
Stability AIは、2024年10月22日に最新の画像生成AIモデル「Stable Diffusion 3.5」をリリースしました。
Stable Diffusion 3.5とは、Stable Diffusionの最新ベースモデルです。
この記事では、「Stable Diffusion 3.5」ローカル環境の使い方を初心者向けに詳しく解説します。

Stable Diffusion 3.5とは?

Stable Diffusion 3.5は、前バージョン「Stable Diffusion 3」からのフィードバックを基にバージョンアップされた、最新の画像生成AIモデルです。
Stable Diffusion 3.5の大きな特徴は、下記の3つです。
- ファインチューニングやアプリケーションの構築を手助けする「カスタマイズ性」
- ハードウェアで高負荷をかけずに実行できる「効率的なパフォーマンス」
- 広範な指示を必要としない「多様なスタイルと出力」
カスタマイズ性

Stable Diffusion 3.5は、高いカスタマイズ性と使いやすさを兼ね備えており、クリエイティブなニーズに応じた柔軟な対応が可能です。
モデルを簡単にファインチューニングしたり、カスタムワークフローに基づくアプリケーションを構築できたりします。
また、ファインチューニングやLoRAを利用した最適化、アプリケーション開発、アートワークの作成に加え、パイプライン全体の作業を効率化し、成果物の配布や収益化を容易にする設計が施されています。
効率的なパフォーマンス
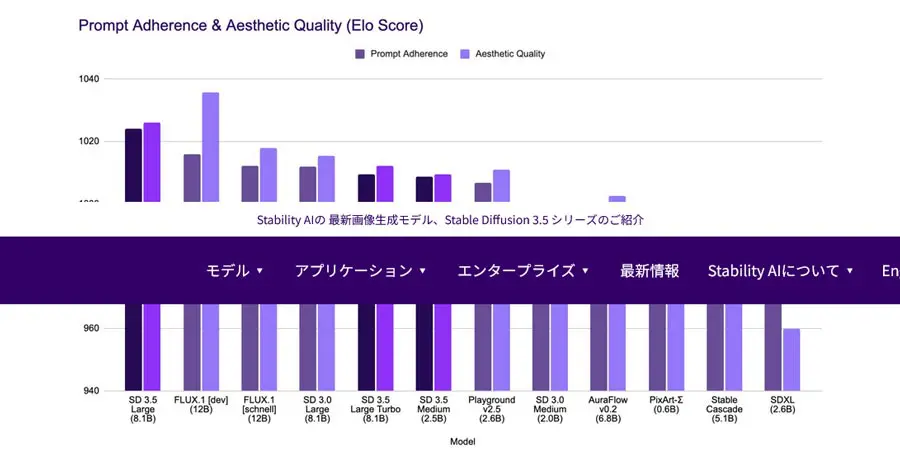
Stable Diffusion 3.5では、トレーニング方法が改良され、カスタマイズのしやすさと画質をバランスよく出力できるようになりました。
他の画像生成AIモデルとの比較において、プロンプト順守率(Prompt Adherence)と美的クオリティ(Aesthetic Queality)のスコアは、これまでのStable Diffusionシリーズを上回っています。
多様なスタイルと出力

3D画像や写真、絵画、線画など、幅広いスタイルをサポートし、多様なキャラクターを生成できます。
カスタマイズ性を優先した結果、同じプロンプトを使用してもシードによって多様な出力が得られるため、クリエイティブな表現の幅が広がります。
特に、特定の指示がないプロンプトでも予測できないユニークな結果が生成され、より個性的な作品が生まれる可能性が高まります。


