
ComfyUIは、ノードベースのインターフェースを採用した最新の生成AIツールです。
この記事では、AI画像生成の初心者や他のツールからの移行を検討しているユーザーに向けて、ComfyUIの始め方を基礎から解説します。

ComfyUIとは?

ComfyUIは、Stable DiffusionなどのAI画像生成モデルを「ノード」と呼ばれる箱を線でつなぐビジュアルプログラミング形式で操作できるオープンソースのGUIツールです。
図のようにモデル読込・プロンプト処理・サンプリング・VAEデコードといった処理単位を自由に組み合わせて独自のワークフローを構築でき、AUTOMATIC1111系の単純なフォーム型UIに比べて以下のような特徴の違いがあります。
ComfyUI と AUTOMATIC1111(A1111)の比較
| 観点 | ComfyUI | A1111 (WebUI) |
|---|---|---|
| UI形式 | ノードベース(グラフ) | フォーム入力型 |
| 柔軟性 | 非常に高い(処理を自在に再構成) | 中程度(拡張機能で追加) |
| 学習コスト | やや高い | 低い |
| 動作の軽さ | 軽量・低VRAMでも動作 | やや重い |
| ワークフロー共有 | JSON / PNG埋め込みで完全再現可能 | プロンプトと設定の共有が中心 |
| 得意分野 | 複雑な制御・SDXL/Flux/動画系・自動化 | 手軽な画像生成・LoRA活用 |
ComfyUIは「画像生成パイプラインを自分で配線して作るビジュアルエディタ」であり、最新モデルへの対応が早いことから、現在は研究者・上級ユーザー・自動化用途を中心に主流のフロントエンドとなっています。
ComfyUIのインストール手順

ここでは、ComfyUIをインストールする手順を詳しく解説します。
今回は、WindowsのローカルPCにインストールする方法と、GPUSOROBAN(Linuxのクラウド環境)にインストールする方法の2つを紹介します。
それぞれの環境に合わせた手順を参考にして、スムーズにComfyUIのセットアップを進めましょう。
WindowsPCにインストールする方法
まずは、GitHubのComfyUI公式ページにアクセスし、必要なデータをダウンロードします。
Windows PCの場合、GPUを搭載しているPC向けと、非搭載のPC向けに分かれているため、自身の環境に適したバージョンを選びましょう。
ページの中部の「Installing」の項目からComfyUIの圧縮ファイルを探します。
「Direct link to download」をクリックすると、データのダウンロードが開始します。
データのダウンロードが完了するまで待ちます。
※ ファイルサイズは約1.3GBと比較的大きいので、安定したインターネット接続環境でのダウンロードをおすすめします。
ダウンロードが完了したらデータを解凍します。
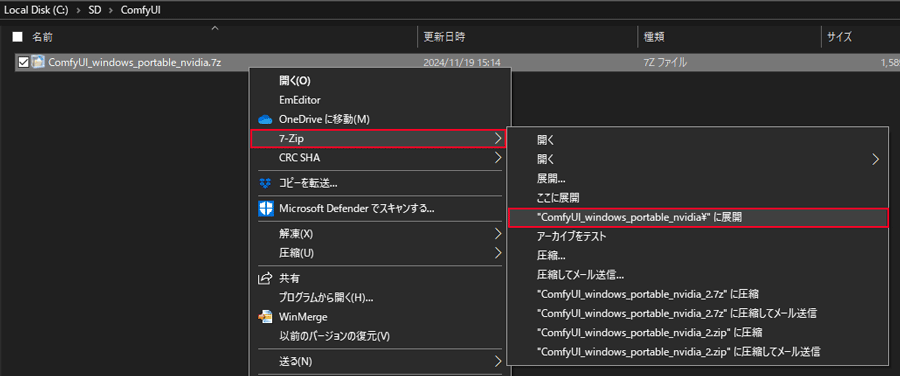
ファイルは 7-zip の形式で圧縮されてますので、専用の圧縮・解凍ソフトの利用がおすすめです。
解凍後の「ComfyUI_windows_portable_nvidia_cu121_or_cpu」フォルダを開きます。この中にある「ComfyUI_windows_portable」がソフトウェアの本体です。
ファイル名が長すぎたり、日本語を含むディレクトリに配置すると、エラーが発生する可能性があります。そのため、シンプルでアクセスしやすい場所に移動することをおすすめします。
例: Cドライブ直下に「SD」というフォルダを作成し、その中に「ComfyUI_windows_portable」を移動。
設置が完了したら「run_nvidia_gpu.bat」をダブルクリックして、ソフトを起動します。
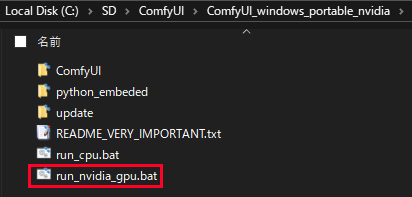
起動後、既定のブラウザが自動で開き、ComfyUIの画面が表示されます。
GPUSOROBANにインストールする方法

