迅速に行い、全体の作業を遅延させる原因を減らします。
また、複数のH100 SXMを効率的に連結し、最大256個まで連結できる拡張性の高さも魅力です。
以上の理由から、高速かつ拡張性の高いトレーニング環境を提供するH100 SXMは、大規模言語モデル(LLM)や生成AIのトレーニングに最適です。
NVIDIA H100のDGXとHGXの違い

NVIDIAのH100には、DGX H100とHGX H100の2種類があります。
どちらも同じNVIDIAの純正H100 GPUを使用していますが、提供の形態とカスタマイズの柔軟性に違いがあります。
DGX H100
NVIDIAが提供する純正のH100 x 8枚サーバー
HGX H100
NVIDIAのパートナー企業が提供するH100 x 8枚サーバー
DGX H100は、H100 GPUの開発者であるNVIDIA自身がサーバーを組み立てて提供しています。
一方、HGX H100はNVIDIAのパートナー企業がH100 GPUを使ってサーバーを組み立てて提供しています。
どちらもGPUは同じNVIDIA H100(SXM)を利用しているので、基本的には性能に大きな違いはありません。
| 構成 | DGX H100 | HGX H100 |
| GPU | NVIDIA H100(SXM)×8枚 | NVIDIA H100(SXM)×8枚 |
| GPUメモリ | 合計640GB | 合計640GB |
| GPU間通信 | NVLink・NVSwitch | NVLink・NVSwitch |
| vCPU | 112コア | 112コア |
| システムメモリ | 2TB | 2TB |
| ストレージ | 合計 34.56TB | 30TB |
NVIDIA H100の消費電力

NVIDIA H100の消費電力は、高性能を支えなければならないため、非常に高いことが特徴です。
H100 1枚あたりの最大熱設計電力(TDP)は、以下のようになっています。
- PCIe: 300~350W
- SXM: 700W
これに加えて、CPUやメモリなどその他の必要部品の電力消費も含まれます。
前世代のA100の最大熱設計電力は、PCIeで300W、SXMで400Wでした。
H100 SXMは、基本的に8枚で1つのサーバーとして構成されます。NVIDIA公式によると、DGX H100のシステム消費電力は最大10.2kWと発表されています。
このことから、パートナー企業によって提供されるHGX H100の電力も同様に10kW以上と考えられます。
10kWの消費電力は、一般的な電子レンジ約20台分に相当するため、H100サーバーを運用するには、しっかりとした電力供給の準備が必要です。
また、高い消費電力は同時に大量の熱を発生させるため、効率的な冷却システムが不可欠です。
H100の安定した性能を維持し、過熱による故障を防ぐためには空調などの設備強化も必要になります。
(参考:NVIDIA DGX H100)
NVIDIA H100の価格

NVIDIA H100は高性能なGPUであるため、その価格も非常に高く、1枚のH100の価格は500万円以上になります。
したがって、H100 GPU(SXM)を8枚搭載したサーバーの価格は約5,000万円以上となり、非常に高額です。
NTT PC CommunicationsのGPUサーバー見積シミュレーターからH100 SXMサーバーの見積もりができますので、気になる方は試してみてください。
NVIDIA H100を自社で購入する場合、機器本体だけでなく設備投資が必要です。
その上、NVIDIA H100は通常の電力では動かせないため、専用の電気工事や冷却装置、騒音対策などに費用が発生します。
しかし、このように非常に高額なH100は、クラウドサービスで借りることができます。
クラウドサービスで借りた場合の月額は、おおよそ300万円から1,000万円程度となるため、初期費用を抑えて利用してみたいという場合におすすめの方法です。
GPUSOROBANのクラウドサービスでは、H100より高性能なHGX H200を業界最安値で提供していますので、詳しく知りたい方は以下のリンクをご覧ください。
HGX H200が業界最安値で借りれる「GPUSOROBAN」とは