Stable Diffusionの使い方は、機能別に下記の記事にまとめているのでぜひご覧ください

Stable Diffusion 3.5 ComfyUIでの始め方・使い方

ここでは、「ComfyUI」上でのStable Diffusion 3.5の始め方から使い方まで紹介します。
Stable Diffusion 3.5は、従来のモデルよりも多くの容量が必要になりますので、余裕をもって準備をしておきましょう。
まずは「ComfyUI」を最新版に更新して、起動します。
Stable Diffusion 3.5が搭載された学習モデルのデータをHugging Faceからダウンロードしてセットします。
「ComfyUI」での生成に使用するファイルは下記の4つです。
各クリップファイルは、Stable Diffusion 3やFLUX.1で利用したものと同じなので流用できます。
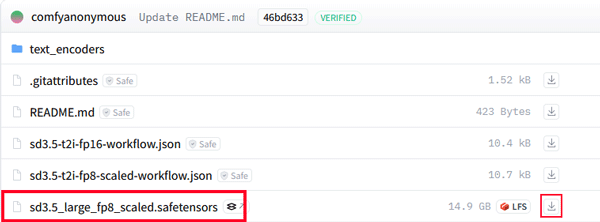
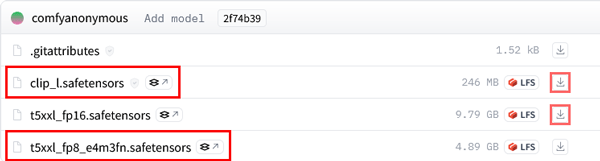
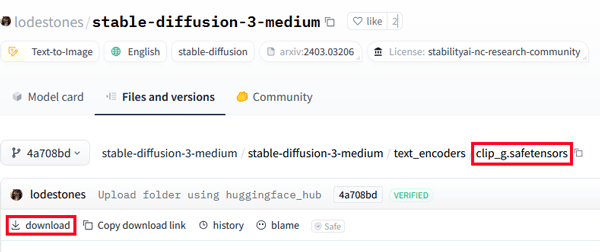
ダウンロードしたデータをフォルダにセットします。
ComfyUIを「models」>「checkpoints」の順で開き、先ほどダウンロードした「stable-diffusion-3.5-fp8」を配置します。
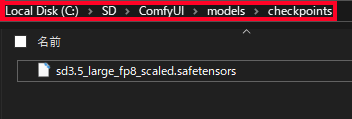
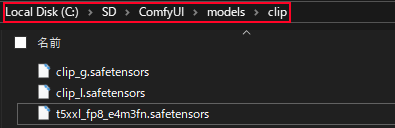
続いて「models」>「clip」の順で開き、先ほどダウンロードした「t5xxl_fp8_e4m3fn.safetensors 」、「clip_l.safetensors」、「clip_g.safetensors」を配置します。
データのセットが完了したらComfyUIを起動してStable Diffusion 3.5用のワークフローをセットします。
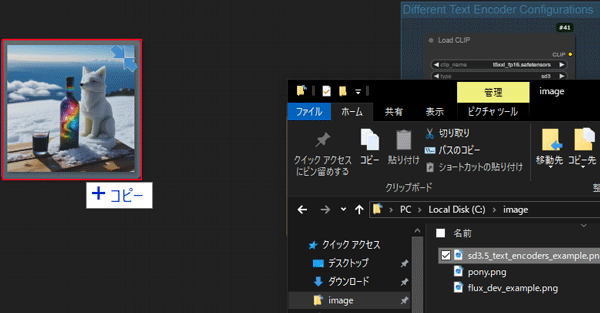
ワークフローをコピーするために公式サイトからデモ画像をダウンロードします。