ここでは、インターネット上で高性能なGPUを利用できるクラウドサービス「GPUSOROBAN」にComfyUIをインストールする方法を解説します。
まず、GPUSOROBANを利用するために、会員登録からセットアップまでを完了させる必要があります。
詳しい手順については、以下のリンクをご参照してください。
PUSOROBANの会員登録とセットアップ方法
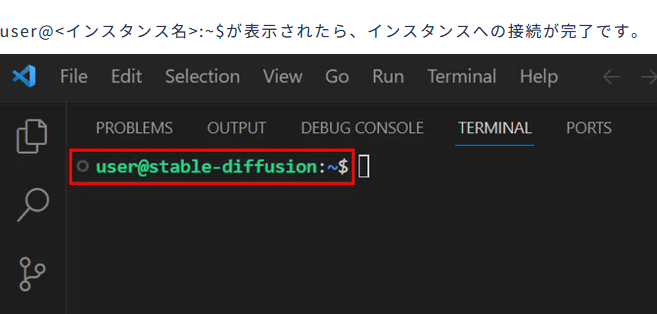
GPUSOROBAN起動チュートリアルに従い、インスタンスの起動とSSH接続を完了させます。
「user@<インスタンス名>:~$」が表示されたら、インスタンスへの接続が正常に完了したことを確認できます。
次に、GPUSOROBANのGPUインスタンス内にComfyUI専用の環境を作成します。
今回はMinicondaのConda環境を使ってComfyUIをセットアップしていきます。
conda create -n comfyui python=3.13
conda activate comfyuiComfyUIの推奨バージョンはpython 3.13ですので、作成する環境に合わせます。
インスタンスを起動した状態でComfyUIをインストールします。
$の後に以下のコマンドを入力します。
git clone https://github.com/comfyanonymous/ComfyUI.git

先ほど構築したComfyUI専用環境に切り替えてComfyUI最新版をインストールします。
conda activate comfyui
cd ComfyUI
pip install -r requirements.txt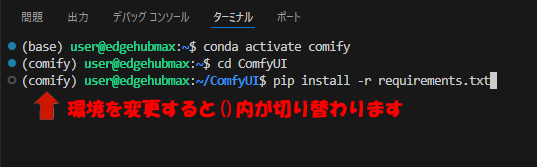
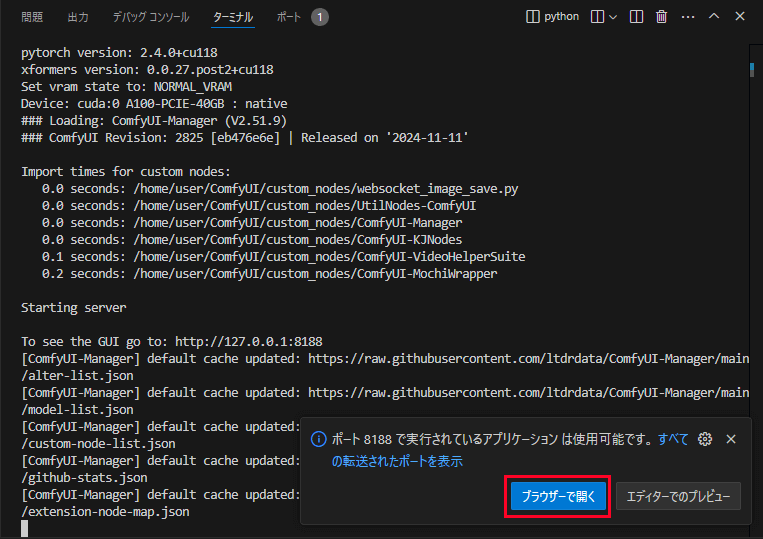
次のコマンドを実行してComfyUIを起動します。
python main.py
デバイス上の割り当てが失敗して起動がうまく行かない場合は–disable-cuda-mallocのオプションを付けて起動します。
python main.py --disable-cuda-malloc
ブラウザで開くボタンをクリックして起動完了になります。