GPUSOROBAN(ジーピーユーソロバン)は、純国産GPUクラウドです。
累計2,000件を越えるご利用実績があり、IT業界、製造業、建設業、大学研究機関まで幅広くご利用いただいています。
AIスパコンクラウドでは、HGX H200を圧倒的な低価格でご利用いただけます。
GPUSOROBANが選ばれる3つの理由
ポイント1
圧倒的な低価格!月額固定料金
HGX H200クラスタを自社で導入する場合、大規模な電源や空調設備、サーバールームなどの設備投資が必要です。
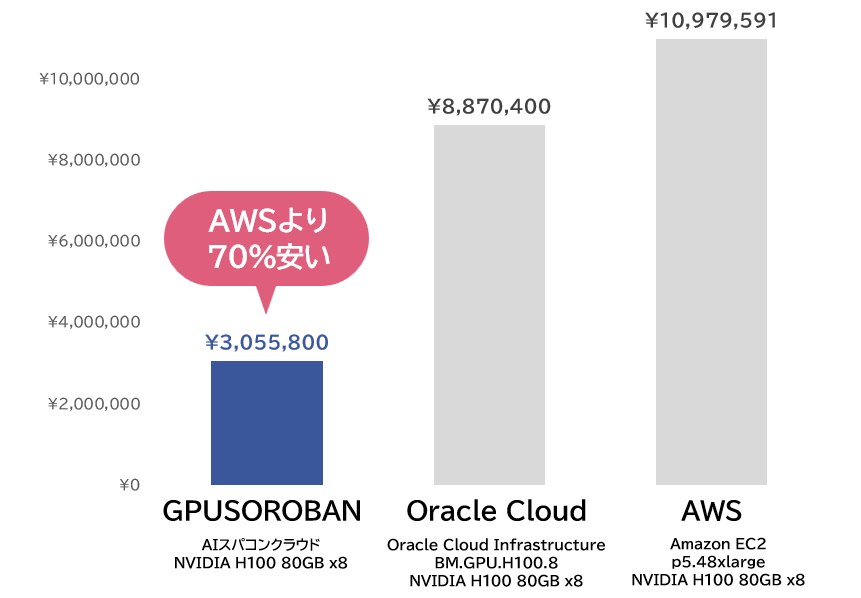
AIスパコンクラウドでは、初期費用が無料で、月額料金のみでHGX H200を利用可能です。
さらに、AWSと比較しても70%安い料金で提供予定です。また、日本円払いのため為替の変動を気にせずに安心して利用できます。
ポイント2
日本語での技術サポートが無料
GPUSOROBANでは、豊富な知識をもった専門スタッフによる日本語での技術サポートを無料で提供しています。
基本的な使い方のレクチャーからGPU動作に関する環境構築まで幅広くサポートします。
さらに、個別カスタマイズ対応も提供しており、安心してご利用いただけます。

ポイント3
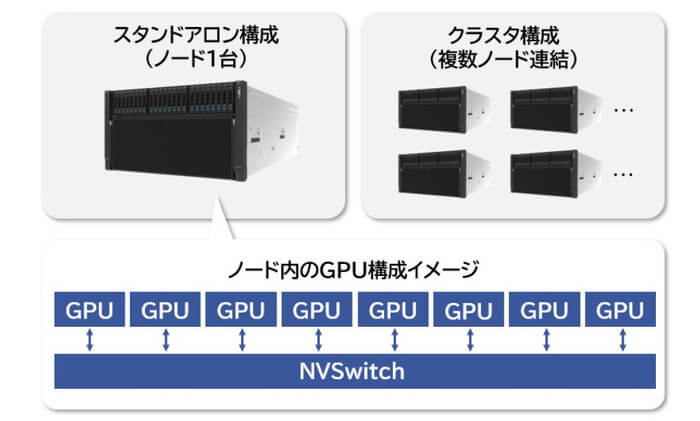
1台からクラスタ構成(複数連結)まで柔軟に対応
GPUSOROBANでは、H200搭載サーバーを1台から利用可能です。
さらに、H200搭載サーバーを連結したクラスタ構成も利用できるため、必要なリソースだけを選んで活用できます。
もちろん、連結にはH200 SXMのパフォーマンスを最大限に引き出すNVLink・NVSwitchを利用しています。
NVIDIA H200の豊富な知識を持ったスタッフが、わかりやすくご説明いたしますのでまずはお気軽にご相談ください。
NVIDIA H100を利用すればトレーニングの効率が大幅にアップ!
NVIDIA H100は、大規模言語モデル(LLM)や生成AI向けに最適化された高性能GPUです。
その卓越した性能により、トレーニングの効率が大幅に向上します。高い価格と消費電力を考慮しても、その性能は多くのメリットを提供します。
GPUSOROBANは、NVIDIA H200を圧倒的な低価格で提供します。
コストを抑えつつ高いパフォーマンスを実現できるため、プロジェクトの成功を強力にサポートします。
NVIDIA H100の豊富な知識を持ったスタッフが、わかりやすくご説明するので安心してご利用いただけます。まずはお気軽にご相談ください。