ダウンロードした画像をComfyUIの画面にドラッグ&ドロップで画像を読み込むと埋め込まれているワークフローデータを表示することができます。
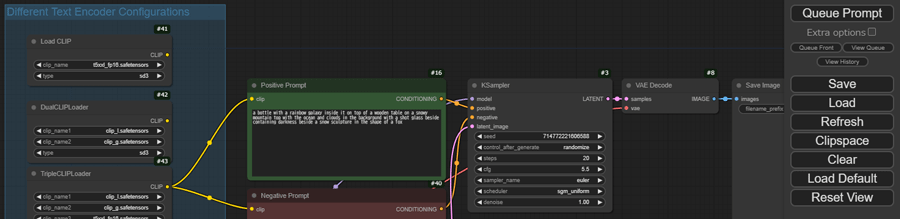
ComfyUIの生成開始画面で、各種パラメータを変更していきます。
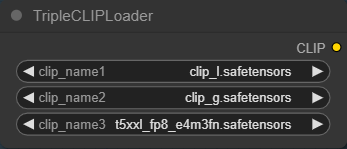
TripleCLIPローダー
・clip_name1に「clip_l.safetensors」を選択します
・clip_name2に「clip_g.safetensors」を選択します
・clip_name3に「t5xxl_fp8_e4m3fn.safetensors」を選択します
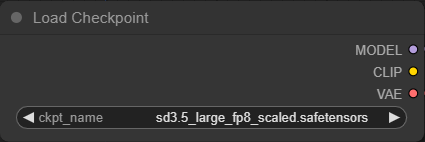
Load Checkpoint
・ckpt_nameに「sd3.5_large_fp8_scaled.safetensors」を選択します。
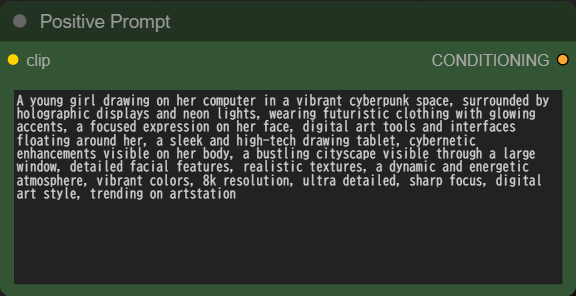
CLIPテキストエンコーダー
・プロンプトを入力します。
※ネガティブプロンプトは入力しません。
画像サイズはデフォルトの1024×1024、その他のパラメータはデフォルトのまま生成を開始します。
生成は右上の「Queue Prompt」ボタンをクリックします。
A young girl drawing on her computer in a vibrant cyberpunk space, surrounded by holographic displays and neon lights, wearing futuristic clothing with glowing accents, a focused expression on her face, digital art tools and interfaces floating around her, a sleek and high-tech drawing tablet, cybernetic enhancements visible on her body, a bustling cityscape visible through a large window, detailed facial features, realistic textures, a dynamic and energetic atmosphere, vibrant colors, 8k resolution, ultra detailed, sharp focus, digital art style, trending on artstation
Stable Diffusion 3.5(ComfyUI)で生成した画像


スポンサーリンク
Stable Diffusion 3.5の料金プランと商用利用は?

Stable Diffusion 3.5の料金プランと商用利用に関して紹介します。
Stable Diffusion 3.5の料金プラン
Stability AIが公開した3つのモデル「Stable Diffusion 3.5 Large」、「Stable Diffusion 3.5 Large Turbo」、「Stable Diffusion 3.5 Medium」は、Comfy UIなどでローカル利用する場合は無料で利用ができます。
Stable Diffusion 3.5が利用できるプラットフォームでは、各サイトで料金が発生する場合があります。
- Stability AI API
- Replicate
- DeepInfra
- ComfyUI
- Hugging Face
Stable Diffusion 3.5の商用利用は?
Stable Diffusion 3.5の商用利用には制限が設けられています。
Stability AIのコミュニティライセンスによると年間収入が100万ドル未満の個人や組織は研究用、非商用利用、商用利用が可能になります。
年間収入が100万ドルを超える場合は、Stability AIからエンタープライズライセンスの取得が必要になります。
コミュニティライセンスの概要は以下の通りです。
| 目的 | 料金 | 商用利用 | 備考 |
|---|---|---|---|
| 非営利目的 | 無料 | 可 | – |
| 商用利用 | 無料(年間収益100万ドルまで) | 可 | 100万ドル以上の企業は、エンタープライズライセンスの問い合わせが必要 |

Stable Diffusion 3.5を使いこなして生成AIをマスターしよう!
今回は、Stability AIが公開したStable Diffusionの最新モデル「Stable Diffusion 3.5」の使い方について紹介しました。
Stable Diffusion 3.5は、従来の画像生成サービスと比較して、最もクオリティが高い画像を生成することができます!
無料で利用できる画像生成AIサービスの中でトップクラスなので、このチャンスに高性能ツールで画像生成を極めてみましょう。