スポンサーリンク
ComfyUIの基本的な画面構成と操作方法

ComfyUIを起動すると、ノードと線で構成された独特な画面が表示されます。
一見複雑に見えますが、基本的な操作は非常にシンプルです。
まずは、基本的な画像生成のワークフローから使い方を見ていきましょう。
ComfyUIを起動すると何もないノード画面が表示されるので、まずは生成に使うワークフローを用意します。
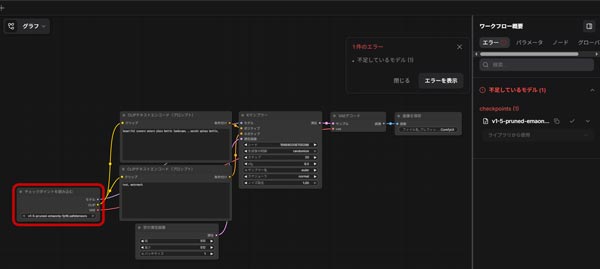
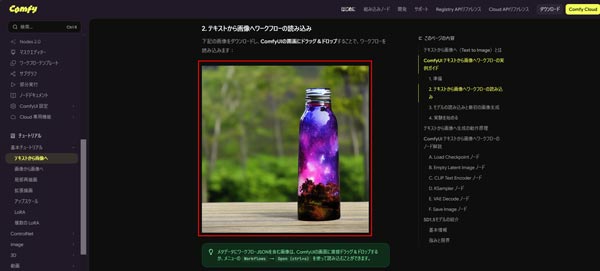
公式が用意しているSD1.5の画像生成ワークフローをDLして使います。
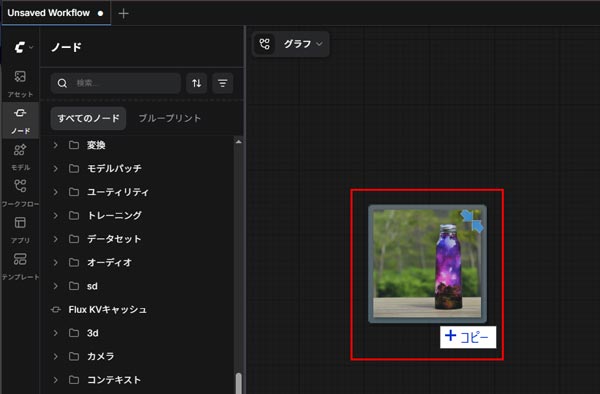
こちらのページの画像をDLしてドラッグ&ドロップでワークフロー内に読み込みます。
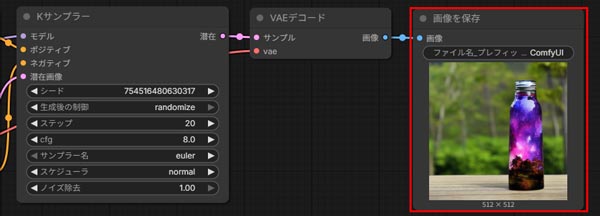
バッチ回数とは、生成したい画像の枚数を指します。
場面上部に▷Queueボタンの右側に数字を入力する欄あるので、そこに生成する画像の枚数を指定します。
数値を入力したらQueueボタンをクリックして画像生成を開始します。
サンプル画像と同じプロンプトで生成された画像がSave Imageに表示されます。

画像を生成するノードの仕組み

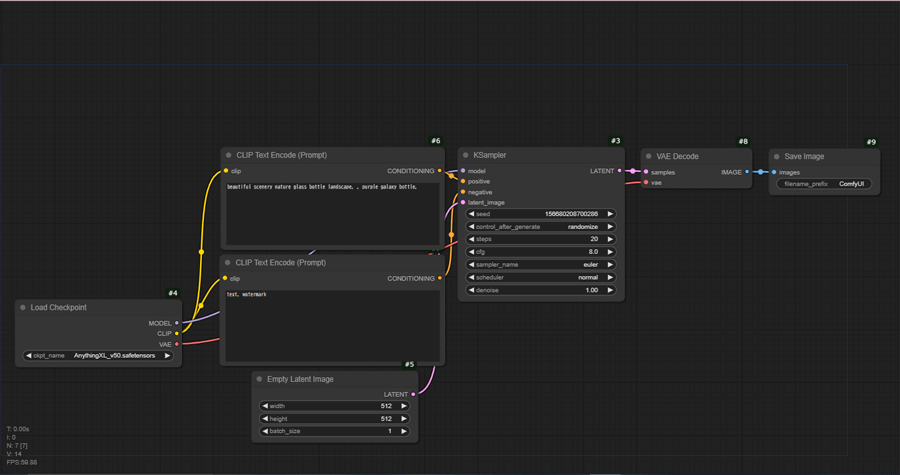
ComfyUIで基本的なテキストから画像を生成するには、最低でも6種類のノードが必要です。
モデルを読み込み、プロンプトを指定し、画像のサイズを決め、サンプリング処理を行い、最後に人間が見える画像形式に変換して保存するという流れを、ノードをつなぎ合わせることで構築します。
モデルを読み込む「Load Checkpoint」ノード
Load Checkpointノードは、画像生成に使うベースモデルを読み込むための、ほぼすべてのワークフローの起点になるノードです。
Stable Diffusionなどのモデルファイルを読み込んで、ワークフロー内で使える形に展開します。
主な入力ポート
| 出力ポート | 役割 | 接続先の例 |
|---|---|---|
| MODEL | U-Net本体。実際のノイズ除去(denoising)を行う画像生成の中核 | KSampler、KSampler (Advanced)、LoRA Loader など |
| CLIP | テキストエンコーダー。プロンプト文字列をモデルが理解できるベクトルに変換 | CLIP Text Encode (Prompt)、CLIP Set Last Layer など |
| VAE | 潜在空間(latent)と実画像(pixel)を相互変換するエンコーダー/デコーダー | VAE Decode(生成結果を画像化)、VAE Encode(img2img用) |
呪文(プロンプト)を入力する「CLIP Text Encode」ノード
CLIP Text Encode (Prompt)ノードは、人間が書いたプロンプト文字列を、モデルが理解できる数値ベクトルに変換するノードです。
Stable Diffusionにおける「呪文を唱える」工程の実体は、このノードでの変換処理になります。
Load Checkpointから出てきた CLIPを使って、入力されたテキストを CONDITIONING という形式に変換します。このCONDITIONINGがKSamplerに渡され、「この方向に画像を生成する」という指示として機能します。
主な入出力ポート
| 区分 | ポート名 | 役割 | 接続元/接続先 |
|---|---|---|---|
| 入力 | clip | テキストをベクトル化するためのテキストエンコーダー | Load CheckpointのCLIP出力から接続 |
| 入力 | text | プロンプト文字列(複数行入力可) | ノード内のテキスト欄に直接入力 |
| 出力 | CONDITIONING | プロンプトを変換した数値ベクトル。生成方向の指示として機能 | KSamplerの positive または negative ポートに接続 |
ポジティブ用とネガティブ用で同じノードを2つ配置して、それぞれKSamplerの対応するポートに繋ぐのが基本構成です。
生成する画像のサイズを決める「Empty Latent Image」ノード
Empty Latent Imageノードは、画像生成の作業キャンバスを用意するノードです。
text2img(テキストから画像生成)ワークフローでは、Load Checkpointと並んで必ず最初に置く起点ノードの一つになります。
Stable Diffusionは、実際のピクセル画像ではなく潜在空間という圧縮された数値空間の中で画像を生成します。このノードは、その潜在空間に「空っぽのキャンバス」を用意する役目を担っています。
このノードでは、モデル別の推奨サイズが重要なポイントになります。
- SD 1.5系
-
512×512が基準。横長なら768×512、縦長なら512×768くらいが安全圏。1024を超えると人物が複数出現したり、構図が崩壊したりします。
- SDXL系
-
1024×1024が基準。他に推奨される解像度として、横長なら1152×896、1216×832、1344×768、縦長ならその逆比率(896×1152など)。SDXLは複数の縦横比で学習されているので、これらの「学習済み解像度」を使うとベストな結果になります。
- SD 2.x系
-
768×768が基準。
- Flux系
-
1024×1024が基準。他に推奨される解像度として、横長なら1152×896、1216×832、1344×768、縦長ならその逆比率(896×1152など)。SDXLは複数の縦横比で学習されているので、これらの「学習済み解像度」を使うとベストな結果になります。
画像生成処理を実行する「KSampler」ノード
KSamplerノードは、ワークフロー全体の心臓部です。
Load Checkpoint・CLIP Text Encode・Empty Latent Imageから集まった全ての要素を受け取り、実際の画像生成処理(ノイズ除去)を実行します。
潜在空間にランダムノイズを乗せ、プロンプトの指示に従って段階的にノイズを取り除いていくことで画像を生成します。これがStable Diffusionの「拡散モデル」の本質的な処理です。
主な入力ポート
| ポート名 | 接続元 | 役割 |
|---|---|---|
| model | Load CheckpointのMODEL | ノイズ除去を行うU-Net本体 |
| positive | CLIP Text Encode(ポジティブ) | 生成したい内容の指示 |
| negative | CLIP Text Encode(ネガティブ) | 避けたい内容の指示 |
| latent_image | Empty Latent Image または VAE Encode | 生成のキャンバスとなる潜在画像 |
主なパラメータ設定
seed — 乱数の種。同じseedなら同じ結果が再現できます。
control_after_generateでfixed(固定)/increment(+1)/randomize(ランダム)を切り替え可能。試行錯誤中はrandomize、気に入った構図を微調整する時はfixedが定番です。steps — ノイズ除去の反復回数。多いほど精緻になりますが、計算時間も比例して増えます。SD1.5なら20〜30、SDXLなら25〜35、Fluxなら20前後が標準。50を超えても劇的な改善はあまりなく、むしろ過処理になることも。
cfg — Classifier-Free Guidance Scale。プロンプトへの忠実度。低いと自由・高いとプロンプトに厳密。SD1.5なら7〜9、SDXLなら5〜8、Fluxなら1〜3.5(Flux系は低CFGが推奨)。高すぎると色が飽和したりコントラストが破綻します。
sampler_name — 最もよく使われるのサンプリングアルゴリズム
euler— シンプルで高速、安定euler_ancestral(euler_a) — 多様性が高く、アニメ系で人気dpmpp_2m— 品質と速度のバランスが良く現代の定番dpmpp_2m_sde— より高品質、ややランダム性ありdpmpp_3m_sde— 最高品質クラス、計算コスト高め
scheduler — ノイズ除去のスケジュール
normal— 標準karras— 滑らかで品質良好、dpmpp_2mとの組み合わせが鉄板exponential— 多様性高めsgm_uniform— Flux系で推奨
denoise — ノイズ除去の強度(0.0〜1.0)。text2imgでは必ず1.0。img2imgでは0.4〜0.7程度にして、元画像をどれだけ残すか調整します。0.0だと元画像そのまま、1.0だと完全に作り直します。
潜在空間から画像に変換する「VAE Decode」ノード
VAE Decodeノードは、KSamplerが生成した潜在空間の画像を、人間が見られるピクセル画像に変換するノードです。
生成パイプラインの最終工程で、これを通さないと画像として表示も保存もできません。
Stable Diffusionは効率化のため、すべての生成処理を潜在空間という圧縮された数値空間で行います。例えば512×512の画像は、潜在空間では64×64×4チャンネルという小さなデータとして扱われています(解像度1/8、チャンネル数4)。
VAE Decodeは、この圧縮された潜在表現を実際のRGBピクセル画像に復元する役割を担います。
主な入力ポート
| ポート名 | 接続元 | 役割 |
|---|---|---|
| samples | KSamplerのLATENT出力 | 復元する潜在画像 |
| vae | Load CheckpointのVAE出力 または Load VAE | 復元に使うVAE |
完成した画像を保存する「Save Image」ノード
Save Imageノードは、生成された画像をPNGファイルとしてディスクに保存する最終出力ノードです。
VAE Decodeから出力されたピクセル画像を受け取り、ComfyUI/output/ フォルダにPNG形式で保存します。
同時に、生成に使ったワークフロー全体の情報をPNGのメタデータに埋め込むため、保存した画像をComfyUI画面にドラッグ&ドロップするだけでワークフローを完全復元することができます。
主な入力ポート
| ポート名 | 接続元 | 役割 |
|---|---|---|
| images | VAE DecodeのIMAGE出力 | 保存する画像 |
基本ワークフロー完成形
これでComfyUIのtext2img最小ワークフローが完成しました:
Load Checkpoint ─┬→ MODEL ────────────────────────────┐
│ │
├→ CLIP ──┬→ CLIP Text Encode (Pos) ──┤
│ │ │
│ └→ CLIP Text Encode (Neg) ──┤
│ ↓
└→ VAE ──────────────────┐ KSampler
│ │
Empty Latent Image ──→ LATENT ────────────┼─────────────┘
│ │
↓ ↓
VAE Decode ←── LATENT
│
↓
Save Imageこれら6種類のノード(Load Checkpoint / CLIP Text Encode ×2 / Empty Latent Image / KSampler / VAE Decode / Save Image)で、ComfyUIの基本的な画像生成は全て完結します。

ComfyUI 入門に関するよくある質問

ここでは、ComfyUIを使い始めるにあたって、多くの人が抱く疑問点について回答します。
推奨されるPCのスペックや、エラーが発生した際の対処法、既存の資産が流用できるかなど、初心者がつまずきやすいポイントをまとめました。
- ComfyUIを快適に使うための推奨PCスペックは?
-
GPUのVRAM容量が最も重要です。 最低でもVRAM8GB、快適な利用を目指すなら12GB以上を搭載したNVIDIA製のGPUが推奨されます。 CPUはCorei5やRyzen5以上、メインメモリは16GB以上あると安定して動作します。
- ノードの接続でエラーが出た場合の基本的な対処法は?
-
エラーが発生すると対象のノードが赤く表示されます。 まずは、ノード間の接続で端子の「型」が一致しているか確認してください。 例えば、MODEL端子にIMAGE端子を接続するなど、異なる種類のデータを繋ぐとエラーになります。 接続を見直すことが最も基本的な対処法です。
- Stable Diffusion WebUI(A1111)で使っていたモデルは流用できますか?
-
はい、流用できます。 Checkpoint、LoRA、VAE、ControlNetモデルなど、A1111で使用していたほとんどのモデルファイルは共通規格です。 ComfyUIの対応する各モデルフォルダにファイルを配置するだけで、そのまま使用することが可能です。
ComfyUIを使いこなしてノードベースのワークフローをマスターしよう!
ComfyUIは、ノードベースのUIにより画像生成のプロセスを視覚的に理解・構築できるツールです。
最初は戸惑うかもしれませんが、基本的なワークフローを一度構築すれば、その自由度の高さを実感できます。
ComfyUIで高画質の動画を生成するには、高スペックなパソコンが必要です。
ただし、ComfyUIを快適に利用できるような高性能なパソコンは、ほとんどが30万円以上と高額になります。
コストを抑えたい方へ:クラウドGPUの利用がおすすめ
クラウドGPUとは、インターネット上で高性能なパソコンを借りることができるサービスです。これにより、最新の高性能GPUを手軽に利用することができます。
クラウドGPUのメリット
- コスト削減:高額なGPUを購入する必要がなく、使った分だけ支払い
- 高性能:最新の高性能GPUを利用できるため、高品質な画像生成が可能
- 柔軟性:必要なときに必要なだけ使えるので便利






